字符
字符
为何C/C++中char占1个字节,而Java中char占2个字节?
字符、字符串是编程语言中必不可少的语法,Java和C/C++都用char来存储字符,用char数组(char[])来存储字符串,当然,在Java中,存储字符串还可以使用String类,这个下节再讲。在处理字符、字符串时,绝大多数程序员都遇到过乱码问题。因为对底层原理掌握不牢,很多程序员面对乱码手足无措,乱改瞎试。所以,本节我们就详细讲讲字符和字符编码。在开始之前,我们还是留一个思考题给你:为什么C/C++中char类型占1个字节长度,而Java中的char类型占2个字节长度。
一、字符、字符集和字符编码
字符、字符集和字符编码是我们常常一块听到的几个词语,很多人对这几个词语的区别,特别是字符集和字符编码的区别,不是很清楚。接下来,我们就先介绍一下它们。
字符(Character)可以理解为书面表达中所可能用到的符号,包括各种文字、数字、标点、图形符号、控制符号(如回车换行等,待会会讲)等。
字符集(Character Set)是一组字符的集合。不同语言会有不同的字符集,比如,GB2312就是中文字符集,包含6000多个简化汉字和一些符号、序号、数字、字母、拼音等共7000多个字符,涵盖了中文书面表达所需的大部分字符。字符集不仅包含字符,还包含每个字符的编号。这里的编号只是方便索引,跟字符编码不是一回事。
字符编码(Character Encoding)是指计算机存储字符编号的格式。大部分情况下,在设计字符集时,会同步设计字符编码,一个字符集会对应一种字符编码,比如,GB32312字符集对应GB2312字符编码。不过,也有例外,同一个字符集也可以对应多种不同的字符编码,比如,Unicode字符集对应UTF-8、UTF-16、UTF-32三种不同的字符编码。
二、常见字符集和字符编码
比较常用的字符集有ASCII、GB2312、GBK、GB18030、Unicode。其中,前三个的字符集跟字符编码同名,也即是字符集和字符编码是一一对应的。Unicode字符集对应的字符编码有三种,分别是UTF-8、UTF-16、UTF-32。接下来,我们就详细介绍一下这几种常用的字符集和字符编码。
1)ASCII字符集和字符编码
ASCII全称为American Standard Code for Information Interchange,中文翻译为:美国信息交换标准代码。从名称上也可以看出,这套字符集和字符编码是美国人设计的,主要包含了英文系统的计算机所用到的字符。
ASCII字符集只包含128个字符,对应的编号如下图所示。因为只有128个字符,所以,ASCII字符编码很简单,使用1个字节中的低7位来存储编号,最高位默认为0。
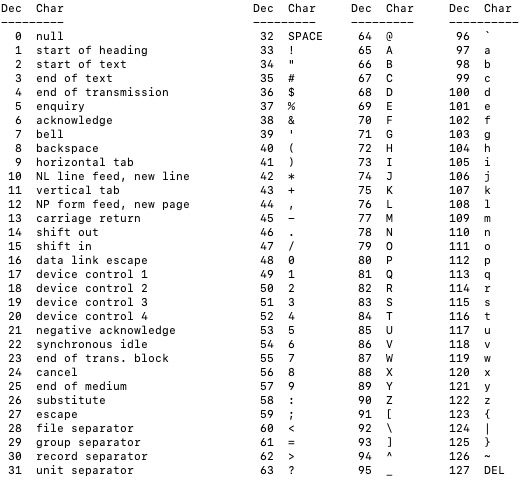
从上图中,我们可以看出,ASCII字符集中的字符分为两类:不可显示字符和可显示字符。编号0~31和127对应的字符为不可显示字符,编号32~126对应的字符为可显示字符。不可显示字符也叫做控制字符。当在一个字符串中包含一些控制字符时,控制字符并不会显示在计算机屏幕上,而是控制输出格式。比如常用的控制字符有回车符(ASCII码值为13)、换行符(ASCII码值为10)。
在字符串中存储可显示字符比较简单,但如何存储非可显示字符呢?
