引用
引用
同样都是存储地址,为何Java引用比C/C++指针更安全?
本节我们学习一下Java中的引用。我们知道,C/C++中有指针语法,指针用来存储一块内存的首地址。我们通过指针来访问这块内存。Java中没有指针语法,取而代之是引用。那么,Java中的引用和C/C++中的指针有什么区别?同样是存储地址,为什么Java中的引用比C/C++中的指针更安全?
一、Java类型:基本类型 vs 引用类型
Java中的数据类型可以分为两类:基本类型和引用类型。基本类型包括:整型(byte,short,int,long)、浮点型(float,double)、字符型(char)、布尔型(boolean)。引用类型包括类、接口、数组。接下来我们看下,这两种类型的数据在内存中是如何存储的。
1. 基本类型
我们通过一段简单的代码来举例讲解,如下所示。
public class Demo3_1 {
public static void main(String[] args) {
int a = 1;
int b = 2;
a = b;
}
}
在上一节课中讲到,函数的局部变量都存储在栈上,所以,a和b对应的内存单元在栈上,并且对应存储的值为1和2。当执行a=b赋值操作时,将b对应内存单元中存储的值,赋值给a对应的内存单元。如下图所示。
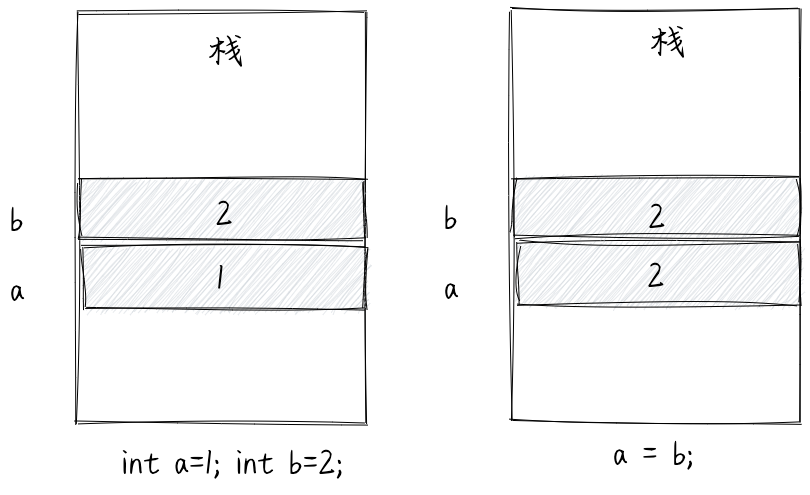
当然,基本类型变量并不一定存储在栈上,如下所示,变量是类的属性,变量作为对象的一部分,存储在堆上。 不过,不管变量存储在哪里,存储结构是不变的(变量对应的内存单元直接存储数据本身)。
public class Demo3_2 {
private int a;
private int b;
public void change() {
a = 1;
b = 1;
a = b;
}
}
函数的局部变量在栈上,类的成员变量的堆上。
2. 引用类型:对象的引用
基本类型数据在内存中的存储方式比较简单,我们再来看下引用类型。还是通过一个例子来讲解,如下所示。
