基础语法
基础语法
从CPU角度看变量、数组、类型、运算、跳转、函数等语法
对于绝大部分编程语言来说,不管是Python、Ruby、PHP、JavaScript,还是Go、C/C++、Java,其包含的基本语法无外乎这样几种:变量、类型、数组、运算(赋值、算术、逻辑、比较等)、跳转(条件、循环)、函数,而其他语法(比如类、容器、异常等)在CPU眼里只不过是语法糖。本节,我们就来看下,编程语言中的这些基本语法,在CPU眼里是什么样子的。
一、变量
我们知道,内存被划分为一个个的内存单元。每个内存单元都对应一个内存地址,方便CPU根据内存地址来读取和操作内存单元中的数据。
对于高级语言来说,内存地址可读性比较差,所以,就发明了变量这种语法。变量可以看作是内存地址的别名。内存地址和变量的关系,跟IP地址和域名的关系类似。在机器码中,我们通过内存地址来实现对内存中数据的读写。在代码中,我们通过变量来实现对内存中数据的读写。编译器在将代码编译成机器码时,会将代码中的变量替换为内存地址。
不同的变量有不同的作用域(也可以理解为生命周期)。不同作用域的变量,分配在代码段的不同区域。不同的区域有不同的内存管理方式。不同语言对数据段的分区方式会有所不同,但又大同小异(关于Java语言如何对数据段分区,我们在JVM部分讲解),常见的分区有栈、堆、常量池等。
笼统来讲,栈一般存储作用域为“函数内”的数据,如函数内部的局部变量、参数等,它们只在函数内参与计算,函数结束之后,就不再使用了,所占用的内存单元就可以释放,以供其他变量重复使用。堆一般存储作用域不局限于“函数内”的数据,如对象,只有在程序员主动释放(如C/C++语言)或虚拟机判定为不再使用(如Java语言)时,对象对应的内存单元才会被释放。常量池一般存储常量等,常量的生命周期跟程序的生命周期一样,只有在程序执行结束之后,对应的内存单元才会被释放。
也就是说,对数据段进行分区,是为了方便管理不同生命周期的变量。而之所以不同的变量要设置不同的生命周期,是为了能够有效的利用内存空间,方便在变量生命周期结束之后,对应的内存单元能够快速地被回收,以供重复使用。
二、数组
假设我们需要在代码中表示一个学生的10门课的成绩,如果编程语言中没有“数组”这种语法,我们需要定义10个变量,而使用数组就方便了很多。使用数组,我们可以定义一块连续的内存空间,存储这10门课的成绩,并通过下标来访问数组中的数据。示例代码如下所示。
public class Test {
public void demo() {
int[] a = new int[10];
a[3] = 92;
System.out.println(a[3]);
}
}
在上述示例代码中,a是一个局部变量,存储在栈上。“int[] a = new int[10]”这条语句表示,在堆上申请一块能够存储下10个int类型数据的连续的内存空间,并将这块内存空间的首地址存储在a变量所对应的内存单元中。实际上,数组是一种引用类型,关于它的内存结构,我们再下一篇文章中详细讲解。
当通过下标来访问数组中的元素时,如语句“a[3]=92”,编译器将这条语句分解为多条CPU指令,先通过变量a中存储的首地址和如下寻址公式,计算出下标为3的元素所在的内存地址,然后将92写入到这个内存地址对应的内存单元。
a[i]的内存地址 =
a中存储的值(也就是数组的首地址)+ i*4(4表示4字节,也就是数据类型的长度)
在Java语言中,new申请的数组存储在堆上,首地址赋值给栈上的变量。而在有些语言中,比如C语言,“数组”语法更加灵活,既可以申请在堆上,也可以申请在栈上。如下所示。
int a[100]; //数组在栈中,可以直接类似a[2]=92;这样使用了
int a[100] = malloc(sizeof(int)*100); //数组在堆中
实际上,如果你了解JavaScript语言,你还会发现,JavaScript中的数组还可以存储不同类型的数据,如下所示。
var arr = new Array(4, 'hello', new Date());
var name = arr[1];
在上述示例中,数组中存储的是不同类型的数据,因此,上文中提到的寻址公式就无法工作了,那JavaScript是如何通过下标定位到元素的内存地址的呢?
实际上,不同编程语言中的数组,其在内存中的存储方式并不完全一样,也并非只有在上文中讲到的“在一块连续的内存空间中存储相同类型的数据”这样一种存储方式。关于这一点,读者可以参看《数据结构与算法之美》纸质书中的第19页(2.2节:数据结构中的数组和编程语言中的数组的区别),其中有详细的讲解C/C++、Java、Javascript三种语言中的数组在不同情况下的内存存储方式。当然,在下一节中,我们也会详细讲解Java语言中数组的内存存储方式。
三、类型
在CPU眼里,是没有类型这一概念的。任何类型的数据,在CPU眼里都是只有一串二进制码。一串二进制码是表示为字符串还是整型数又或者浮点数,完全看编译器怎么解读,看在代码中怎么定义这块内存单元的类型的。
引入类型的目的是,方便程序员编写正确的代码,避免错误的赋值操作。比如,用int类型的变量age来存储用户的年龄,如果程序员试图将字符串“wangzheng”赋值给变量age,Java语言就会在编译代码时报错,提醒程序员修改。
不同的编程语言具有不同的类型系统。根据变量的类型是否可以动态变化和类型检查发生的时期,我们将类型系统分为静态类型和动态类型。静态类型指的是,一个变量的类型是唯一确定的,类型检查发生在编译期。动态类型指的是,一个变量的类型是可变的,具体看赋值给它的数据是什么类型的,类型的检查发生在运行期。
我们拿Java和PHP举例说明。代码如下所示。在Java代码中,变量s的类型是确定的,类型检查发生在编译期。在PHP代码中,变量s的类型不确定,可以赋值为任意类型的数据。变量s的类型由当前被赋值的数据的类型来决定。所以,Java是静态类型语言,PHP是动态类型语言。