我们可以使用\xxx的格式来表示非可显示字符,其中,xxx为非可显示字符的ASCII码的八进制表示。当然,对于可显示字符,我们也可以用这种方式来表示。示例代码如下所示。
char visibleC1 = 'a';
char visibleC2 = '\141'; //a的ASCII为97,八进制141
System.out.println(visibleC2); //打印a
char invisibleC3 = '\012'; //换行的ASCII为10,八进制012
System.out.println("abc\012def"); //一行打印abc,另一行打印def
实际上,对于部分常用的非可显示字符,我们还可以使用转义字符来表示。比如\r表示回车,\n表示换行,\t表示tab,\0表示null。举例如下所示。
char invisibleC4 = '\n'; //换行的转移字符为\n
System.out.println("abc\ndef"); //一行打印abc,另一行打印def
当然,我们也可以直接将ASCII码值来表示字符。如下代码所示。之所以可以这样来做,是因为字符a的ASCII码值为97,它存储在计算机中的二进制串,跟数值97存储在计算机中的二进制串,是一模一样的,都是0110 0001。对于0110 0001这个二进制串,到底是表示为字符a,还是数值97,全看编译器如何解读。
char ch = 97;
System.out.println(ch); //打印:a
实际上,char类型数据之间还可以进行比较操作,对应的就是,将字符编码转变为无符号数之后进行大小比较。除此之外,char类型数据还可以进行加减操作,对应的就是,将字符编码转变为无符号数之后的加减操作,示例代码如下所示,将字符串“231”转化为整数231。
public int convert(char[] chs, int n) {
int res = 0;
for (int i = 0; i < n; ++i) {
res = res*10 + (chs[i]-'0');
}
return res;
}
2)GB*系列字符集和字符编码
ASCII只能表示128个字符,对于英文来说可能足够了,但是,对于中文、日文、韩文等,所包含的字符远远不止这些,所以,当计算机传到世界各地之后,为了适应各地的语言,又相继发布了其他字符集和字符编码。支持中文的字符集和字符编码,大都以GB开头来命名,比如常见的有GB2312、GBK、GB18030。
GB2312发布于1980年,是第一个中文字符集和字符编码的。它采用定长存储方式,每个字符编号都用2个字节来存储。尽管2个字节可以表示6万多(2^16)个不同的字符,但因为其特殊的编码方式,GB2312仅收录了6000多个汉字及其他符号,总共7000多个字符。
尽管GB2312收录了使用频率超过99%的常用汉字,但对于一些罕用字、人名等,GB2312无法表示,毕竟中国汉字有10万多个,显然,GB2312是不够全面的。于是就出现了GBK。尽管GBK仍然使用2个字节,但因为其使用新的编码方式(对于GB*字符集的编码方式,我们不展开讲解),能表示的字符增多,比GB2132增加了2万多个汉字和符号。
GB18030兼容GB2132和GBK,并且可表示的字符更多,共收录了7万多个汉字。GB18030采用变长编码方式,不同的字符使用不同长度的字节(1字节、2字节或4字节)来存储存储的字节长度是不同的。关于变长编码和定长编码的编码原理和优缺点,我们在Unicode字符集及其3种字符编码中讲解。
3)Unicode字符集和UTF*系列字符编码
各个语言都有自己的字符集和字符编码,同一串二进制位在不同的字符集和字符编码中,代表不同的字符。这就导致我们无法在一个文档中使用两种不同的语言(不同的字符集和字符编码)。
为了大一统,Unicode字符集就出现了。Unicode字符集包含大约100万个字符,涵盖了世界上所有语言的所有字符,每一个字符都对应一个不同的编号。使用Unicode字符集,我们就能在同一个文档里使用不同语言的字符了。我们一般习惯将字符编号表示为十六进制,并且辅以前缀“U+”,以表示此编号为Unicode字符编号。
尽管Unicode字符集中的字符个数超百万,但常用的并不多,为了让常用字符的编号尽可能小(这样计算机在存储时会节省空间,待会会讲),Unicode字符集将编号分为两部分。
- 编号从U+0~U+FFFF,并且排除U+D800~U+DFFF,分配给使用频率最高的字符,这几乎涵盖了各个语言中的常用字符。至于为什么要排除U+D800~U+DFFF这个范围的编号,我们在讲完UTF-16字符编码后你就明白了。
- 编号从U+10000~U+10FFFF,大约有100多万个编号,分配给剩下的所有字符。
Unicode只是一个字符集,包含字符及其编号,但并不包含字符编号在计算机中的存储方式,也就是字符编码。按照编码的复杂程度,我们来依次讲解Unicode字符集对应的3种字符编码:UTF-32、UTF-16、UTF-8。
**先看最简单的UTF-32。**UTF-32是定长编码,使用4个字节来存储Unicode编号。定长的好处就是编码简单,只需要将字符编号直接存入计算机即可。读取时解码也非常简单,每读取四个字节解码为一个字符。
**我们再来看UTF-16。**UTF-16采用变长编码,U+0~U+FFFF范围(不包含U+D800~U+DFFF)内的编号使用2字节编码,U+10000~U+10FFFF之间的编号采用4字节编码。采用变长编码方式,比起定长的UTF-32编码方式,更加节省存储空间。但是,编解码也复杂了很多。当从一个文本中读取2个字节之后,我们怎么知道这2个字节对应的数值,是U+0~U+FFFF范围的2字节编码,还是U+10000~U+10FFFF范围内的4字节编码的高十六位或低十六位呢?