public class Student {
public int id;
public int age;
public Student(int id, int age) {
this.id = id;
this.age = age;
}
}
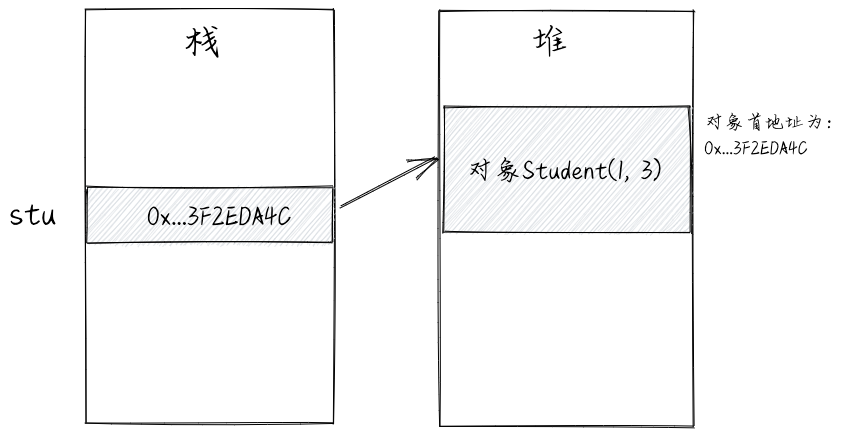
Student stu = new Student(1, 3);
理解引用的关键是分清楚“对象本身”和“对象的引用”,例如,上述代码中,stu变量并非Student对象本身,而是Student对象的引用。它存储的是对象对应内存块的首地址。上述代码对应的内存结构如下所示。在图中,我们使用一个带箭头的指针,来形象化地表示对象的引用与对象本身之间的关系。
我们再通过下面这段代码,理解引用类型的赋值操作。
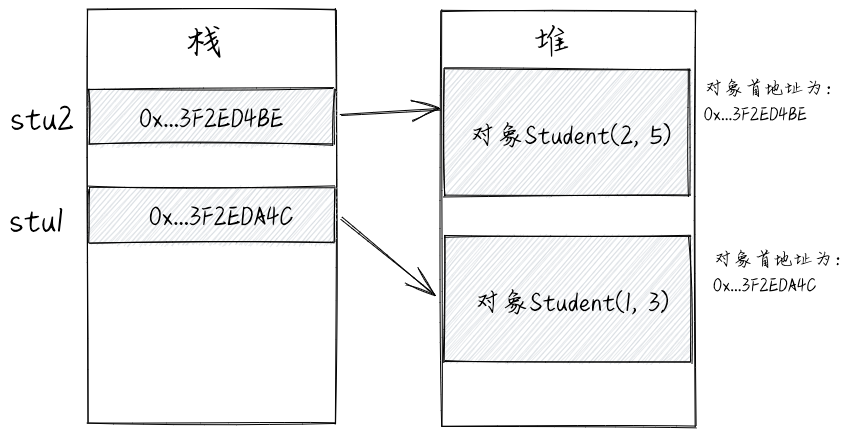
Student stu1 = new Student(1, 3);
Student stu2 = new Student(2, 5);
stu1 = stu2;
在上述代码中,在执行“stu1=stu2”之前,stu1和stu2分别存储了两个不同对象对应内存块的首地址。如下图所示。
执行“stu1=stu2”相当于将stu2对应的内存单元中值,赋值给stu1对应的内存单元。也就是将stu2所引用的对象的首地址赋值给stu1。stu1和stu2引用相同的对象,如下图所示。
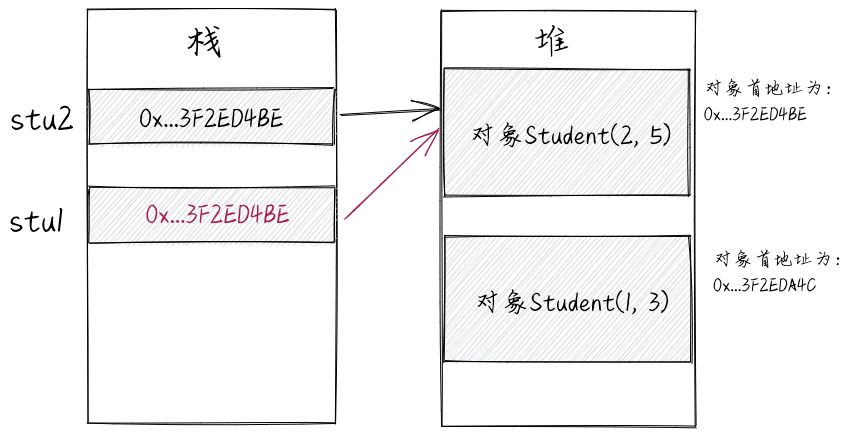
也就是说,一个引用变量可以在不同阶段引用(指向)不同的对象,同一个对象也可以同时被多个引用变量所引用(指向)。
上述代码比较简单,我们再来看个复杂一点的(对象中的属性为引用类型,而非基本类型),以加深对引用的理解。代码如下所示。
public class Group {
public int gradNo;
public int classNo;