// Java代码
String s="wangzheng";
// PHP代码
$s = "wangzheng";
$s = 233;
$s = new Student();
除了静态类型语言和动态类型语言这种分类方式之外,在平时的开发中,我们还经常听到另外一种分类方式:弱类型语言和强类型语言。实际上,这种分类方式没有太大意义。强和弱是对程度的描述,并不是非黑即白。所以,我们很难判定某种语言到底是强类型语言还是弱类型语言。所以,你不要纠结于这种分类方式,稍微了解即可。
四、运算
在编程语言中,常见的运算类型有以下5种:
1)算术运算,比如加、减、乘、除;
2)关系运算,比如大于、小于、等于;
3)赋值运算,比如a=5;
4)逻辑运算,比如&&,||,!;
5)位运算,比如&,|,~,^,>>, <<;
以上绝大部分运算在CPU中都有对应的指令。不过,不同类型的指令对应的电路逻辑不同,所以,执行花费的时间不同,比如位运算会比较快,乘法、除法比较慢。
我们通过一个简单的C语言例子,来看一下上述运算对应的汇编指令。
#include <stdio.h>
int main() {
// 赋值
int a = 1; // 对应movl指令
int b = 2;
// 算术
int c = a + b; //对应addl指令
int d = a * b; //对应imull指令
// 关系
if (c < d) { //对应cmpl和jge指令
printf("c<d");
}
// 逻辑
if (a > 2 || b > 2) { //对应cmpl和jg指令
printf(">2");
}
// 位运算
int e = a & b; //对应andl指令
return e;
}
汇编为汇编代码如下所示。代码中的核心计算都添加了注释,你可以结合注释来理解。
$gcc -S test2.c
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
movq %rsp, %rbp
subq $32, %rsp
movl $0, -4(%rbp)
movl $1, -8(%rbp) ;a存储在栈上,a=1;
movl $2, -12(%rbp) ;b存储在栈上,b=2;
movl -8(%rbp), %eax ;a的值放入寄存器eax
addl -12(%rbp), %eax ;a+b,结果放入eax
movl %eax, -16(%rbp) ;a+b的值放入c(c在栈上)
movl -8(%rbp), %eax ;a的值放入寄存器eax
imull -12(%rbp), %eax ;a*b,结果放入eax
movl %eax, -20(%rbp) ;a*b的值放入d(d在栈上)
movl -16(%rbp), %eax ;c的值放入寄存器eax
cmpl -20(%rbp), %eax ;c<d,结果放到标志寄存器中,
jge LBB0_2 ;jge根据标志寄存器的值做跳转
## %bb.1:
leaq L_.str(%rip), %rdi ;printf("c<d");
movb $0, %al
callq _printf
LBB0_2:
cmpl $2, -8(%rbp) ;判断a>2,结果放到标志寄存器中,
jg LBB0_4 ;jg根据标志寄存器的值做跳转
## %bb.3:
cmpl $2, -12(%rbp) ;判断b>2,结果放到标志寄存器中,
jle LBB0_5 ;jg根据标志寄存器的值做跳转
LBB0_4:
leaq L_.str.1(%rip), %rdi ;printf(">2");
movb $0, %al
callq _printf
LBB0_5:
movl -8(%rbp), %eax ;a放入寄存器eax
andl -12(%rbp), %eax ;a&b,结果放入eax
movl %eax, -24(%rbp) ;a&b的结果放入e(e在栈上)
movl -24(%rbp), %eax ;返回值放入eax
addq $32, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "c<d"
L_.str.1: ## @.str.1
.asciz ">2"
.subsections_via_symbols
这里稍微解释一下。在本节的讲解中,大部分情况下,我们都是采用C/C++语言来举例,因为使用C/C++语言编写的代码,查看编译之后的汇编代码,比较方便。而对于用Java语言编写的代码,因为Java语言是解释执行的,获取Java代码对应的汇编代码的过程比较繁琐,需要借助额外的工具,将JIT编译之后的机器码反汇编成汇编语言才可,过程比较复杂。并且,由此得到的汇编代码,因为掺杂了虚拟机的部分代码,可读性也比较差。
对于绝大多数Java程序员来说,即便是要了解Java语言的底层原理或者优化代码性能,也只需要研究到字节码这一层就足够了,完全不需要深入到汇编代码层面。所以,对于如何获取Java代码对应的汇编代码,这不是专栏讲解的重点。不过,为了满足一些朋友的好奇心,我编写了查看Java代码对应汇编代码的操作文档,放到了资料中(点击此处查看),感兴趣的可以看一下。
我们本节给出某些代码的汇编代码的原因,并非是让你学习汇编语言,而只是让你更加直观地理解,编程语言的基础语法在CPU层面的表示方式。而且,对于本节讲解的基础语法,绝大部分编程语言的底层实现都是大差不差的,编译成机器码之后,在CPU眼里都是一样的。所以,我们使用比较容易获得、比较容易读懂的C/C++代码对应的汇编代码来举例。
五、跳转
程序由顺序、选择(或叫分支、条件)、循环三种基本结构构成,其中,选择和循环又统称为跳转。接下来,我们通过一个C语言代码示例,来看下两种跳转在CPU眼里是如何实现的。
