对象
对象
请描述一下Java对象的内存结构,以及如何统计对象大小?
在平时的开发中,在项目上线之前,我们需要合理的预估项目运行所需的内存空间,以便合理地设置JVM内存的大小。JVM内存分为很多部分:栈内存、堆内存、方法区等,栈内存中存储的数据的生命周期很短,函数结束之后就释放了。方法区存储的是代码,几乎是固定不变的,而且占用的空间也比较少。所以,分析的重点就成了堆内存。堆内存中主要存储对象。 所以,想要合理估算项目运行所需的内存空间,就需要知道如何计算一个对象所占内存的大小。本节,我们就来讲一讲,Java对象在内存中的存储结构,以及如何统计对象大小。
一、整体结构
Java对象在内存中的存储结构包含三部分:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。其中,对象头又包含标记字(Mark Word)、类指针和数组长度。实例数据为对象中的非静态成员变量。对齐填充是为了保证对象存储地址按照8字节对齐(64位JVM)或4字节对齐(32位JVM)而做的填充。如下图所示。
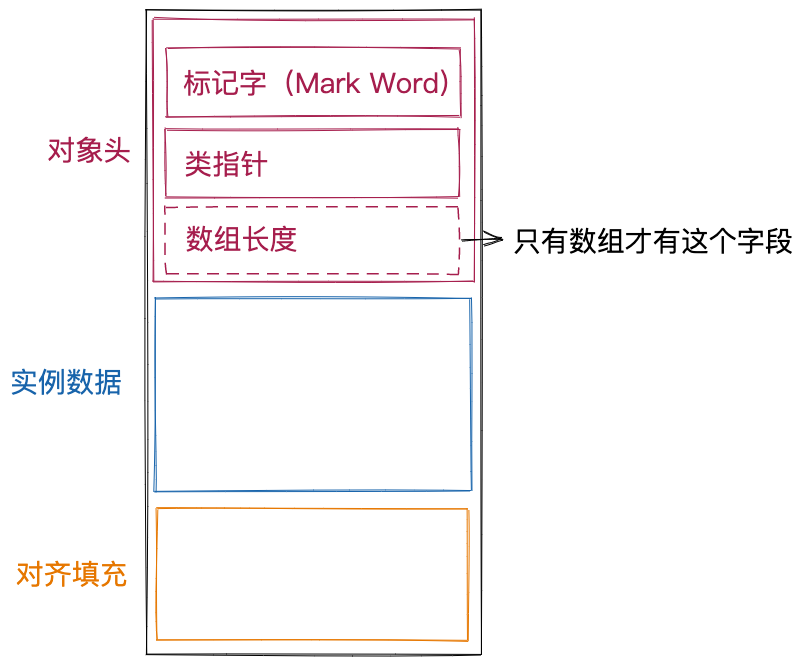
对于对象的内存结构,我们可以使用JOL(Java Object Layout)工具来查看。在接下来的讲解中,我们也会反复用到这个工具。它的使用非常简单。跟引入其他类库一样,我们可以通过Maven或Gradle将其引入自己的项目中,如下所示。
// Maven
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.16</version>
<scope>provided</scope>
</dependency>
// Gradle
compileOnly 'org.openjdk.jol:jol-core:0.16'
在项目中,我们需要编程来查看某个对象的存储结构。如下示例代码所示。
// MyObject.java
public class MyObject {
private long b;
private int a;
private Integer e;
private static final int s = 1;
public void f() {}
//...省略方法...