public Group(int gradNo, int classNo) {
this.gradNo = gradNo;
this.classNo = classNo;
}
}
public class Student {
public int id;
public int age;
public Group group;
public Student(int id, int age) {
this.id = id;
this.age = age;
}
}
public class Demo3_3 {
public static void main(String[] args) {
Student stu = new Student(2, 5);
stu.group = new Group(2, 3);
}
}
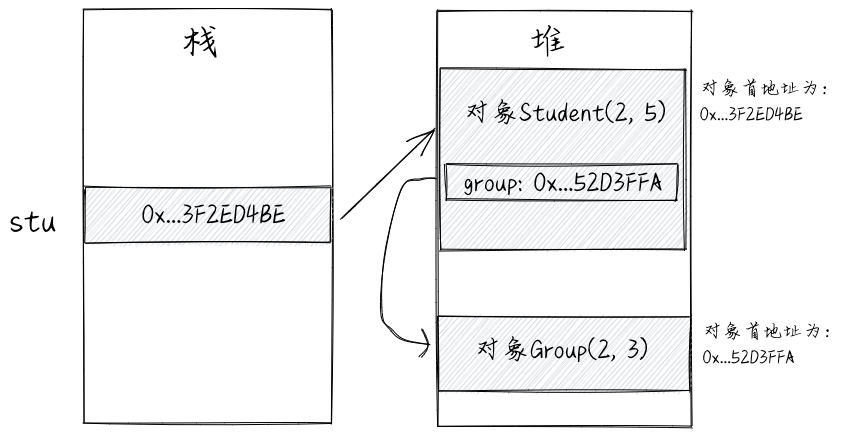
上述代码对应的内存存储结构如下图所示。在stu.group=new Group(2,3)语句执行之前,Student对象的group变量中存储的数据为null(对应到二进制就是0);在stu.group=new Group(2,3)语句执行之后,Student对象的group变量存储的是新创建的Group对象的地址。如下图所示。
3. 引用类型:数组的引用
刚刚介绍的是对象的引用,现在,我们再来看下数组的引用。
数组更加复杂。从数组中存储的数据的类型,我们可以将数组分为基本类型数组和对象数组。基本类型数组指数组中存储的元素是基本类型数据,对象数组指数组中存储的元素是对象。从维度,我们可以将数组分为一维数组、二维数组等。
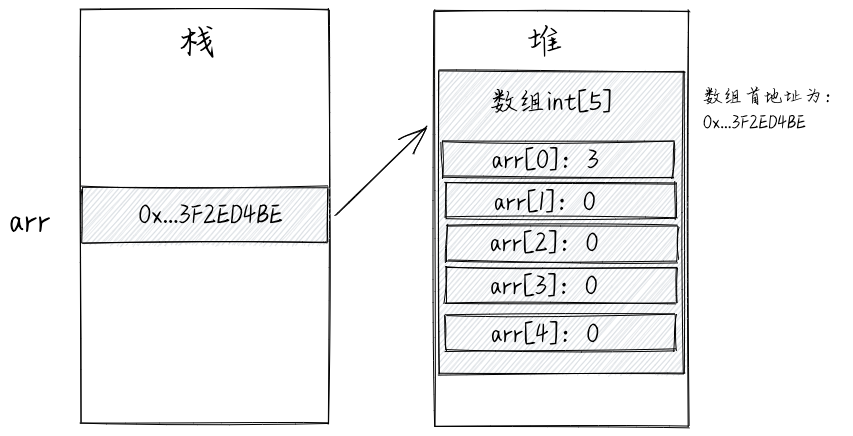
我们先从最简单的一维基本类型数组看起,示例代码如下所示。
int[] arr = new int[5];
arr[0] = 3;
上述代码对应的内存结构如下图所示。数组存储在一块连续的内存单元中。arr是数组的引用而非数组本身,存储数组在内存中的首地址。