#include <stdio.h>
int main() {
int a = 1;
int b = 2;
// 选择
if (a < b) {
printf("a<b");
}
// 循环
for (int i = 0; i < 100; ++i) {
printf("%d", i);
}
return 0;
}
汇编成汇编代码如下所示。代码中的核心语句都添加了注释,你可以结合注释来理解。
$ gcc -S test3.c
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $0, -4(%rbp)
movl $1, -8(%rbp) ;a=1,a存储在栈上
movl $2, -12(%rbp) ;b=2,b存储在栈上
movl -8(%rbp), %eax ;a值放入寄存器eax
cmpl -12(%rbp), %eax ;a<b,比较结果放入标志寄存器
jge LBB0_2 ;通过标志寄存器判断如何跳转
## %bb.1:
leaq L_.str(%rip), %rdi
movb $0, %al
callq _printf ;printf("a<b");
LBB0_2:
movl $0, -16(%rbp) ;i=0,i存储在栈上
LBB0_3: ## =>This Inner Loop Header: Depth=1
cmpl $100, -16(%rbp) ;i<100,比较结果放入标志寄存器
jge LBB0_6 ;通过标志寄存器判断如何跳转
## %bb.4: ## in Loop: Header=BB0_3 Depth=1
movl -16(%rbp), %esi
leaq L_.str.1(%rip), %rdi
movb $0, %al
callq _printf ;printf("%d", i);
## %bb.5: ## in Loop: Header=BB0_3 Depth=1
movl -16(%rbp), %eax ;i值放入eax寄存器
addl $1, %eax ;eax寄存器内值+1
movl %eax, -16(%rbp) ;eax寄存器的值赋值给i,相当于i++
jmp LBB0_3 ; ;跳转去判断i<100
LBB0_6:
xorl %eax, %eax
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "a<b"
L_.str.1: ## @.str.1
.asciz "%d"
.subsections_via_symbols
从上述汇编代码中,我们可以看出,不管是if选择语句,还是for循环语句,底层都是通过CPU的跳转指令(jge、jle、je、jmp等)来实现的。跳转指令比较类似早期编程语言中的goto语法,可以实现随意从代码的一处跳到另一处。而在之后的编程语言的演化中,goto语法被废弃。那么,为什么要废弃goto语法呢?
goto语法使用起来非常灵活,随意使用极容易导致代码可读性变差。你可以想象一下,如果代码执行过程中,一会跳到前面某行,一会又跳到后面某行,跳来跳去,代码的执行顺序将会非常混乱。阅读代码将会十分困难。
而之所以,我们能够废弃goto语法,就是因为选择、循环这两种基本结构,可以满足编写代码逻辑的过程中对跳转的需求,而且,选择和循环实现的跳转都是局部的,不会到处乱跳,所以,不会影响代码整体的执行顺序,可读性也不会变差。
六、函数
编写函数是代码模块化的一种有效手段。几乎所有的编程语言都会提供函数这种语法。函数的底层实现,相对于前面讲的几种基本语法的底层实现,要复杂一些。函数底层实现依赖一个非常重要的东西:栈。就是我们前面讲到的,用来保存局部变量、参数等的内存区域。因为这块内存的访问方式是先进后出,符合栈这种数据结构的特点,所以,也被称为栈。
为什么函数底层实现需要用到栈呢?
每个函数都是一个相对封闭的代码块,其运行需要依赖一些局部数据,比如局部变量等。这些数据会存储在内存中。当函数A调用另一个函数B时,CPU会跳转去执行函数B的代码。函数B的执行又会涉及一些局部变量等,这些数据也会存储在内存中(紧挨着函数A的内存块)。以此类推,当函数B调用另一个函数C时,CPU又会跳转去执行函数C的代码。函数C的内存块会紧邻函数B的内存块。如下图所示。
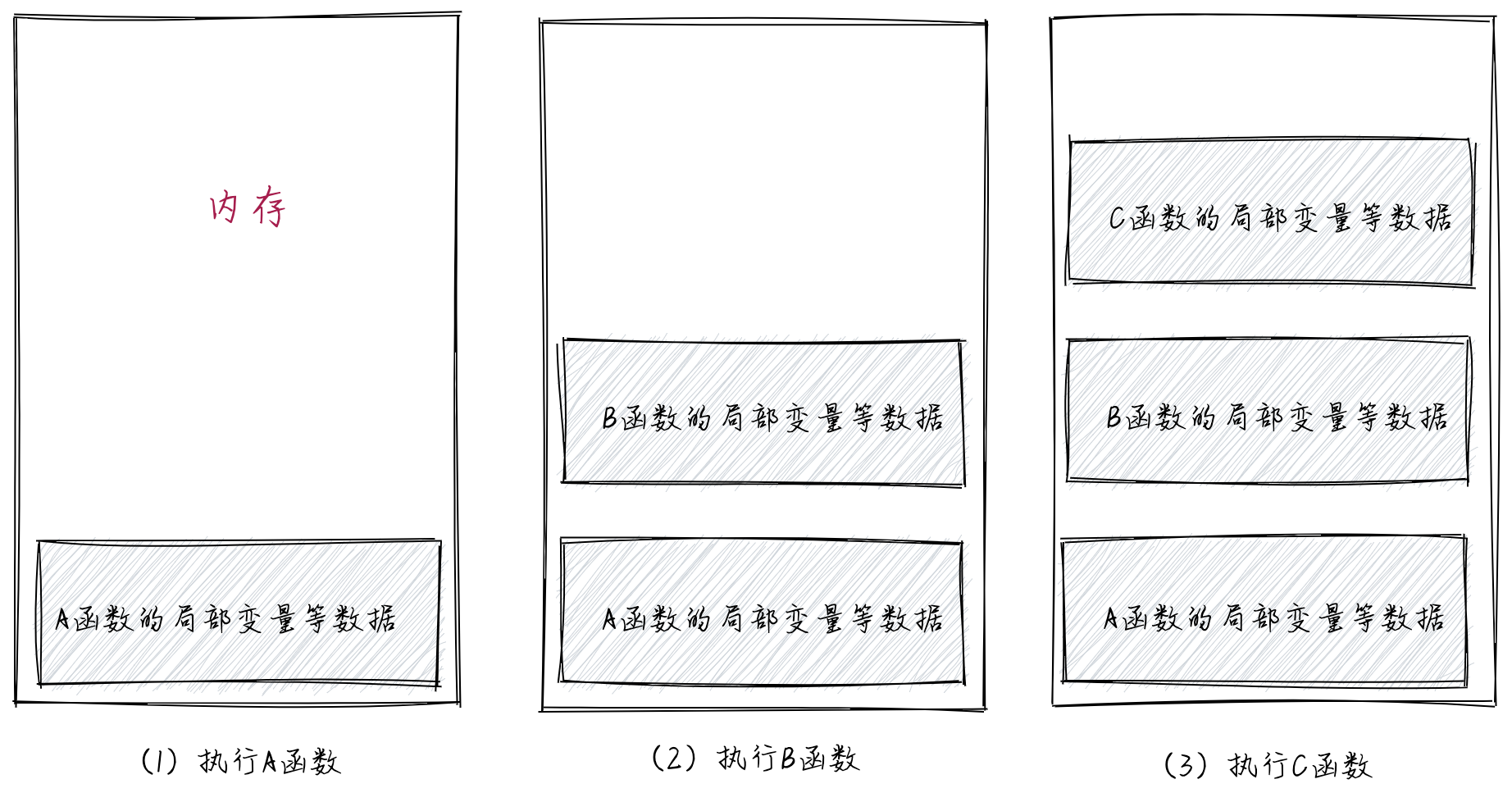
当函数C执行完成之后,函数C中的局部变量等都不再被使用,对应的内存块也可以释放以供复用,并且,CPU返回执行函数B的代码。函数B对应的内存块又开始被使用。同理,函数B执行完成之后,其对应的内存块也会被释放,CPU返回执行函数A的代码。函数A对应的内存块又开始被使用。如下图所示。
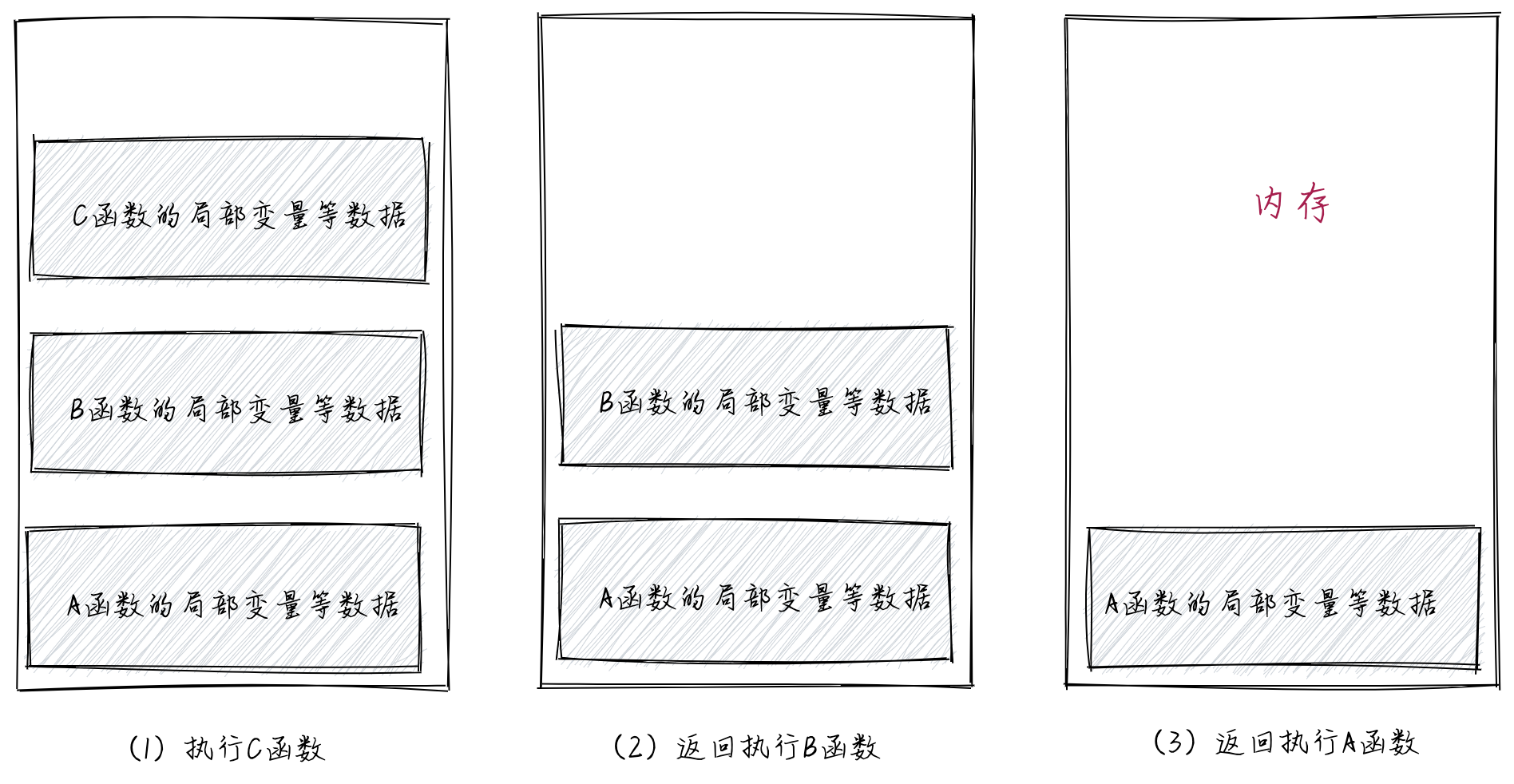
从上图,我们可以发现,在函数调用过程中,同一时间只有一个函数的内存块在被使用,并且内存块被释放的顺序为“先创建者后释放”,符合栈的特点:“只在一端操作、先进后出”。所以,编译器把函数调用所使用的整块内存,组织成栈这种数据结构(叫做函数调用栈)。我们把每个函数对应的内存块叫做栈帧。
当通过函数调用,进入一个新的函数时,编译器会在栈中创建一个栈帧(实际上就是申请一个内存块),存储这个函数的局部变量等数据。当这个函数执行完毕返回上层函数时,栈顶栈帧出栈(也就是释放内存块),此时,新的栈顶栈帧为返回后的函数对应的栈帧。从上图中,我们也可以发现,正在执行的函数对应的栈帧肯定位于栈顶。
了解了函数调用栈的大体结构之后,我们思考以下几个问题:
栈帧中除了保存局部变量之外,还保存哪些其他数据?
上一节讲到的SP寄存器和BP寄存器具体用在哪里?
CPU在执行完某个函数之后,如何知道应该回到上层函数的哪处再继续执行?