}
// Demo9_1.java
import org.openjdk.jol.info.ClassLayout;
public class Demo9_1 {
public static void main(String[] args) {
System.out.println(
ClassLayout.parseInstance(new MyObject()).toPrintable());
}
}
MyObject类的对象的内存存储结构,经过上面的代码,打印出来如下所示。
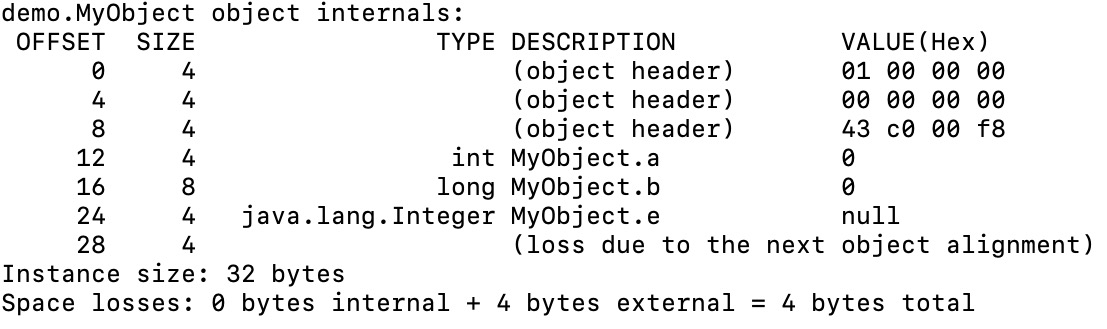
对于上图中的内容,我们简单介绍一下。
1)OFFSET表示字段相对于对象的首地址的偏移地址,单位是字节。
2)SIZE表示字段的大小,单位是字节。
3)TYPE表示字段的类型。
4)VALUE为字段值。
上图中的其他信息,比如space losses,我们在后面慢慢讲解。接下来,我们依次详细讲解对象头、实例数据、对齐填充这部分。
二、对象头
对象头又分为三部分:标记字(Mark Word)、类指针和数组长度。
1)标记字
标记字在32位JVM中占4字节长度,在64位JVM中占8字节长度,其存储对象在运行过程中的一些信息,比如GC分代年龄(age)、锁标志位(lock)、是否偏向锁(biased_lock)、线程ID(thread)、时间戳(epoch)、哈希值(hashcode)等。标记字应该是Java对象存储结构中最复杂的部分。标记字记录的大部分信息,都用于多线程和JVM垃圾回收。关于标记字的具体存储结构和作用,我们在多线程和JVM模块中详细讲解。
2)类指针
对象所属的类的信息存储在方法区,为了知道某个对象的类信息,对象头中存储了类指针,指向方法区中的类信息,也就是对应类信息在方法区中的内存地址。关于类在内存中的存储结构,我们在后面的章节中讲解。
不过,这里我有一个小问题,为啥叫“类指针”,而不是“类引用”呢?毕竟,Java中并没有指针,存储内存地址的是引用。实际上,这里的指针是指C++指针,因为JVM是用C++语言实现的,对象的存储结构、类的存储结构都是由C++代码来定义的。
3)数组长度
在JVM实现数组时,JVM将数组作为一种特殊的对象来看待,其内存存储结构跟普通对象几乎一样。唯一的区别是,数组的对象头中多了数组长度这样一个字段。在32位JVM和64位JVM中,此字段均占4字节长度。从而,我们也可以得知,在Java中,可以申请的数组的最大长度为2^32-1。
三、实例数据
实例数据存储的是对象里的非静态成员变量,可以是基本类型,也可以是引用类型。因为静态成员变量属于类,而非对象,所以,静态成员变量并非存储在对象中,具体存储的位置,我们在后面的章节中讲解。在64位JVM中,各个类型的字节长度如下所示。
| 类型 | 字节大小 |
|---|---|
| double | 8 |
| long | 8 |
| float | 4 |
| int | 4 |
| short | 2 |
| char | 2 |
| byte | 1 |
| boolean | 1 |
| 引用 | 8 |
在内存,每个属性存储的内存地址,必须是自身字节长度的倍数。比如,long型、int型、char型属性的内存地址必须分别是8、4、2的倍数,如果不是,需要补齐。这样的存储要求叫做“字节对齐”,补齐的方法叫做“字节填充”。