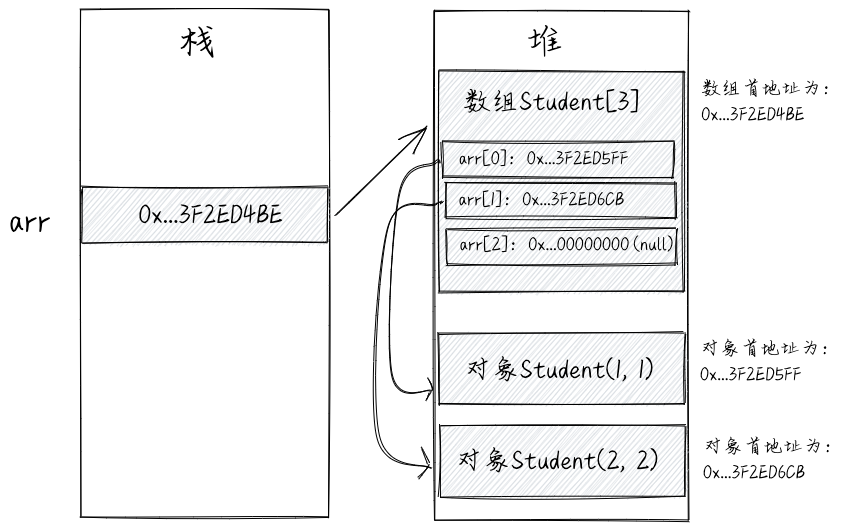
我们再来一下一维对象数组,示例代码如下所示。
Student[] arr = new Student[3];
arr[0] = new Student(1, 1);
arr[1] = new Student(2, 2);
上述代码对应的内存存储结构如下图所示。arr是数组的引用。数组中存储的是对象的引用而非对象本身,换句话说,其存储的是Student对象对应内存块的首地址。
上面讲解的是一维数组,我们再来看下二维数组。
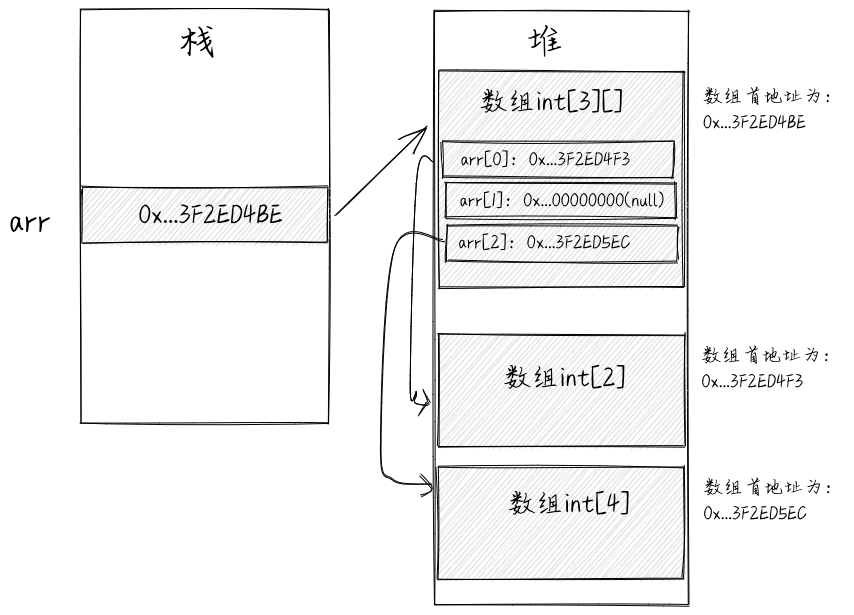
我们在《数据结构与算法之美》中讲到,二维数组中的数据是先行后列(或先列后行),顺序存储在一片连续的内存块中,类似一维数组的存储方式。实际上,每种编程语言都会根据自身语言的特点,对数组的实现方式做了调整。Java中的二维数组不仅不是连续存储的,而且,第二维的长度还可以不同。 我们举例来解释一下。
int[][] arr = new int[3][];
arr[0] = new int[2];
arr[2] = new int[4];
上述代码对应的内存结构如下所示。
上面讲的是二维基本类型数组,我们再来看二维对象数组。示例代码如下所示。
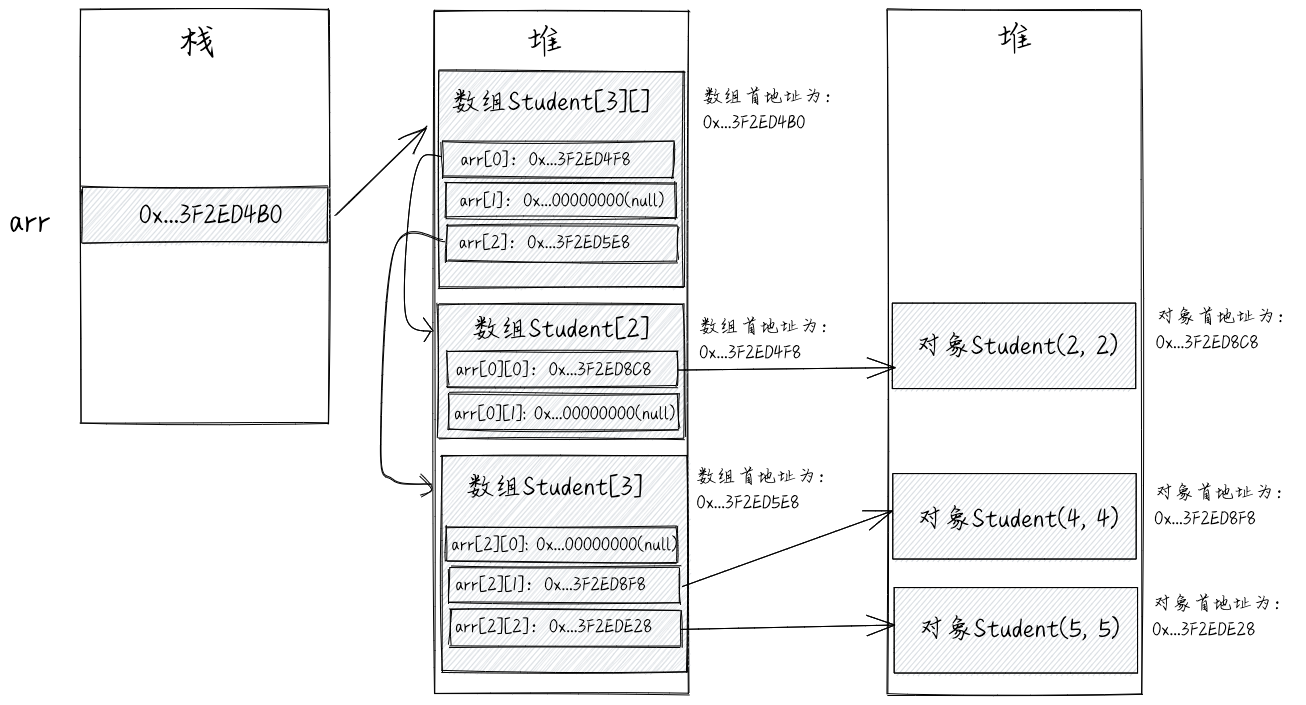
Student[][] arr = new Student[3][];
arr[0] = new Student[2];
arr[0][0] = new Student(2, 2);
arr[2] = new Student[3];
arr[2][1] = new Student(4, 4);
arr[2][2] = new Student(5, 5);
上述代码对应的内存结构如下所示。
很多数据结构与算法的初学者,会觉得链表代码很难理解,主要原因就是对引用的理解不透彻。有了以上对引用的学习,我们再来看下如下链表代码,是不是理解起来更加容易了呢?