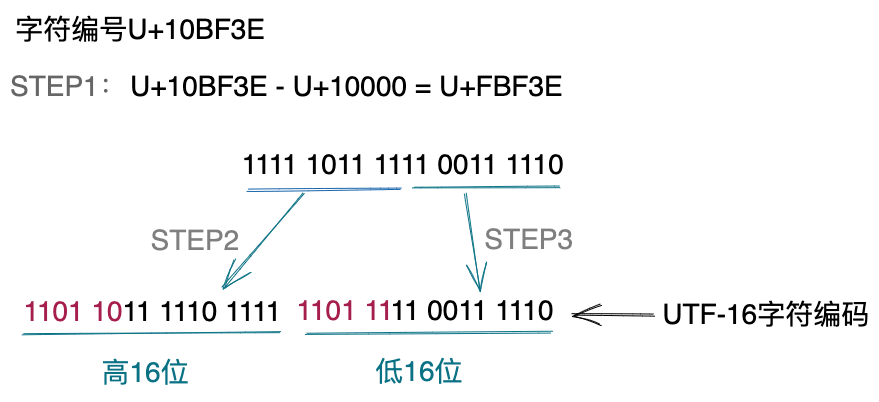
为了解决这个问题,UTF-16将U+0~U+FFFF之间的Unicode编号,直接存储在2个字节中,而对于U+10000~U+10FFFF之间的Unicode编号,采用如下特殊编码方式。
- STEP1:将U+10000~U+10FFFF范围内的Unicode编号减去10000,得到新的范围:U+00000~U+FFFFF,新的范围内的每个编号,只使用20个二进制位就能表示。
- STEP2:将20个二进制位中的高10位取出,放到UTF-16的4字节编码中的高16位中,前面多出的6位用110110补全。这样高16位的数据范围就变成了U+D800~U+DBFF。
- STEP3:将20个二进制位中的低10位取出,放到UTF-16的4字节编码中的低16位中,前面多出的6位用110111补全。这样低16位的数据范围就变成了U+DC00~U+DFFF。
上述处理过程如下示例所示。
因为UTF-16最小的编码长度是两字节,所以,在将二进制编码解码为字符时,我们会每次从文本中读取两个字节来分析。
- 如果这两个字节的数值落在U+D800~U+DBFF范围之间(也就是前缀为110110),那么读出的这两个字节就是4字节编码的高十六位;
- 如果数值落在U+DC00~U+DFFF范围内(也就是前缀为110111),那么读出的这两个字节就是4字节编码的底16位。
- 如果数值不落在U+D800~U+DFFF范围内(U+D800~U+DBFF 和U+DC00~U+DFFF),那么读出的这两个字节就是2字节编码。
还记得前面提到,在Unicode字符集中,在U+0~U+FFFF这个范围内,U+D800~U+DFFF这个范围的编号并没有使用,没有对应的字符,原因就是2字节编码跟4字节编码的高16位和低16位数据做区分。
实际上,在UTF-16编码中,4字节编码的低16位并不需要特殊标识,因为对于一个正确编码了的文件,每次读取2字节之后,如果判定是4字节编码的高16位,那么紧挨着的2个字节肯定是这个4字节编码的低16位,顺序读取即可,不需要再做判断。
**最后,我们来看下UTF-8。**相比UTF-16,字符对字符占用存储空间的大小,控制得更加精细,编码也更加复杂,它同样使用变长编码,包括4种类型的编码:1字节编码、2字节编码、3字节编码、4字节编码。不同范围内的编号使用不同的编码。
- U+0000~U+007F范围内的编号使用1字节编码
- U+0080~U+07FF范围内的编号使用2字节编码
- U+0800~U+FFFF范围内的编号使用3字节编码
- U+10000~U+10FFFF范围内的编号使用4字节编码
具体的编码规则如下所示。
| 编码 | 范围 | 第1个字节 | 第2个字节 | 第3个字节 | 第4个字节 |
|---|---|---|---|---|---|
| 1字节编码 | 0000~007F | 0xxxxxxx | |||
| 2字节编码 | 0080~07FF | 110xxxxx | 10xxxxxx | ||
| 3字节编码 | 0800~FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 4字节编码 | 10000~10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
在UTF-8的编码规则中,1字节编码的首字节的前缀为0,2字节编码的首字节的前缀为110,3字节编码的首字节的前缀为1110,4字节编码的首字节的前缀为11110。尾随字节的前缀均为10。尾随字节并没有继续区分是哪种编码的尾随字节。
我们再来看,上图中的xxxx如何替换为具体的Unicode编号。我们举一个例子来分析。在U+0080~U+07FF范围内的编号,最多只需要11位二进制位来表示,我们将11位二进制位的前5位放入2字节编码的第一个字节的xxxxx中,把后6位放入第二个字节的xxxxxx中。示例如下所示。
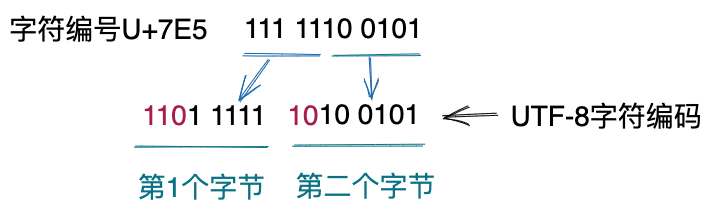