除了属性对齐填充之外,对象整体也要对齐填充。对象整体按照8字节对齐,不足8字节的,在对象末尾补足8字节。这样每个对象都是从8的倍数的地址开始存储。为什么要字节对齐和字节填充,我们在下一小节「对齐填充」中讲解。
对象中的属性并非按照定义的先后顺序来存储的。有了字节对齐和对齐填充,对于对象中的各个属性,以不同的顺序来存储,占用内存大小会不同。如下示例所示。
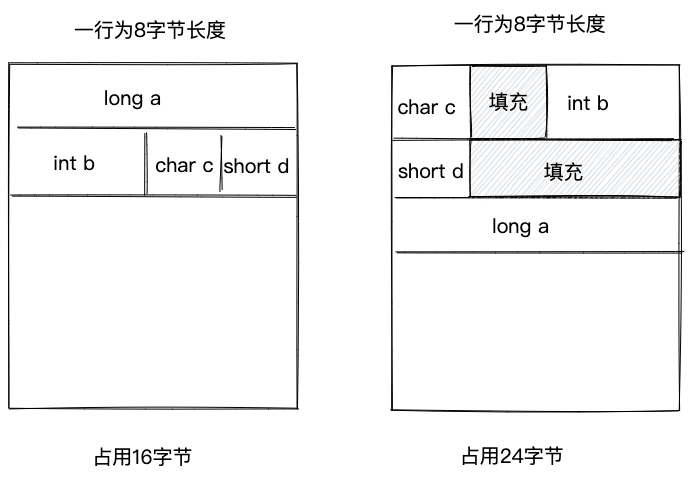
为了尽量减少内存占用,JVM采用如下规则来安排字段的存储顺序。以下规则不需要记忆,只需要理解,在必要的时候,能够参照规则给出正确的内存排布即可。
**1)规则一:**先存储父类的属性,再存储子类的属性。
**2)规则二:**类中的属性默认按照如下先后顺序来存储:double/long、float/int、short/char、byte/boolean、object reference。此顺序受JVM参数-XX:FieldsAllocationStyle影响,不过此参数在高版本JDK中被废弃,以上默认排序方式就是最优排序方式。
**3)规则三:**任何属性的存储地址都是按照类型的字节长度,进行字节对齐和填充,比如,long类型的属性的存储地址按8字节对齐,不足的补齐。对象整体按照8字节对齐和填充。
**4)规则四:**父类的属性和子类的属性之间4字节对齐,不足4字节的补齐4字节。
**5)规则五:**在应用规则4之后,父类的属性和子类的属性之间仍有间隙(子类有8字节属性,所以,父类的属性和子类的属性之间要填充4字节,才能8字节对齐),我们将子类属性按照float/int、short/char、byte/boolean、object reference的顺序,依次拿来填充间隙,直到间隙填充满或无法继续填充为止。同理,如果在对象头和类的属性之间有间隙,我们同样应用此条规则进行填充。此规则受JVM参数-XX:CompactFields的影响,默认为true。如果我们将-XX:CompactFields参数设置为false,此条规则将不再使用。
关于以上规则,我们举例来解释一下。示例代码如下。
public class A {
private char a;
private long b;
private float c;
//...省略方法...
}
public class B extends A {
private boolean a;
private char b;
private long c;
private String d = "abc";
//...省略方法...
}
public class Demo9_1 {
public static void main(String[] args) {
System.out.println(
ClassLayout.parseInstance(new B()).toPrintable());
}
}
上述代码B类的对象的内存结构,使用JOL打印出来,如下所示。这里特别说明一下,JVM开启了指针压缩,所以,本应该占8字节的类指针和引用类型属性,现在只占4字节。关于指针压缩,稍后会详细讲解。
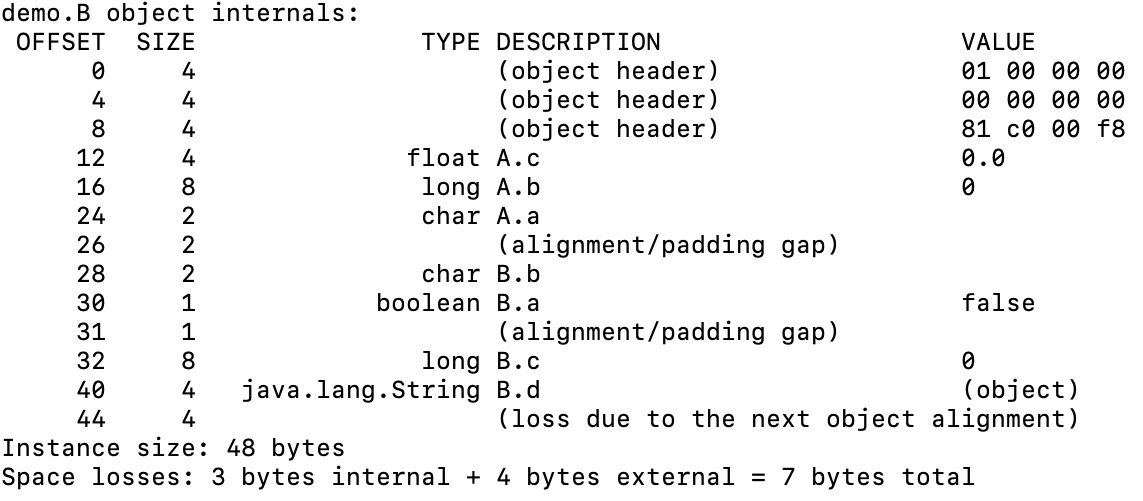
我们结合规则,分析一下JOL打印出来的内存结构。
