字符串
字符串
除了int、long等基本类型,及其Integer、Long等包装类之外,在项目开发中,字符串也是应用得非常多的数据类型。Java提供了String类,封装了字符数组(char[]),并提供了大量操作字符串的方法,比如toUpperCase()、split()、substring()等。除此之外,Java String也是面试中常考的知识点,比如,Java String为什么设计成final不可变类?早期JDK中的substring()函数为什么会出现内存泄露?intern()方法的作用和底层实现原理是什么?等等。本节我们就来详细聊聊String类型。
一、String的实现原理
在JDK8中,String底层依赖char数组实现,类的定义如下所示。
public final class String
implements java.io.Serializable,
Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
//...省略很多方法...
}
String类实现了Serializable、Comparable、CharSequence这三个接口。
Serializable接口用来表示该类的对象可以序列化和反序列化。关于这个接口,我们在IO/文件章节中详细讲解。
Comparable接口只有一个compareTo()方法,用来比较两个对象的大小。在Comparable接口的实现类中,可以自行定义比较方式。关于这个接口,我们在容器章节中的详细讲解。
CharSequence接口定义了一组操作字符串的方法,比如length()、charAt()、toString()等。StringBuilder、StringBuffer都实现了这个接口。
String类中定义的属性非常少,核心的属性只有value数组和hash。
value数组用来存储字符串,在JDK8中为char类型。JDK9对其进行了优化,将其改为byte类型,关于这点,我们在本节的「String的压缩技术」小节中讲解。接下来,不特殊说明的情况下,我们都是按照JDK8来讲解。
hash属性用来缓存的hashcode,关于hash属性的作用,我们在本节的「String的不可变性」小节中讲解。
尽管String类包含的属性很少,但包含的方法却很多,接下来,我挑了一些需要特殊注意的方法来讲解。
1)构造方法
String对象的构造方法有很多,主要有以下几种。关于这几种构造方法的不同,我们在「String的常量池技术」小节中讲解。
String s1 = "abc"; //字面常量赋值
String s2 = new String("abc");
String s3 = new String(new char[] {'a', 'b', 'c'});
String s4 = new String(s3);
2)运算符
熟悉C++语言的同学应该知道,C++语言支持运算符重载。我们可以在自定义类中,重载运算符,如下代码所示,两个Point对象可以执行加法操作。
#include <iostream>
using namespace std;
class Point{
public:
Point(){};
Point (int x, int y): x(x),y(y) {};
Point operator+(const Point &a) { //运算符重载
Point ret;
ret.x = this->x + a.x;
ret.y = this->y + a.y;
return ret;
}
int x,y;
};
int main() {
Point a(2,4); //不用new也可以创建对象
Point b(5,3);
Point c = a + b; //两个对象相加
cout<< "x :" << c.x << endl;
cout<< "y :" << c.y << endl;
}
Java语言并不支持运算符重载,一来,运算符重载的设计思想来自函数式编程,并不是纯粹的面向对象设计思想。二来,Java语言设计的主旨之一就是简单,所以,摒弃了C++中的很多复杂语法,比如指针和这里的运算符重载。
尽管程序员自己编写的类无法重载运算符,但Java自己提供的String类却实现了加法操作。如下代码所示,两个String对象可以相加。Java这样做,不是自己打自己脸吗?
String sa = new String("abc");
String sb = new String("def");
String sc = sa + sb;
System.out.println(sc); //打印abcdef
实际上,这也是一种权衡之后的结果。String类型作为最常用的类型之一,延续了基本类型及其包装类的设计,也支持加法操作,这样使用起来就比较方便和统一(跟基本类型和包装类的操作统一)。
3)length()
我们先来看下面这段代码,你觉得它的打印结果是什么?