我们结合一段C语言代码来回答上述几个问题。代码如下所示。
#include <stdio.h>
int f_b(int b1, int b2) {
int b3 = b1+b2;
return b3;
}
void f_a(int a1, int a2) {
int a3 = a1-a2;
int a4 = f_b(a1, a2);
int a5 = a2-a1;
}
int main() {
f_a(1, 2);
return 0;
}
上述C语言代码汇编成汇编代码如下所示。
_f_b: ## @f_b
.cfi_startproc
## %bb.0:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
movl %eax, -12(%rbp)
movl -12(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.globl _f_a ## -- Begin function f_a
.p2align 4, 0x90
_f_a: ## @f_a
.cfi_startproc
## %bb.0:
pushq %rbp
movq %rsp, %rbp
subq $32, %rsp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
subl -8(%rbp), %eax
movl %eax, -12(%rbp)
movl -4(%rbp), %edi
movl -8(%rbp), %esi
callq _f_b
movl %eax, -16(%rbp)
movl -8(%rbp), %eax
subl -4(%rbp), %eax
movl %eax, -20(%rbp)
addq $32, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $0, -4(%rbp)
movl $1, %edi
movl $2, %esi
callq _f_a
xorl %eax, %eax
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
如果要透彻理解上述汇编代码,需要先了解以下知识点:
对于rbp、rsp、eax、edi、esi等寄存器,前面的r表示寄存器是64位的,前面的e表示寄存器是32位的。
对于pushq、popq、callq、movl、addl等指令,后面的q表示处理的是64位的数据,后面的l表示处理的是32位的数据。
栈的内存地址的增长方向是从大到小,也就说栈顶地址比栈底要小。
rbp指向栈顶栈帧的底部,rsp指向栈顶栈帧的顶部。
函数的返回值通过eax寄存器返回给上层函数。
函数的参数通过edi、esi、edx、ecx...等一系列约定好的寄存器来传递。
-4(%rbp)表示rbp寄存器中存储的内存地址-4对应的内存单元。
在上述代码中,main()函数调用f_a()函数,f_a()函数调用f_b()函数。我们从f_a()函数开始分析。当刚进入f_a()函数时,栈相关的各个数据如下所示。图中的地址为64位,为了方便表示,用...省略掉了前32位。除此之外,暂时不要纠结main()函数的栈帧里面的具体数据是什么,我们重点放在分析f_a()函数的栈帧上。当f_a()函数的栈帧分析完之后,main()函数的栈帧自然就明了了。
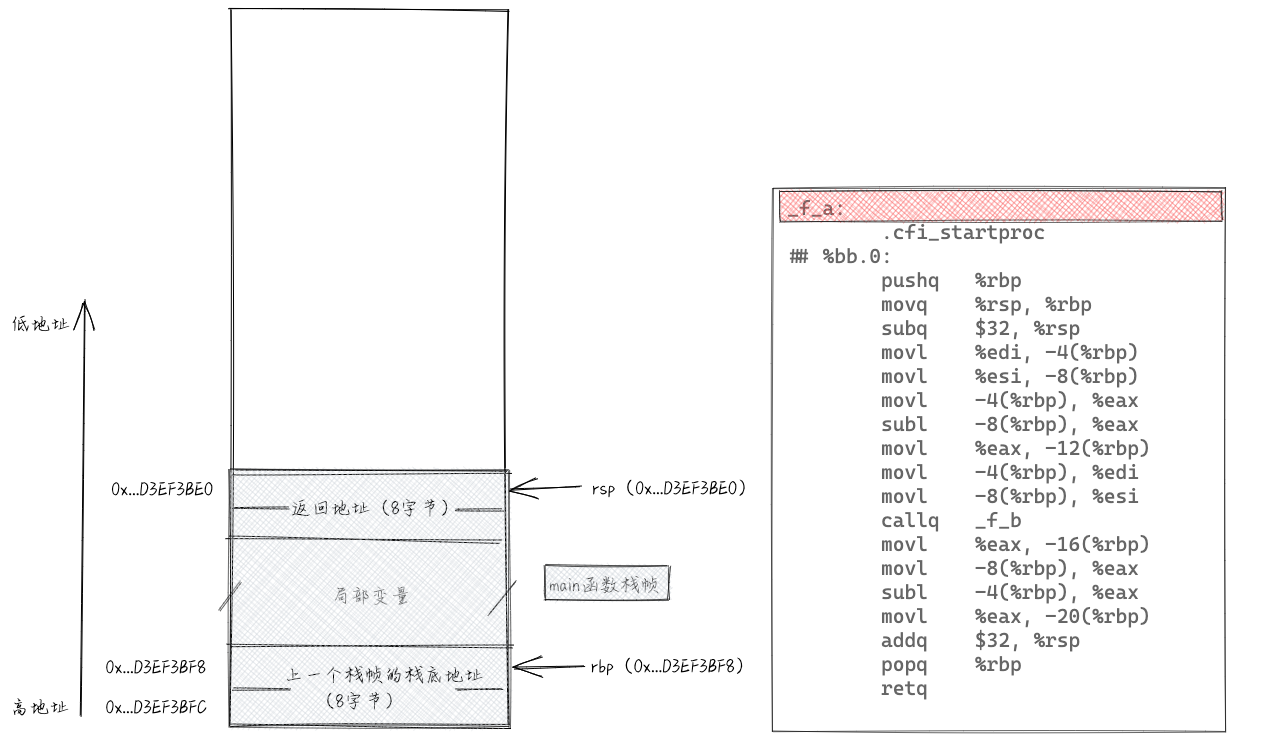
进入f_a()函数之后,最先执行“pushq %rbp”。执行这条指令相当于执行了“subq $8, %rsp”和“movq %rbp, (%rsp)”这两条指令。把rsp寄存器中存储的地址-8,然后将rbp寄存器中存储的值,放入到rsp寄存器存储的地址对应的内存单元中。rbp寄存器中存储的值是main()函数的栈帧底地址,换句话说,也就是把main()函数的栈帧底地址压入栈。pushq指令执行后,栈相关的各个数据如下所示。