public class Node {
public int data;
public Node next;
public Node(int data, Node next) {
this.data = data;
this.next = next;
}
}
public class Demo3_9 {
public void traverse(Node head) {
Node p = head;
while (p != null) {
System.out.println(p.data);
p = p.next;
}
}
public void delete(Node p) { //删除p所指节点的下一个节点
p.next = p.next.next;
}
}
对于上述的代码,我们重点理解“Node p = head”、“p=p.next”、“p.next=p.next.next”这三条语句。
在"Node p = head"这条语句中,p、head都是引用变量(在数据结构中,我们称之为“指针”),并非节点本身,其存储的是节点的内存地址。执行完这条语句之后,p和head存储的值相同,p也指向head所指向的对象,也就是链表的头节点。在形象化表示中,我们用箭头来表示引用变量(指针)和节点之间的引用关系。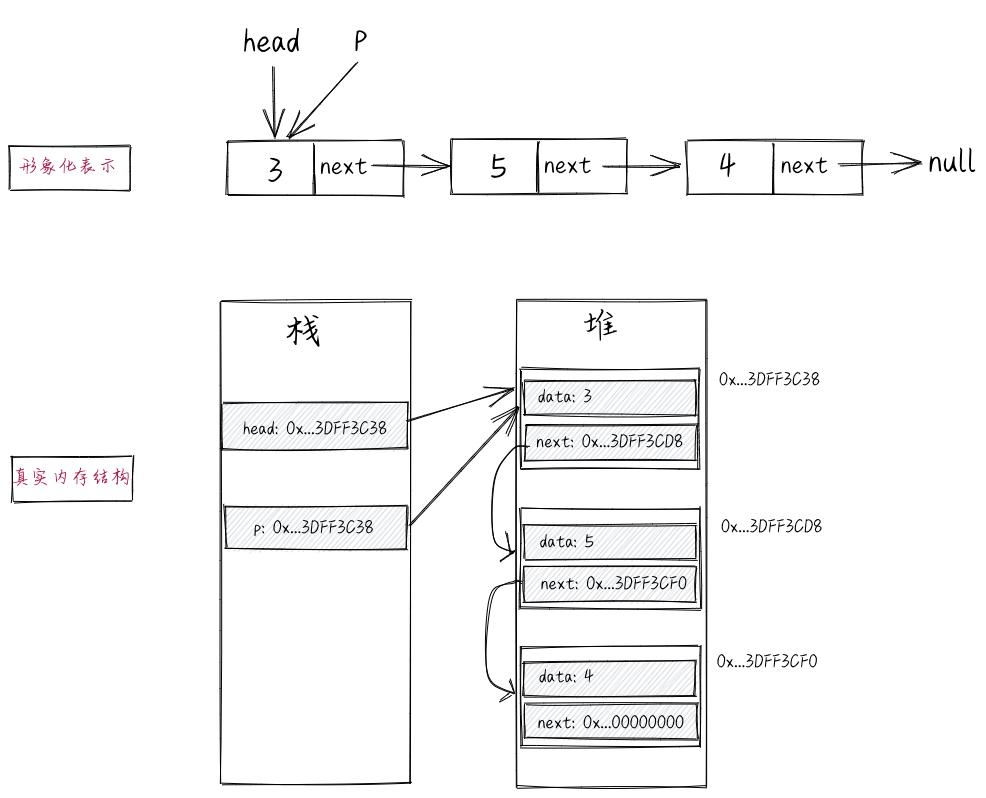
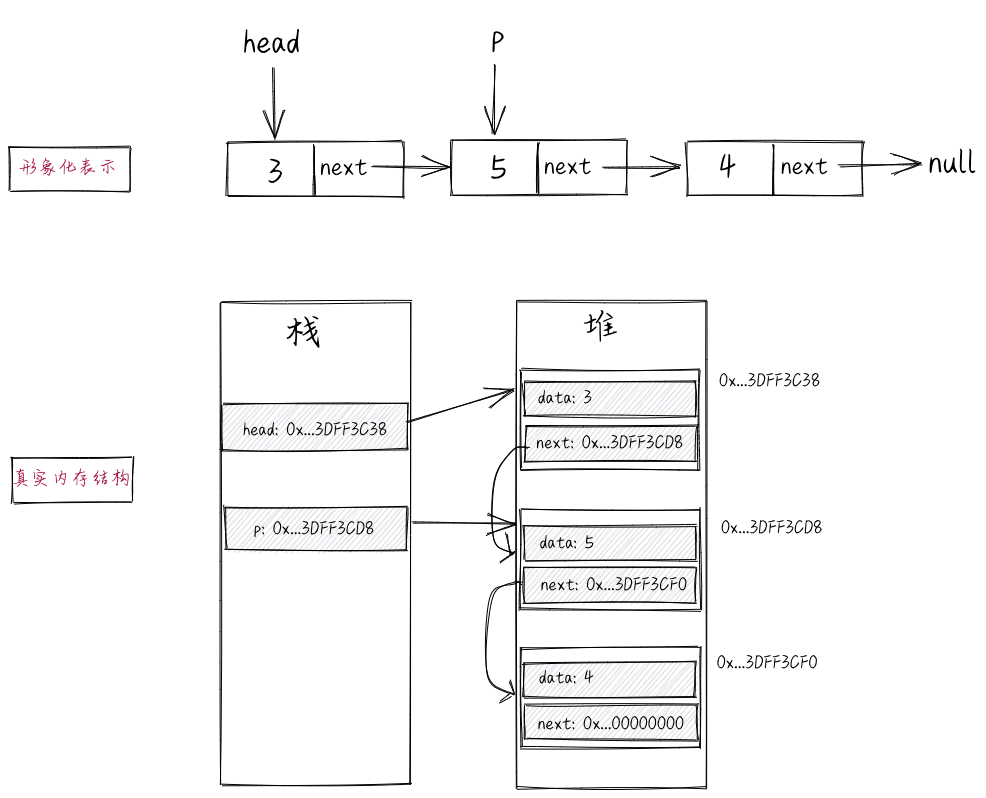
我们再来看“p = p.next”这条语句。“.”操作用来取引用变量所引用的对象的属性。“p=p.next;”这条语句表示:将p所引用的对象的next属性值赋值给p。因为next属性也是引用变量,存储的是p所指节点的下一个节点的内存地址。所以,执行完这条语句之后,p中存储的是下一个节点的地址。如下图所示。
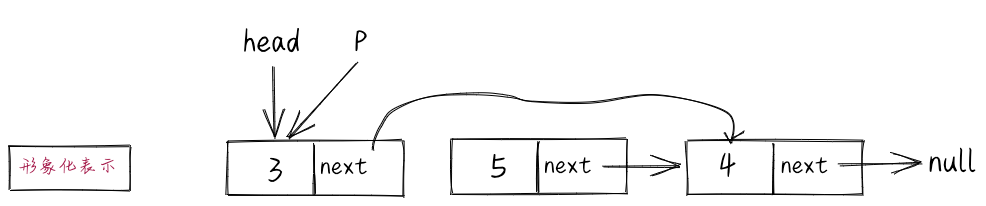
最后,我们来看最复杂的“p.next=p.next.next”语句。如果我们把p所指向的节点叫做当前节点,那么,p.next存储的是下一个节点的地址,p.next.next存储下下个节点的地址。执行这条语句会将下下个节点的地址,赋值给p所指节点的next。于是,p.next存储下下个节点的地址,在图中形象化为指向下下个节点。
二、参数传递:值传递 vs 引用传递
掌握的引用类型数据在内存中的存储方式之后,我们再来看一个在面试中经常问到的一个问题:Java中的参数传递是值传递(pass by value)还是引用传递(pass by reference)?
在回答这个问题之前,我们先来了解一下Java中的参数传递。我们还是分基本类型参数和引用类型参数来讲解。
1. 基本类型参数
我们还是通过一个例子来讲解。代码如下所示。
public class Demo3_5 {
public static void main(String[] args) {
int a = 1;
fa(a);
System.out.println(a); //输出1
}
private static void fa(int va) {
va = 2;
System.out.println(va); //输出2
}
}
在上述代码中,变量a保存在main()函数的栈帧中。va相当于一个新的变量,其保存在fa()函数的栈帧中。fa()函数不能访问main()函数栈帧中的数据,同理,main()函数也不能访问fa()函数栈帧中的数据。通过参数传递,将变量a的值传递给参数va,相当于执行了“va=a”语句。所以,在函数fa()中,对va进行重新赋值,并不会改变变量a的值。
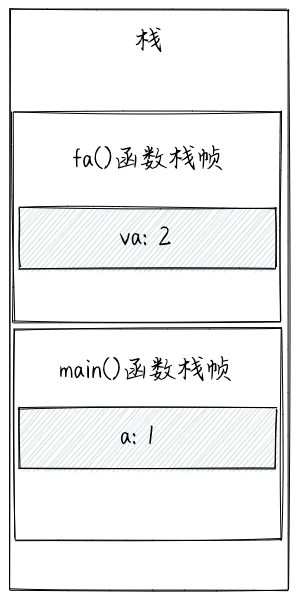
2. 引用类型参数
我们再通过一个例子来看下引用类型。代码如下所示。