String sd = "a我b你c";
int len = sd.length();
System.out.println(len);
length()方法的返回值是char类型value数组的长度。不管是英文还是中文,均占用一个char的存储空间。所以,上面这段代码的打印结果为5。
对于length()函数,我们再来看这样一个问题:对于一个长度为n的字符串,length()方法的时间复杂度是多少呢?我们来看一下它的源码。
public int length() {
return value.length;
}
String类的length()方法直接调用了value数组的length属性。length是JVM在内存中为数组维护的信息。所以,获取字符串长度的length()方法的时间复杂度为O(1)。
不过,数组的length属性记录的是数组的大小,而非元素个数。如果数组大小为10,但只存储了5个字符,数组的length属性值为10,而非5。String的length()方法(获取value元素个数),之所以可以直接使用数组的length属性值(value数组大小),是因为value数组不存在空余空间,数组大小就等于元素个数。毕竟,String类是不可变类,在创建String对象时,存储什么样的字符串就已经明确了,不再会更改,因此,对于value数组来说,并没有扩展性需求,在创建之初申请的数组大小,跟需要存储的字符串长度相同。
4)valueOf()
Java重载了一组valueOf()方法,可以将int、char、long、float、double、boolean等基本类型数据转化成String类型。如下示例代码所示。
public static String valueOf(boolean b) {
return b ? "true" : "false";
}
public static String valueOf(char c) {
char data[] = {c};
return new String(data, true);
}
public static String valueOf(int i) {
return Integer.toString(i);
}
public static String valueOf(long l) {
return Long.toString(l);
}
public static String valueOf(float f) {
return Float.toString(f);
}
public static String valueOf(double d) {
return Double.toString(d);
}
除了使用valueOf()函数,Java还支持如下方式将基本类型数据转换为String类型。
String sf = "" + 53;
System.out.println(sf); //打印53
前面我们讲到,String重载了+运算符,可以实现两个String对象相加。实际上,String对象还可以跟其他任意类型的对象相加,最终的结果为String对象与其他对象的toString()函数的返回值相加。如下代码所示。
String sx = "abc";
Integer ia = 4;
String sy = sx + ia;
System.out.println(sy); //打印:abc4
Student stu = new Student(1,1);
String sz = sx + stu;
//Student没有重写toString()函数,使用Object的toString()函数
//打印:abcdemo.Student@7852e922
System.out.println(sz);
5)compareTo()
上一节,我们讲到,字符可以比较大小。字符比较大小,是将字符对应的UTF-16二进制编码,重新解读为16位的无符号数,再进行比较的。借助字符比较,字符串比较是,从下标0开始,两个字符串中的相同下标位置的字符一一比较,当遇到第一组不相等的字符时,根据这组字符的大小关系,决定两个字符串的大小关系。当然,如果短字符串跟长字符串的前缀完全相同,那么规定短字符串小于长字符串。
compareTo()方法的具体的代码实现如下所示。如果a字符串小于b字符串,那么a.compareTo(b)返回负数;如果a字符串等于b字符串,那么a.compareTo(b)返回0;如果a字符串大于b字符串,a.compareTo(b)返回正数。
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
6)substring()
substring(int beginInex, int endIndex)方法截取并返回下标在[beginIndex, endIndex)范围内的子串。在JDK7及其以上版本中,substring()方法会生成新的String对象来存储子串,但是,如果传入的beginIndex为0,endInex为字符串的长度,那么substring()会返回字符串本身,不会创建新的String对象。