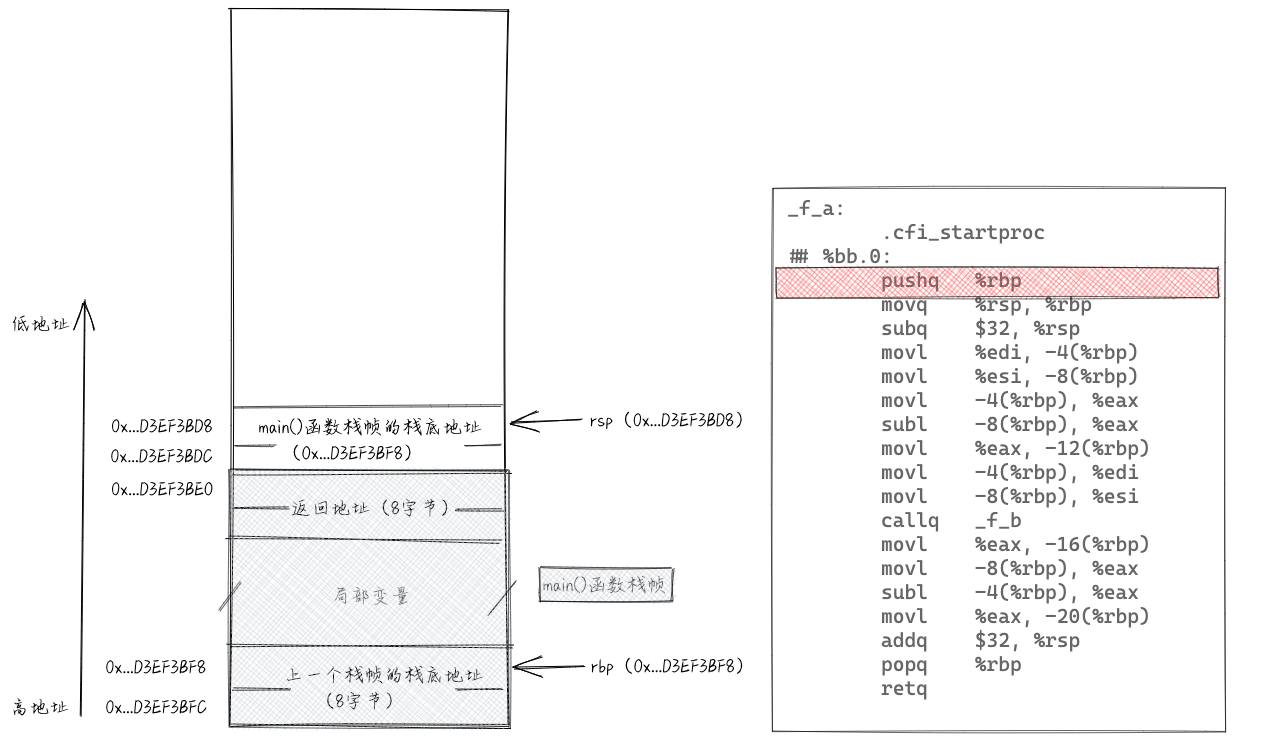
接下来执行“movq %rsp,%rbp”,将寄存器rsp中的值赋值给rbp。于是,rsp和rbp存储同一个内存地址,也就相当于指向栈中同一个内存单元(栈顶)。
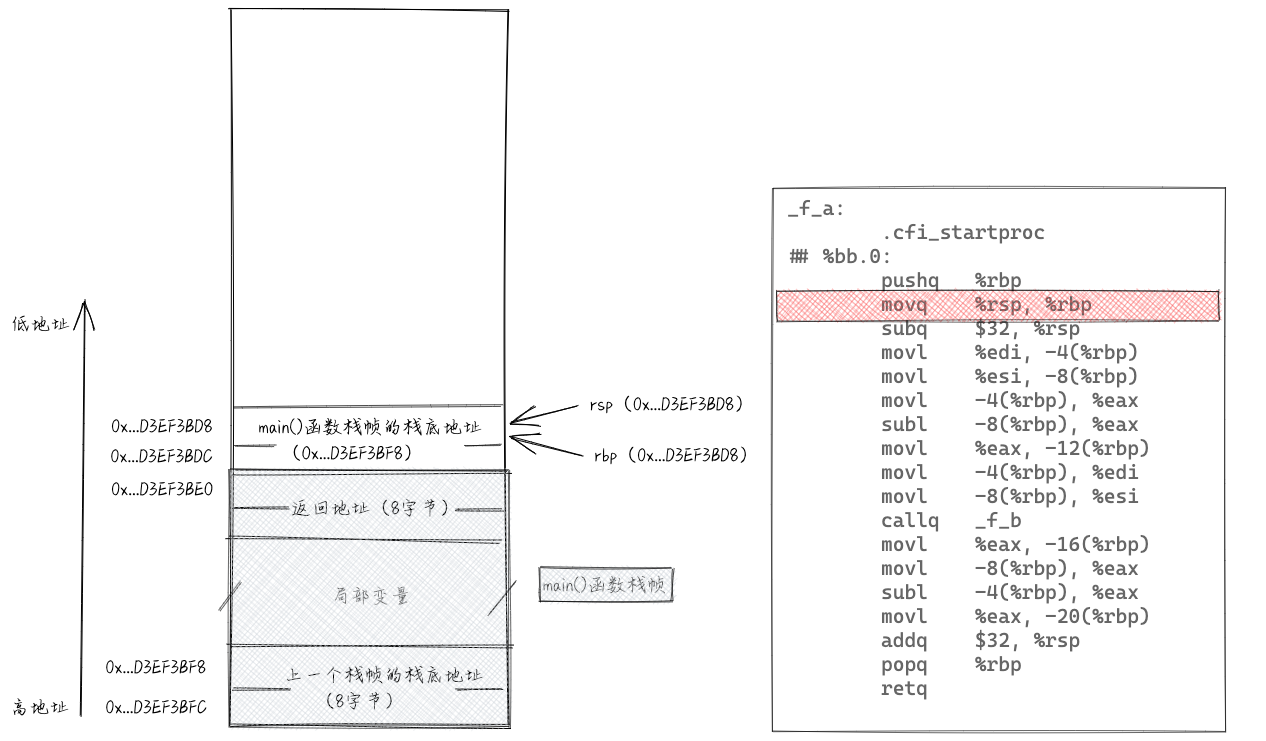
接下来执行“subq $32, %rsp”,将寄存器rsp中存储的值减去32,给f_a()函数的参数和局部变量预留存储空间。读者可能会说,f_a()函数中参数和局部变量总共有5个int类型的,顶多占20个字节的存储空间呀,为什么预留32个字节?这主要是为了内存对齐。
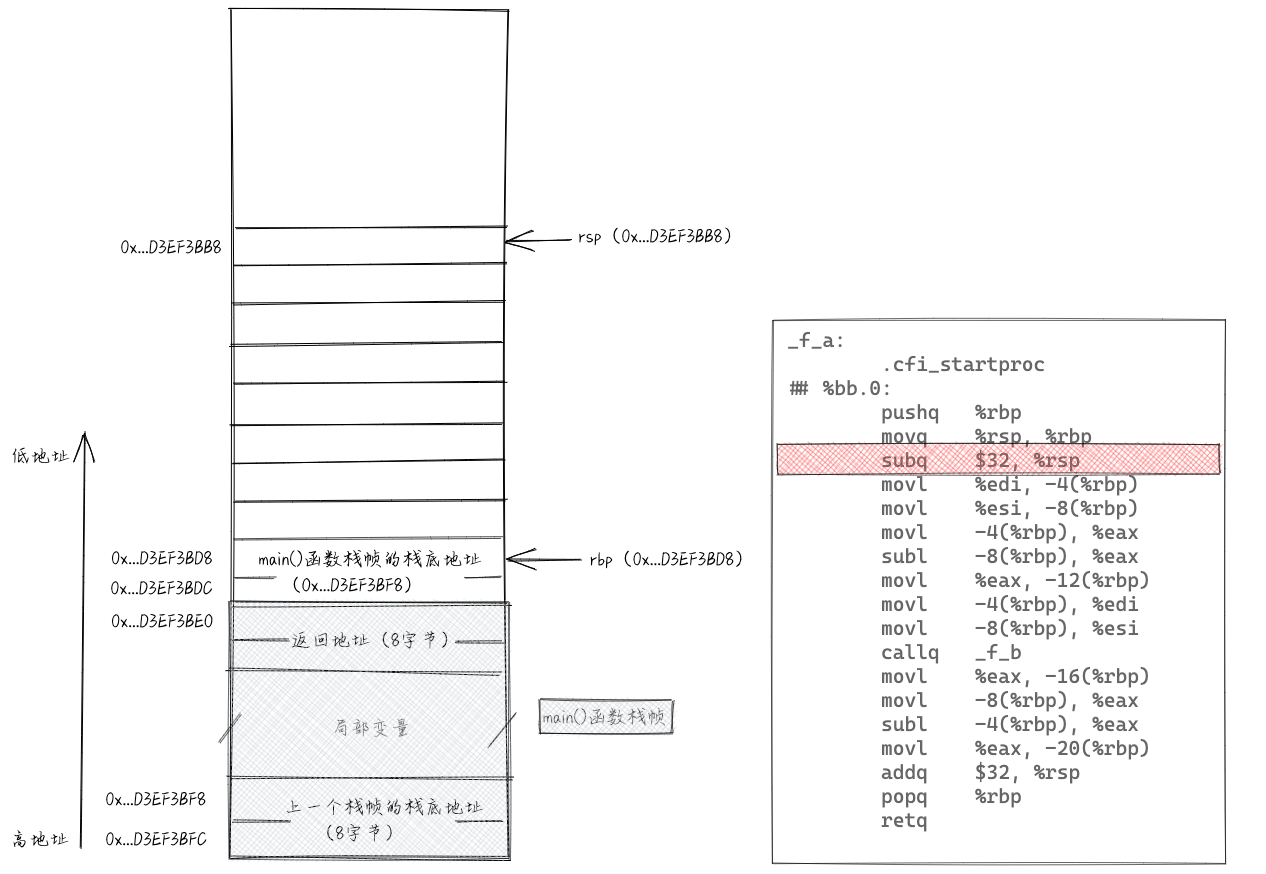
接下来执行“movl %edi, -4(%rbp)”和“movl %esi, -8(%rbp)”这两条指令,将存储在寄存器edi和esi的参数放入栈中,这样寄存器就可以释放出来以供它用。实际上,参数跟局部变量在本质上是一样的,作用域都在函数内。再接下来的三条指令是计算a1-a2,并将计算结果赋值给a3。这5条指令执行完之后,栈相关的数据如下所示。
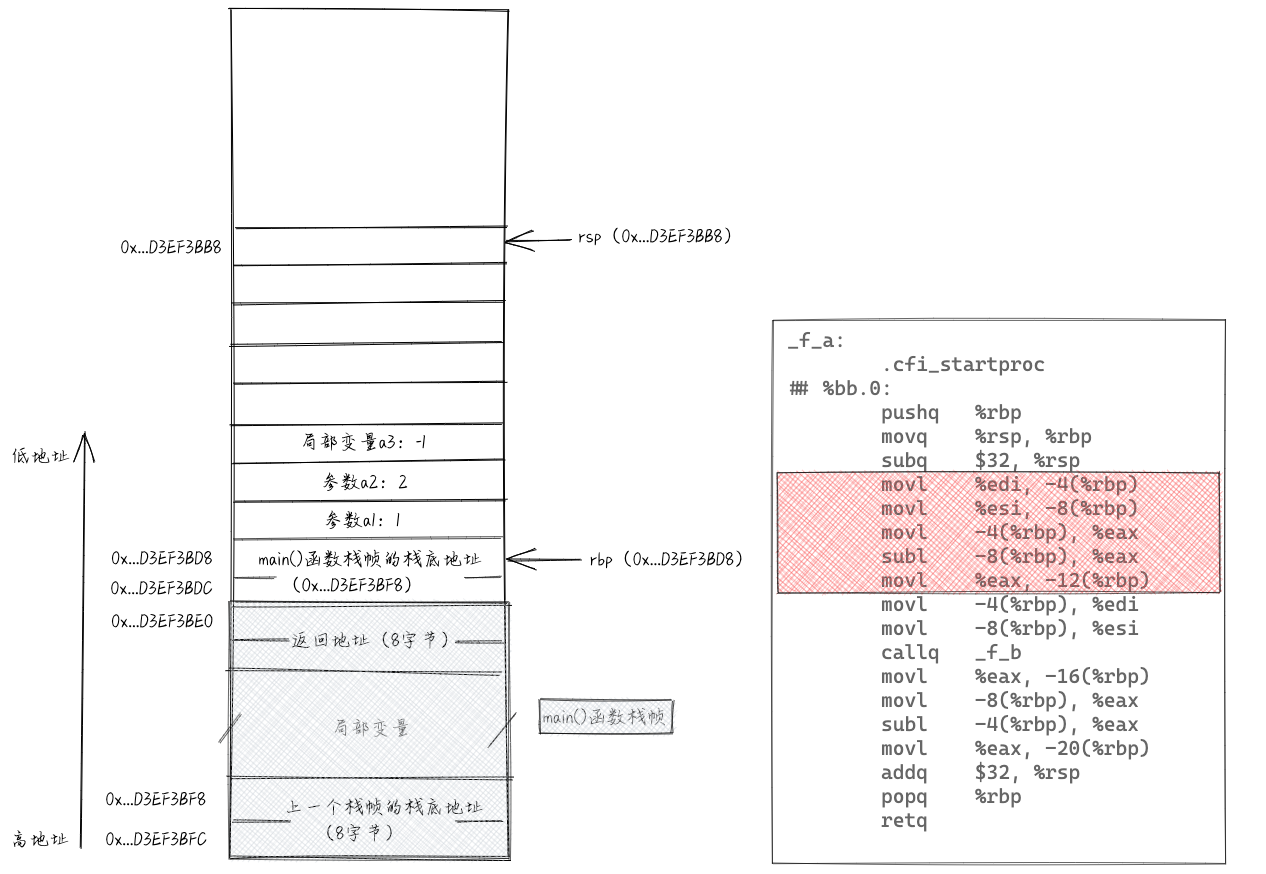
接下来调用f_b()函数。先将参数值放入edi和esi寄存器,然后跳转到f_b()函数。我们重点看下callq指令。执行“callq _f_b”相当于执行了“pushq %rip”和“jmp _f_b”两条指令,将指令指针寄存器rip中的值压入栈,然后再跳转去执行f_b()函数的代码。rip寄存器中存储的是callq下一条指令的地址,也就是f_b()函数执行完成,返回到f_a()函数之后,继续往下执行的第一条指令的地址。也就是我们常说的“返回地址”。执行完callq指令之后,栈相关的数据如下图所示。