public class Demo3_5 {
public static void main(String[] args) {
Student stu = new Student(1, 1);
fa(stu);
System.out.println(stu.age); //输出3
}
private static void fa(Student vstu) {
vstu.age = 3;
}
}
在上述代码中,通过new创建的Student对象存储在堆上,stu是Student对象的引用,存储了Student对象的首地址。stu存储在main()函数栈帧中。vstu是一个引用类型的变量,存储在fb()函数栈帧中。通过参数,将stu中存储的值赋值给vstu,就相当于执行了“vstu=stu”语句。根据前面对引用类型的讲解,执行这条赋值语句之后,vstu对应内存单元中存储的数据跟stu对应内存单元中存储的数据一样,都是Student对象的首地址,也就是说,现在,vstu和stu是同一个Student对象的引用。
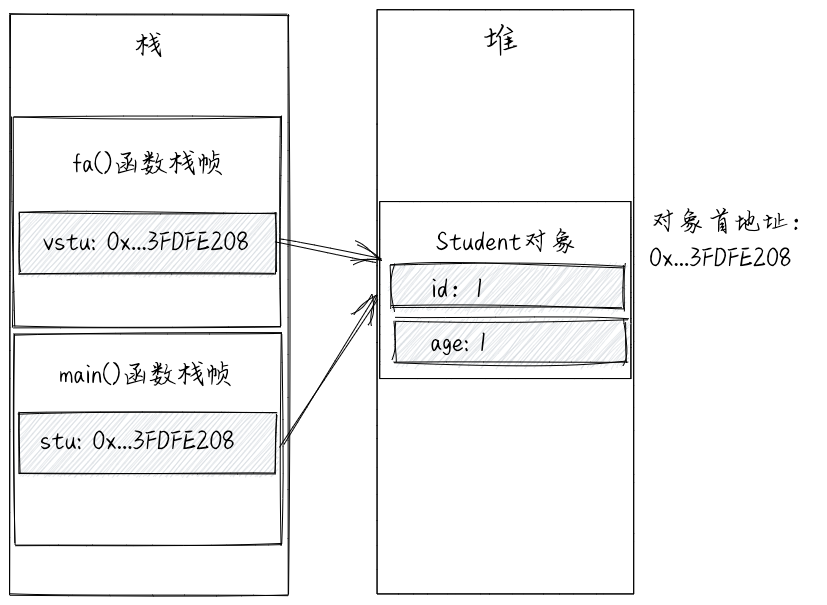
当我们在fa()函数中,执行“vstu.age=3”这条语句时,直接修改了Student对象的属性值,而Student对象存储在堆上,不受函数作用域的影响,在函数内,对所引用的对象的属性的修改,在函数执行完成之后,仍然有效,所以,main()函数中的println()函数的输出结果是修改之后的age值3。
我们再回过头去看刚刚留下的问题:Java中的参数传递是值传递还是引用传递?
教科书版的答案是:值传递。实际上,从上面的讲解中,我们很难得出这样的结果。恰恰相反,Java中的参数既可以是基本类型,也可以是引用类型,给人比较直接的感觉是:Java既支持值传递也支持引用传递。如果读者只了解Java语言,确实很难理解为什么Java中的参数传递是值传递,因为值传递和引用传递的区分来源于C++语言,而且,“引用传递”其中的“引用”的含义,也不是指传递参数的类型是引用类型。
在C++中,我们可以通过“&”引用语法获取到一个变量的地址,也可以将一个变量的地址传递给函数,这样,在函数内对变量修改,函数结束之后,修改不会失效。示例代码如下所示。
// test.cpp
#include <stdio.h>
void change(int &va) {
va = 2;
}
int main(void) {
int a = 1;
change(a);
printf("a=%d\n", a); //输出2
}
在上述代码中,在调用change()函数时,编译器会将a对应内存单元的地址传递给va。编译器将chang()函数中的"va=2"翻译为:将2存储到va中存储的地址对应的内存单元,而不是存储到va对应的内存单元。这样就实现了修改变量a。
C++这种传递参数的方式叫做引用传递,也就是尽管我们在调用函数时,感觉传递是变量本身,但实际上传递的却是变量的地址。你可能会说,Java中的函数可以为引用类型,也可以传递对象的地址啊。从对象的角度来看,传递的确实是对象的地址,但从引用变量本身的角度来看,传递的是引用变量的值(也就是对象的地址)而非引用变量的地址。所以,从引用变量本身来看,即便传递的参数是引用类型,仍然是值传递,而非引用传递。这点不好理解,我们再举例解释一下。代码如下所示。
public class Demo3_6 {
public static void main(String[] args) {
Student stu = new Student(1, 1);
fb(stu);
System.out.println(stu.age); //输出1,stu存储的地址未改变
}
private static void fb(Student vstu) {