String s = "abcde";
String substr1 = s.substring(1, 4); //substr1为"bcd"
String substr2 = s.substring(0, 5); //substr2为"abcde"
System.out.println("" + (s == substr2)); //打印true
上述示例中的s、substr1、substr2之间关系如下图所示。
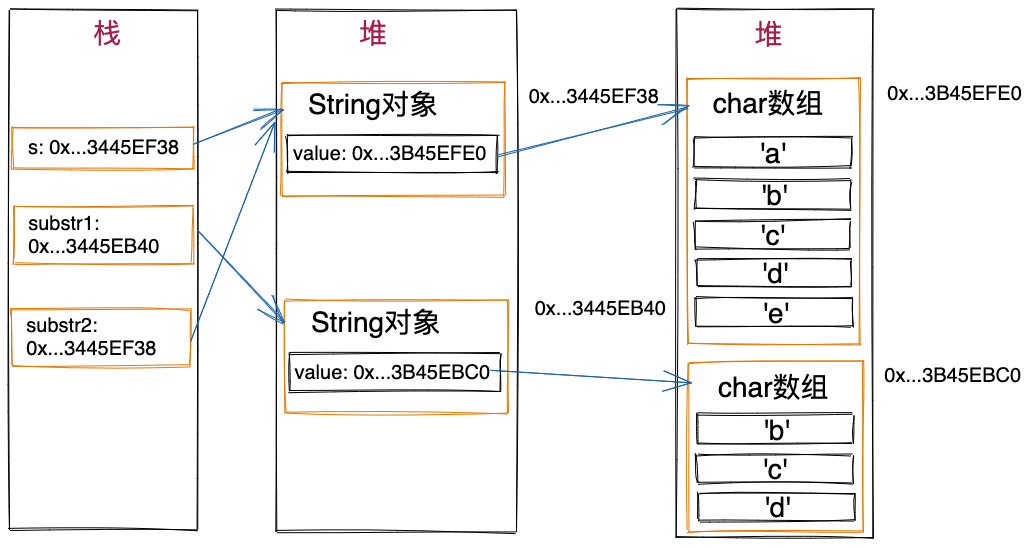
在JDK6及其以前版本中,String类的substring()方法的实现方式会导致内存泄露。尽管这个问题已经在JDK7中修复,现在也很少有项目在用JDK6,但是,为了面试和开阔视野,我们还是介绍一下,JDK6中substring()的实现方法以及产生内存泄露的原因。
在JDK6中,String类的属性要比JDK7中的多。除了char类型的value数组之外,还包含两个int类型的属性:count和offset。通过substring()方法获取到的子串会共享char数组,使用count来标志子串的长度,使用offset来标志子串的起点。示例如下所示。
// value={'a','b','c','d','e'},offset=0,count=5
String s = "abcde";
// value={'a','b','c','d','e'},offset=1,count=3
String substr = s.substring(1, 4); // substr为"bcd"
上述示例中的s和substr的关系如下图所示。你可以拿它跟上图(JDK7中的实现方式)做对比。
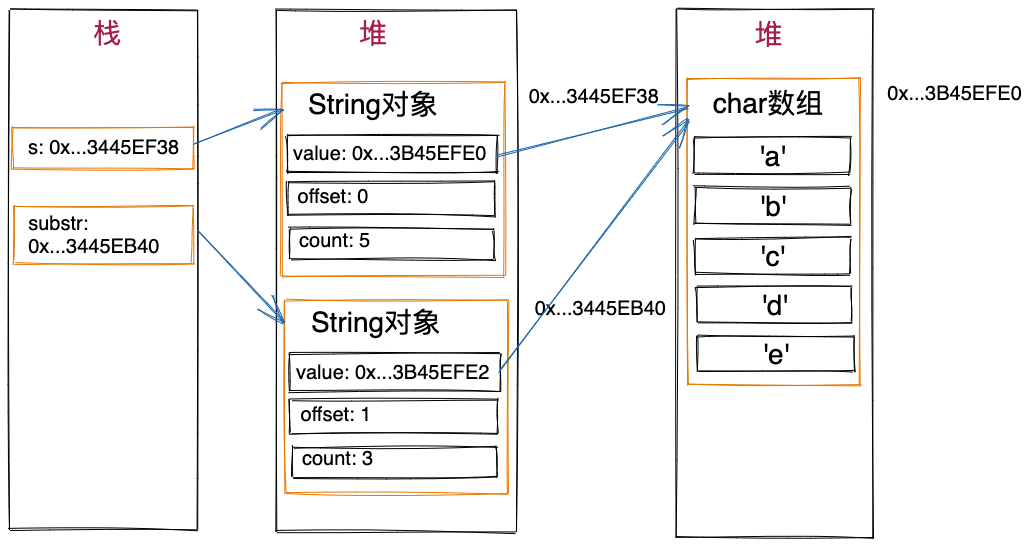
JDK6中substring()的实现方法,比起JDK7的实现方法,不需要拷贝value数组,只需要记录offset和count,更加节省空间,但也正因为如此,存在原始字符串无法被JVM垃圾回收的问题 。 如上代码示例,如果s所引用到String对象中存储的是比较长的字符串,当此长字符串String对象不再被使用时,为了节省内存,尽快让JVM将其垃圾回收,很多程序员会主动将s设置为null(s=null),这样变量s便不再引用这个长字符串String对象,这个长字符串String对象没有变量引用之后,便可以被JVM垃圾回收掉。但事与愿违,即便将s设置为null,但长字符串String对象中的value数组仍然被substr中的value属性所引用,所以,仍然无法被JVM垃圾回收,这跟程序员的预期不符,所以称为内存泄露。
回收String的时候,如果有该String的subString,会回收不成功,导致内存泄露。
当然,在JDK6中,针对substring()方法导致的内存泄露问题,也有相应的解决对策。如下代码所示。其中,对于intern()方法,我们在「String的常量池技术」小节中讲解。
String s = "abcde";
//方法一
String substr = new String(s.substring(1, 4));
//方法二
String substr = s.substring(1, 4) + "";
//方法三
String substr = s.substring(1, 4).intern();
二、String的压缩技术
String类作为在开发中最常用的类型之一,在性能和使用方便程度上,都理应做到极致。前面提到,String类提供了大量操作字符串的方法,就是为了提高使用的方便程度。接下来,我们再来看一下,在String类的性能优化方面,Java主要做了哪些努力。这里,我们侧重存储效率。
前面讲到,在JDK8以及之前的版本中,String类底层依赖char[]来存储字符串。而上一节讲到,char类型存储的是字符的UTF-16编码,一个字符占2个字节长度,所以,存储英文等ASCII码会比较浪费空间。因此,在JDK9中,Java对String类进行了优化,将存储字符串的value数组的类型,由char改为了byte。JDK9中String类的定义如下所示。
public final class String implements java.io.Serializable,
Comparable<String>, CharSequence {
@Stable
private final byte[] value;
private final byte coder;
/** Cache the hash code for the string */
private int hash; // Default to 0
static final byte LATIN1 = 0;
static final byte UTF16 = 1;
//是否使用压缩存储方式,可以通过JVM参数设置为false
static final boolean COMPACT_STRINGS;
static {
COMPACT_STRINGS = true;
}
//...省略大量方法...