按照规则一,先存储类A的属性,后存储类B的属性。按照规则二,类A中属性的存储顺序为:b、c、a,但对象头和类A的属性之间会有间隙,所以,附加应用规则五,将属性c提前来填充间隙。根据规则四,类A的属性和类B的属性之间不满足4字节对齐,所以,补齐了2字节填充。根据规则二,类B中的属性的存储顺序为:c、b、a、d,但这样类A的属性和类B的属性之间就会有4字节间隙,所以,附加应用规则五,把属性b、a提前来填充间隙。不过,填充之后,仍然有1字节间隙,所以,在存储long类型的c之前,需要对齐填充。最后,整个对象需要8字节对齐,所以,在对象末尾填充4字节。整个对象总共占用48个字节,其中包括7字节的填充,也就是上图中的Space losses。
四、对齐填充
前面频繁提到字节对齐和对齐填充,现在,我们就来看下,为什么要进行字节对齐和对齐填充?
这是因为CPU按照字(Word)为单位从内存中读取数据,对于64位的CPU,字的大小为8字节,也就是说,内存以8字节为单位,切分为很多块,CPU每次读取一块内存。接下来,我们按照64位CPU和64位JVM来讲解。
对于长度为8字节的long、double、引用类型数据,为了能一次性将其从内存中读入CPU缓存,必须将其存储在划分好的一个8字节内存块中。如果不做内存对齐,一个数据有可能横跨两个内存块。这样,CPU就进行两次读取,才能将数据加载到CPU缓存中,读取之后,还需要从两个内存块中拼接出我们需要的数据。这样效率低,并且不能保证数据访问(读写)的原子性。如下图所示。
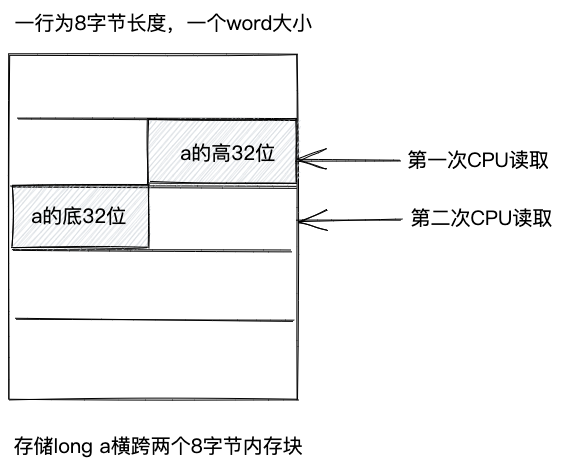
对于长度小于8字节的数据类型,比如float、int、short、char、byte、boolean,为了让它们能一次性从内存读取到CPU缓存,只需要按照类型长度对齐即可,并不需要8字节对齐。
对于对象,因为其Mark Word占8个字节,为了能做到8字节对齐,对于大小不是8的整数的对象,JVM在对象的末尾对齐填充,补齐8字节。
实际上,对于对象中的属性,除了以上对齐方式之外,对于特别注重执行效率的项目,比如Disruptor,为了避免CPU缓存的“伪共享(false sharing)”,程序员会手动进行64字节或128字节对齐,如下所示,“伪共享”属于多线程部分的知识点,我们在多线程模块中讲解。
//针对大小为64字节的缓存行,保证属性a、b各自独占一个缓存行
public class DemoFalseSharing {
long p1,p2,p3,p4,p5,p6,p7; //对齐填充
volatile long a;
long p9,p10,p11,p12,p13,p14,p15; //对齐填充
volatile long b;
}
五、压缩类指针和引用
在上述JOL打印的结果中,我们发现,类指针、引用类型为4字节大小,而非8字节大小。这是因为JVM默认开启了类指针压缩(-XX:+UseCompressedClassPointers参数)和引用压缩(-XX:+UseCompressedOops参数)。当然,我们也可以通过设置JVM参数-XX:-UseCompressedClassPointers和-XX:-UseCompressedOops,将类指针压缩和引用压缩关闭。注意,在JDK8中,类指针压缩开启的前提是引用压缩也已开启。
**那么,如何把8字节的地址压缩为4字节呢?**类指针的压缩方式跟引用的压缩方式相似,我们拿引用类型举例解释。
压缩之后的引用类型属性只占4字节,引用类型属性中存储的是对象的内存地址,4字节可以寻址的内存大小为2^32个字节(一个字节一个地址),也就是4GB。如果设置的堆大小超过4GB,显然,有些对象的地址就无法在引用类型属性中存储了。