vstu = new Student(2, 2);
}
}
从上述代码中,我们可以发现,即便传递的参数是引用类型的,我们也只能改变所引用的对象的属性,而不能改变引用变量本身的值(也就是无法指向新的对象),所以,Java的参数不管是基本类型,还是引用类型,从变量本身来看,传递的都是变量的值,因此,都是值传递的。
三、数据判等:等号 vs equals()方法
在业务开发中,经常有判定数据是否相等的需求,现在,我们就来看下,在Java中的数据是如何判等的。我们还是分基本类型数据和引用类型数据来讲解。
1)基本类型数据判等
基本类型判等比较简单。直接使用等号==,即可判定两个变量的值是否相等,也就是判定两个变量对应的内存单元中存储的数据是否相等。示例代码如下所示。
public class Demo3_7 {
public static void main(String[] args) {
int a = 123;
int b = 123;
System.out.println("a==b: " + (a==b)); //true
}
}
2)引用类型数据判等
引用类型数据的判等,要比基本类型数据复杂的多。引用类型数据有两种判等方式:等号==和equals()方法。
我们先来看用等号判等。
实际上,不管是基本类型数据,还是引用类型数据,等号比较的都是变量对应的内存单元中存储的值是否相等。对于引用变量来说,等号就是判定两个引用变量中存储的地址是否相同,也就是判定两个引用变量所引用的对象是否是同一个。示例代码如下所示。
public class Demo3_7 {
public static void main(String[] args) {
Student stu1 = new Student(1, 1);
Student stu2 = new Student(1, 1);
Student stu3 = stu1;
System.out.println("stu1==stu2: " + (stu1==stu2)); //false
System.out.println("stu1==stu3: " + (stu1==stu3)); //true
}
}
我们再来看用equals()方法判等。
所有的Java类都默认继承自Object类。Object类中的equals()方法的代码实现如下所示。也就是说,如果我们在Java类中没有重写equals()方法,那么使用equals()方法判等,就跟使用等号判等一样了。
public boolean equals(Object obj) {
return (this == obj);
}
不过,JDK中的大部分类都重写了equals()方法。比如,Integer类和String类的equals()方法的代码实现如下所示。
// Integer类的equals()方法
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
// String类的equals()方法
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
重写之后的equals()判定的不再是对象的“址”(内存地址)是否相等,而是对象的“值”(关键属性值)是否相等。比如,Integer类的equals()方法判断的是其int值是否相等;String类的equals()方法判断的是其char数组存储的是否是相同的字符。使用equals()方法对Integer、String类型进行判等的示例代码如下所示。
Integer ia = new Integer(2314);
Integer ib = new Integer(2314);
System.out.println(ia==ib); // false