跟UTF-16编码类似,UTF-8这样编码的目的是,明确读取出来的字节,属于哪种类型的编码(1字节编码、2字节编码...)。因为UTF-8的最短编码长度是1字节,在读取二进制文件进行解码时,我们每次读取一个字节,判定是哪种类型的首字节编码。假如是3字节编码的首字节编码,那么我们再顺序往下读取2个尾随字节。
UTF-8比UTF-16采用更加复杂的编码,那么,在平时的开发中,使用UTF-8是不是一定比使用UTF-16更加节省存储空间呢?
答案是否定的。仔细观察编号范围与编码长度,我们可以发现,如果在开发中,存储英文字符居多,那么,使用UTF-8更加节省空间,因为为了兼容ASCII码,Unicode中编号0~127之间的字符跟ASCII码一一对应,英文字符的Unicode编号在0~127之间,使用UTF-8编码只需要1个字节长度,而是使用UTF-16编码则需要2个节长度。但是,如果存储非英文字符居多,比如中文,那么使用UTF-16反倒会更加节省空间。因为常用的非英文字符,在UTF-16中编码长度为2字节,而在UTF-8中编码长度为2字节或3字节,并且3字节居多。
三、Java中char的字符编码
因为C语言出现的较早,彼时多数计算机还只支持英文系统,而C++又继承了C语言的特性,所以,C/C++中的char类型占用一个字节长度,只能存储ASCII字符,完全满足英文系统的编程开发。在此之后,随着计算机到世界各地,C/C++选择使用char数组(char[])来存储非ASCII字符,比如中文。
因为Java出现较晚,Unicode已经流行,为了让char类型表示更多的字符,Java设计了两个字节长的char类型,存储部分Unicode字符(U+0~U+FFFF之间的),Unicode字符会通过UTF-16编码之后存储到char类型变量中。
Java中的char类型只占2个字节长度,所以,并不能存储所有的UTF-16编码,也就不能表示所有的Unicode字符。不过,平时经常用到的字符,一般都是Unicode编号处于U+0~U+FFFF之间的字符,为了避免存储空间的浪费,Java让char类型占2字节长度,只表示Unicode编号处于U+0~U+FFFF之间的字符。跟ASCII码类似,我们也有3种方法将Unicode字符赋值给char类型变量:
- 对于可显示字符,我们可以直接使用字符。
- 对于所有字符(可显示或不可显示),我们都可以将字符对应的UTF-16编码表示为\uxxxx的形式赋值给变量。其中xxxx为16进制。
- 对于所有字符,我们都可以将字符对应的Unicode编号赋值给变量。
示例代码如下所示。
char a = '我'; //字符本身
char b = '\u6211';//UTF-16编码
char c = 0x6211; //Unicode编号
System.out.println(a); //打印:我
System.out.println(b); //打印:我
System.out.println(c); //打印:我
那么,U+10000~U+10FFFF范围内的Unicode字符在Java中如何存储呢?类似C/C++存储ASCII码之外字符的做法,Java使用char数组来存储U+10000~U+10FFFFF之间的字符,示例代码如下所示。
// 🜁 这个字符的Unicode编号为U+1F701,UTF-16编码为:D83D DF01
char[] chs = new char[2];
chs[0] = '\uD83D';
chs[1] = '\uDF01';
System.out.println(chs); //🜁
String s = "\uD83D\uDF01";
System.out.println(s); //🜁
char[] chs2 = Character.toChars(0x1F701);
System.out.println(chs2); //🜁
四、课后思考题
1)在本节中,我们编写代码,实现了将字符串“231”转化成整数231,那么,请你编写代码,实现将整数231转换成字符串“231”。
2)将一个只包含a~z、A~Z、0~9之间字符的字符串转换为小写字符串,例如,“A34bc”转化为“a34bc”)