但是,前面讲到对齐填充时,对象是按照8字节对齐的,也即是说,对象的首地址是8的倍数,表示成二进制之后,后三位二进制位均为0。引用类型属性存储的是对象的首地址,既然后三位都为0,那也就没必要存储了。这样,32位二进制可以存储长度为35个二进制位的地址(后三位不存)。因此,4字节的引用类型可以寻址的内存空间大小变成了2^35个字节,也就是32GB。当我们要读取引用类型属性所引用的对象时,先从引用类型属性中读取压缩之后的对象首地址,然后左移3位,得到真正的对象首地址,再访问相应的内存块获取对象。
不过,如果我们设置的JVM堆内存大小超过32GB,即便设置了开启引用压缩,引用压缩也不会生效。我们怎么才能突破32GB这个限制呢?
我们想下,之所以能用4字节寻址32GB的内存空间,主要是因为对象按照8字节对齐,如果我们让对象按照16字节对齐,那么对象的内存地址末尾的4位二进制位都为0,这样我们就可以用32位二进制存储长度为36个二进制位的地址。4字节引用类型能寻址的内存空间大小变成了个字节,也就是64GB。如果想继续扩大寻址范围,我们只需要调大对象的对齐长度即可。
我们可以使用-XX:ObjectAlignmentInBytes参数配置对象的对齐长度,参数取值范围为[8, 256],并且必须为2的幂次方(2^n形式)。在支持引用压缩的前提下,最大可设置的堆大小的计算公式为如下所示。例如,当对象对齐为 32个字节时,通过压缩指针最多可以使用 128GB 的堆空间。
4GB * ObjectAlignmentInBytes
那么,为什么要压缩引用和类指针呢?
在编程开发时,我们会频繁地使用引用类型。在64位JVM中,引用类型占用8字节,如果将其压缩至4字节,将大大节省存储空间。很多程序在32位JVM中运行正常,迁移至64位JVM中,设置了更大的堆空间,反倒执行的更慢了。究其原因就是,引用类型大小在64位JVM中是32位JVM中的2倍。同样的对象,在内存中,占用更多的空间,更加容易触发频繁GC。所以,就表现为整个程序更慢了。
在前面章节中讲到,Java之所以在有Integer等包装类的情况下,仍然引入int等基本类型,其中一个重要原因就是节省内存。现在,我们就可以更加准确的分析一下,到底节省了多少内存。一个int数据占据4字节内存,一个Integer对象,对象头占据8(Mark Word)+4(类指针)=12个字节,然后加上仅有的int类型属性,总共占据16字节。对比来看,一个Integer类对象所占内存大小,是int型数据所占内存大小的4倍。如果在项目中大量使用数值,那么使用基本类型变量来表示,就比包装类对象,节省大量内存空间了。
六、课后思考题
计算一个D类对象所占用的总内存空间大小。
public class A {
private char a;
private long b;
private float c;
private static final int d = 1;
//...省略方法...
}
public class C {
private int a;
private char b;
private A c;
private double d;
//...省略方法...
}
public class D extends C {
private boolean a;
private long b;
private char c;
//...省略方法...
}