System.out.println(ia.equals(ib)); //true
String sa = new String("abc");
String sb = new String("abc");
System.out.println(sa==sb); // false
System.out.println(sa.equals(sb)); //true
根据使用习惯,等号一般用来判断对象是否“相同”(同一个对象),equals()一般用来判断对象是否“相等”(业务含义上的相等,比如关键属性值相等)。 因为equals()方法的默认实现是,使用等号判断对象是否“相同”,跟其使用习惯不相符,所以,在平时的开发中,如果需要用到某个类的equals()方法,我们一般都会对它进行重写,将其逻辑改为判断对象是否“相等”。示例代码如下所示。
public class Student {
public int id;
public int age;
public Group group;
public Student(int id, int age) {
this.id = id;
this.age = age;
}
@Override
public boolean equals(Object obj) {
Student stu = (Student)obj;
return this.id == stu.id;
}
}
Student stu1 = new Student(1, 2);
Student stu2 = new Student(1, 2);
System.out.println(stu1==stu2); //输出false
System.out.println(stu1.equals(stu2)); //输出true
一般来说,重写类的equals()方法的同时,也要重写hashcode()方法。 这是为什么呢?如何重写hashcode()方法?如果两个对象的hashcode()值冲突了,该怎么办?这些问题先保留。
四、访问安全:引用 vs 指针
Java的诞生晚于C/C++,所以,它借鉴了C/C++中的很多语法特性,当然也摒弃了C/C++中的很多不足。Java摒弃了C/C++中的指针语法,取而代之,引入了引用语法。尽管指针和引用存储的都是被指或被引用的内存块的地址,但引用却比指针在使用上安全很多。
为了方便编写偏底层的代码(如驱动、操作系统),C/C++赋予指针灵活的操作内存的能力。C/C++允许指针越界访问,允许指针做加减运算,允许指针嵌套(指针的指针),甚至允许 指针将一块内存重新解读为任意类型。
正是因为C/C++指针使用起来非常灵活,对内存的访问几乎没有什么限制,所以,对程序员编写代码的能力要求比较高,稍有不慎就会引入bug,误操作不应该操作的内存区域,造成非常巨大的外延性破坏,从而引起安全问题。
Java语言设计的初衷就是简单易用,所以,权衡安全性和灵活性,Java摒弃了灵活的指针,设计了更加安全的引用,也可以叫做安全指针。尽管指针和引用存储的都是某段内存的地址,但是,在用法上,引用是有限制的指针,没有了那么多酷炫的骚操作。Java中的引用只能引用对象或数组,并且不能进行加减运算,而且,强制类型转化也只能发生在有继承关系的类之间。Java中的引用使用起来非常简单,程序员不容易因此而引入bug。
五、课后思考题
1)你熟悉的编程语言是否支持引用传递?
2)下面这段代码打印的结果是什么?为什么?
public class Demo3_10 {
public static void main(String[] args) {
Integer a = 10;
f(a);
System.out.println(a);
}
public static void f(Integer va) {
va = 3;
}
}