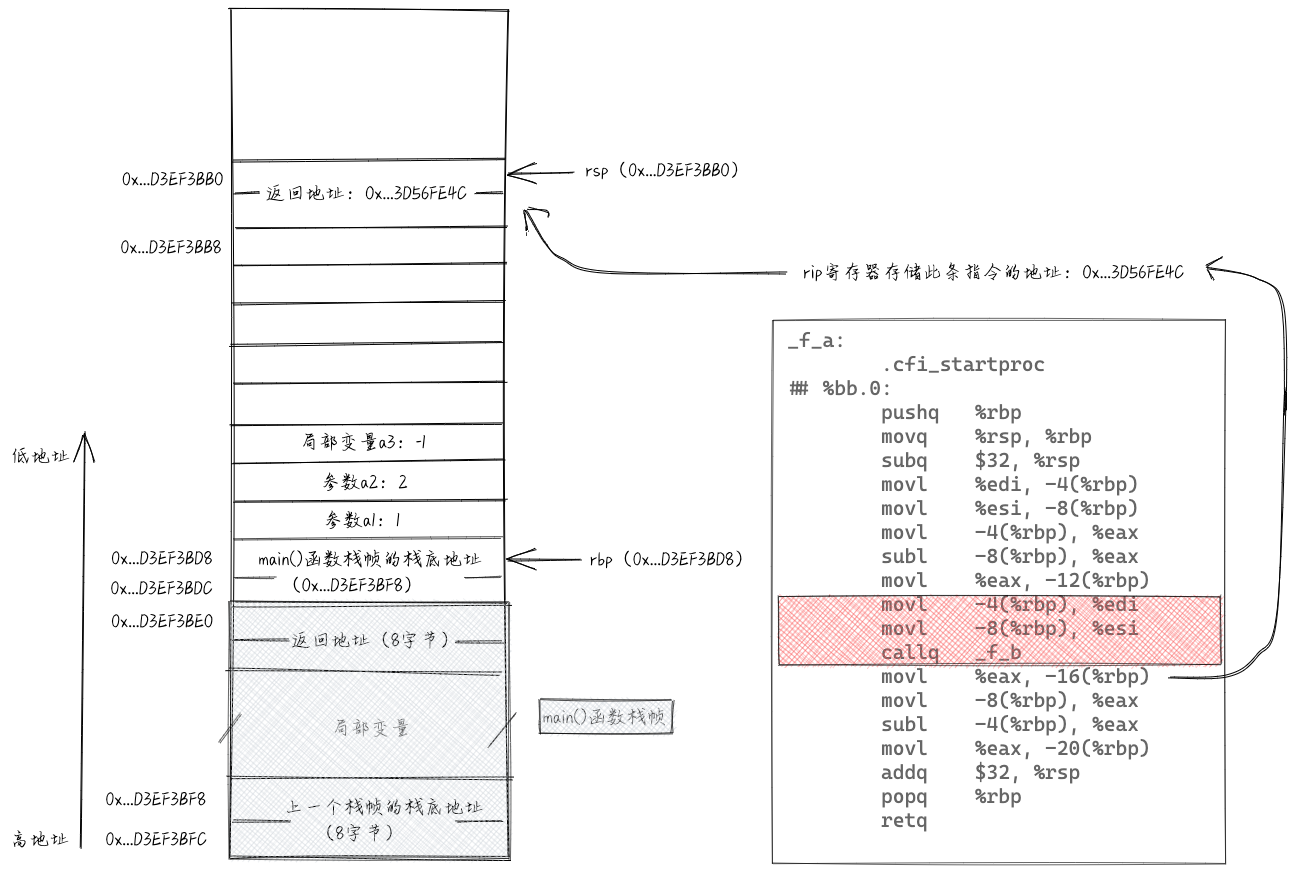
接下来执行f_b()函数。f_b()函数并没有像f_a()函数那样通过subq指令预留参数和局部变量的存储空间,这是因为f_b()函数是最后一个执行的函数,所以做了一些优化,没有移动rsp指针。f_b()函数中的指令跟f_a()函数中的指令类似,我们就不一条一条分析了。在执行到popq指令之前,栈相关的数据如下图所示。
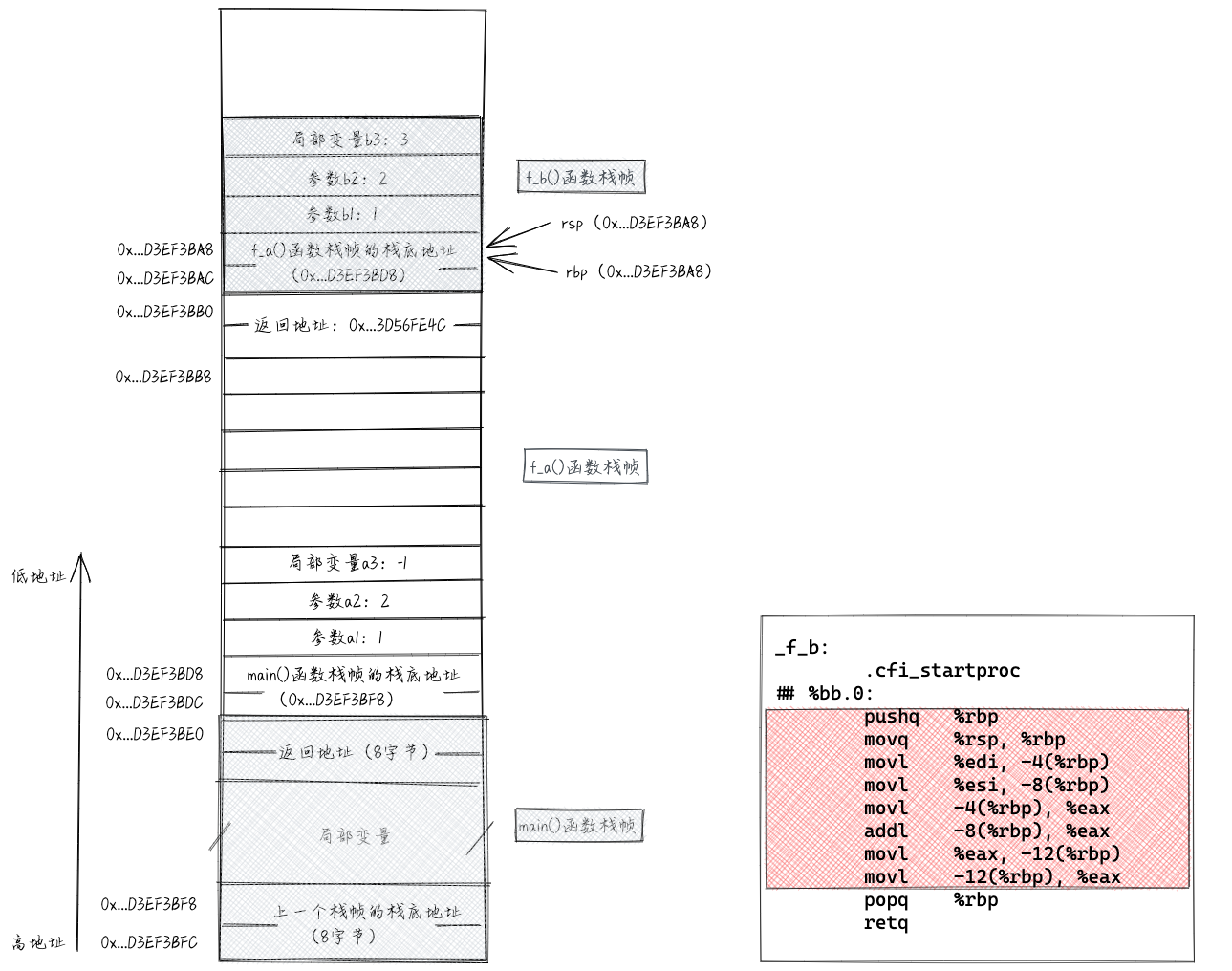
我们重点分析一下f_b()函数中的最后两条指令。
执行"popq %rbp"指令相当于执行了“movq (%rsp), %rbp”和“addq $8, %rsp”。也就是把栈顶的数据(f_a()函数对应栈帧的帧底地址)取出放入rbp寄存器中。执行完popq指令之后,rsp和rbp分别指向f_a函数栈帧的底和顶。相当于将f_b()函数的栈帧弹出栈。具体如下图所示。
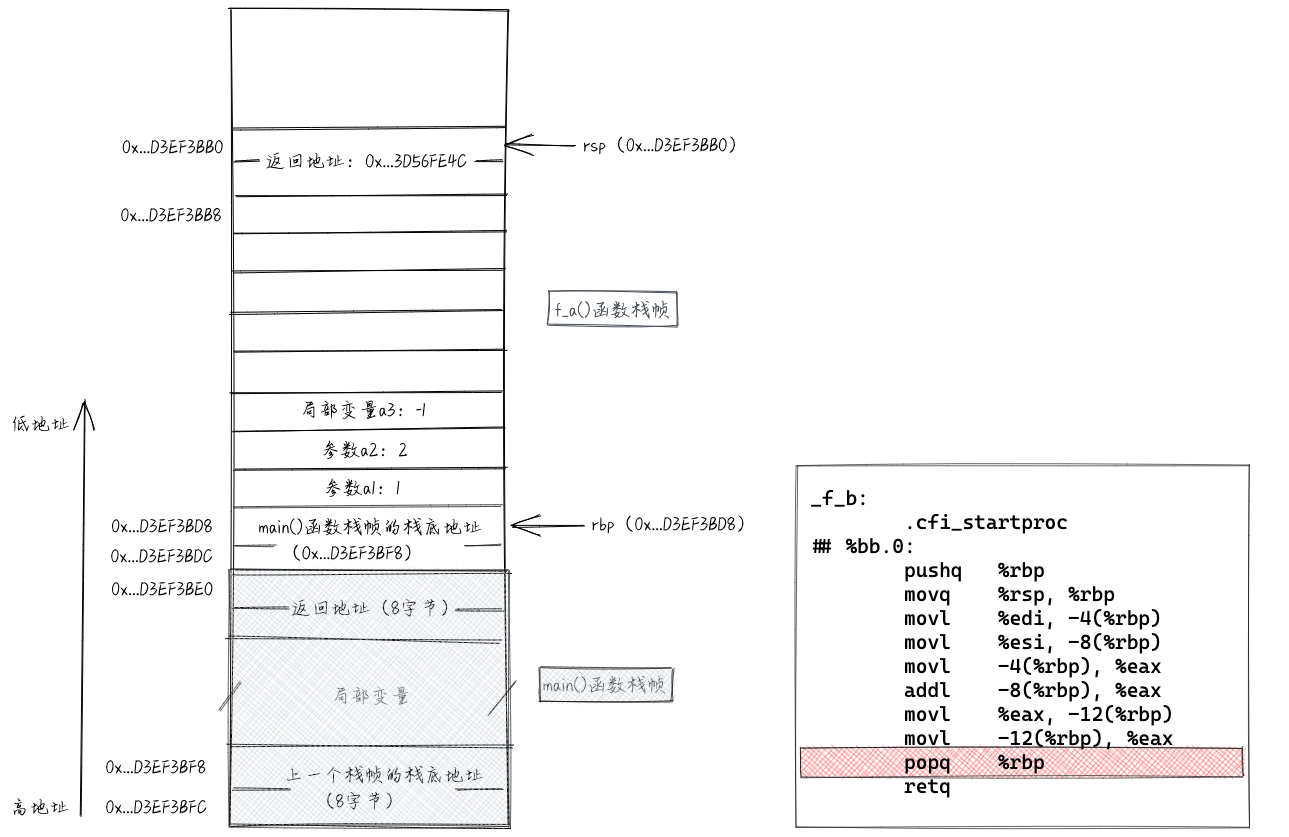
执行“retq”指令相当于执行了“popq %rip”指令,也就是将栈顶的数据(f_a()函数的“返回地址”)取出放入%rip。这样,CPU就跳转去执行f_a()函数中callq指令之后的指令了。执行完retq指令之后,栈相关数据如下图所示。
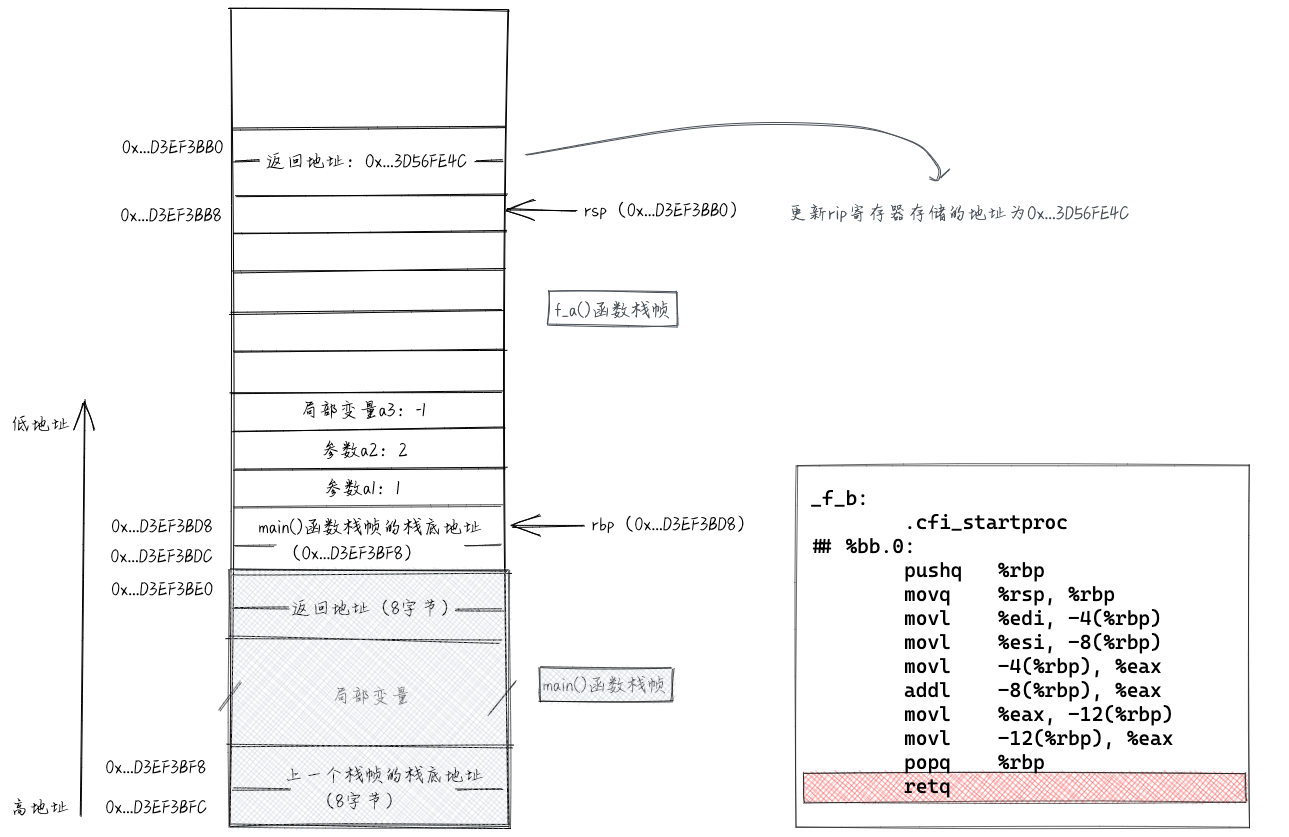
回到f_a()函数之后,执行callq后面的4条指令,将a2-a1的值只写a5中。于是,f_a()函数也就完全执行完了。接下来是移除f_a()函数的栈帧的操作。执行“addq $32, %rsp”指令,将rsp指向如图所示位置。
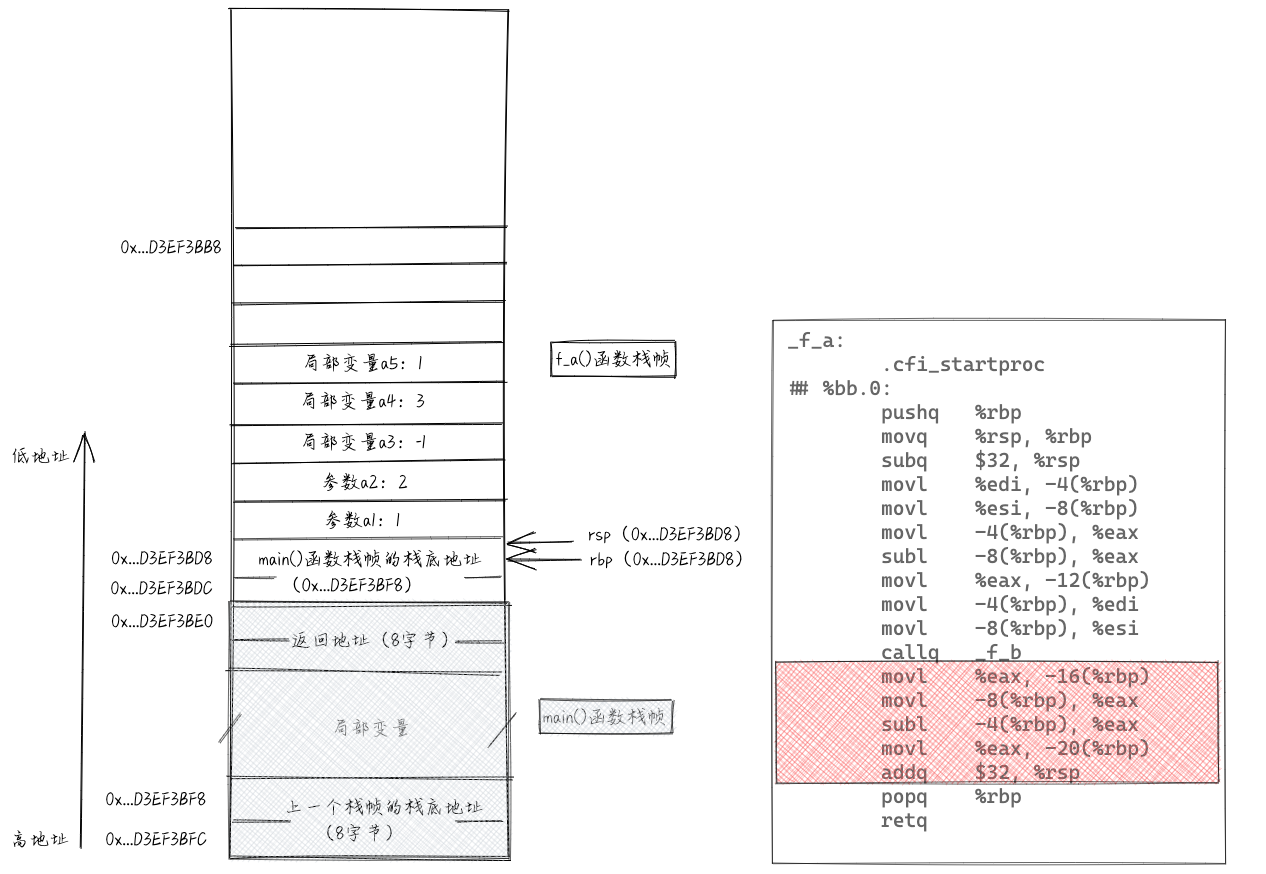
执行“popq %rbp”指令,将栈顶的数据(main()函数的栈帧的帧底地址)赋值给rbp。此时,rsp和rbp指向main()函数的栈帧的帧顶和帧底。相当于将f_a()函数的栈帧弹出栈。
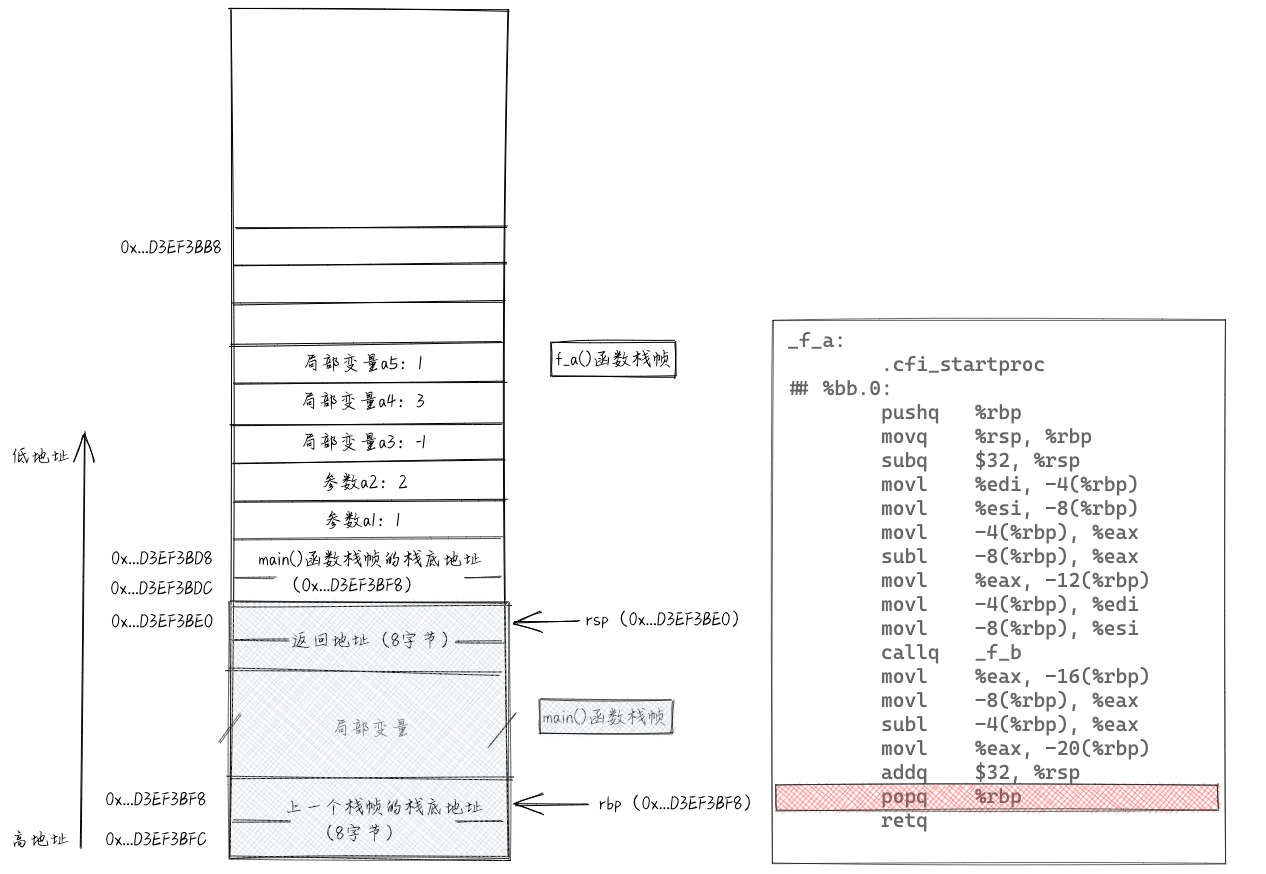
执行“retq”指令,相当于执行“popq %rip”指令,将main()函数的返回地址赋值给rip,CPU跳转执行main()函数中callq之后的指令。
详细分析了代码的执行流程之后,对于前面的3个问题,我们再总结回答一下。
1)栈帧中除了保存局部变量之外,还保存哪些其他数据?
栈帧中依次保存:前一个栈帧的帧底地址,参数,局部变量,返回地址。保存前一个栈帧的帧底地址的目的是,方便当前函数执行完成之后,rbp指针重新指向前一个栈帧的栈底。保存返回地址的目的是,方便当前函数执行完成之后,返回到上层函数继续执行。
2)上一节讲到的SP寄存器和BP寄存器具体用在哪里?
SP寄存器存储栈顶地址,方便将新数据压入栈。BP寄存器存储的是当前栈帧帧底地址,方便基于这个地址的偏移来访问参数、局部变量。
3)CPU在执行完某个函数之后,如何知道应该回到上层函数的哪处再继续执行?
在通过callq指令调用函数时,callq指令会将当前的rip寄存器中的内容(callq指令的下一条指令的内存地址,即返回地址)存储在栈帧的最顶端。当被调用的函数执行完之后,被调用函数的栈帧释放,最后调用retq指令(相当于popq %rip),将返回地址重新赋值给rip,CPU就可以从函数中callq指令的下一条指令继续执行了。
八、课后思考题
1)你熟悉的编程语言中,哪些是静态类型语言?哪些是动态类型语言?
2)我们提到,goto语法在编程语言中被废弃,但为什么汇编语言或机器指令中还保留类似goto语句的jmp指令呢?