}
其中,coder属性的值有两个。一个值是LATIN1,表示String中存储是Latin-1字符,Unicode编号小于等于127,一个字符用一个字节存储。另一个值是UTF16,表示String中存储的字符并非全为Latin-1字符,所以,字符采用UTF-16的两字节编码,1个字符占两个字节。
coder属性的值是通过分析字符串来得到。如果在所存储的字符串中,每个字符对应的UTF-16编码值(2字节编码)都小于等于127,那说明字符串中只包含英文字符。我们就对字符串进行压缩存储,使用1个字节存储1个字符。
String类中的很多操作,比如计算字符串长度的length(),以及根据下标返回字符的charAt(int index)等,都依赖coder属性的值。length()函数和charAt()函数的代码实现如下所示。
public int length() {
//coder=1时,使用UTF-16 2字节编码,字符串长度=value数组大小/2
return value.length >> coder();
}
byte coder() { //COMPACT_STRINGS默认为1,可以通过JVM参数修改
return COMPACT_STRINGS ? coder : UTF16;
}
// coder=0, 1个字节代表1个字符;coder=1,2个字节代表1个字符
public char charAt(int index) {
if (isLatin1()) {
return StringLatin1.charAt(value, index);
} else {
return StringUTF16.charAt(value, index);
}
}
总结一下,String类从JDK6开始,经历了多次优化和重构,如下表所示。
| JDK版本 | JDK6 | JDK7/8 | JDK9 |
|---|---|---|---|
| String类中属性 | char[] value;int offset;int count;int hash; | char[] value;int hash; | byte[] value;int coder;int hash; |
三、String的常量池技术
在前面章节中,我们讲到,Integer、Long等基本类型的包装类,使用常量池技术,缓存常用的数值对象,起到节省内存的作用。String作为常用的数据类型,也效仿了基本类型的做法,设计了常量池,缓存用过的字符串。
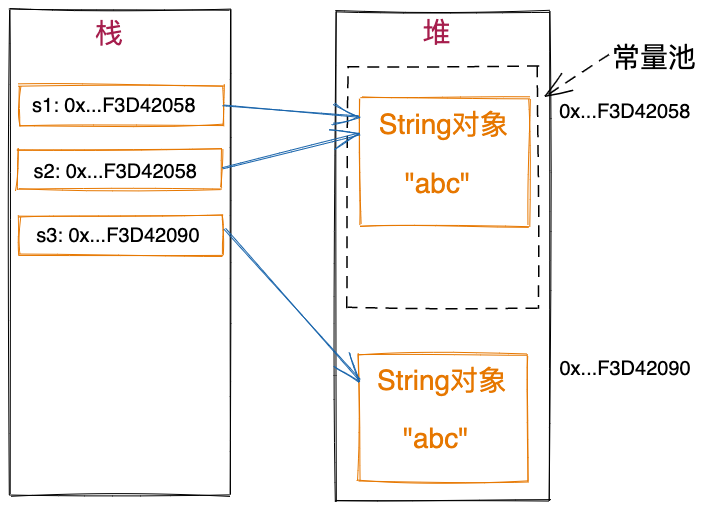
不过,String类型跟Integer等包装类类似,使用new方式创建对象,并不会触发常量池技术,只有在使用字符串常量赋值时,才会触发常量池技术。 如果字符串常量在常量池中已经创建过,则直接使用已经创建的对象。如果没有创建过,则在常量池中创建,以供复用。如下示例代码所示。因为s1和s2引用常量池中相同的String对象,所以第一个打印语句返回true。s3引用在堆上新申请的String对象,所以第二个打印语句返回false。
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc"); //不适用常量池技术
System.out.println(s1==s2); //打印true
System.out.println(s1==s3); //打印false
上述String对象对应的内存存储结构如下所示。在JDK6及其以前版本中,字符串常量池存储在PermGen永久代,在JDK7中,字符串常量池被移动到了堆中。之所以这样做,是因为永久代空间有限,如果常量池中存储的字符串较多,将会产生PermGen OOM错误。关于这一点,我们在JVM模块中详细讲解。
除了使用字符串常量赋值之外,我们还可以使用intern()方法,将分配在堆上的String对象,原模原样在常量池中复制一份。如下示例代码所示。
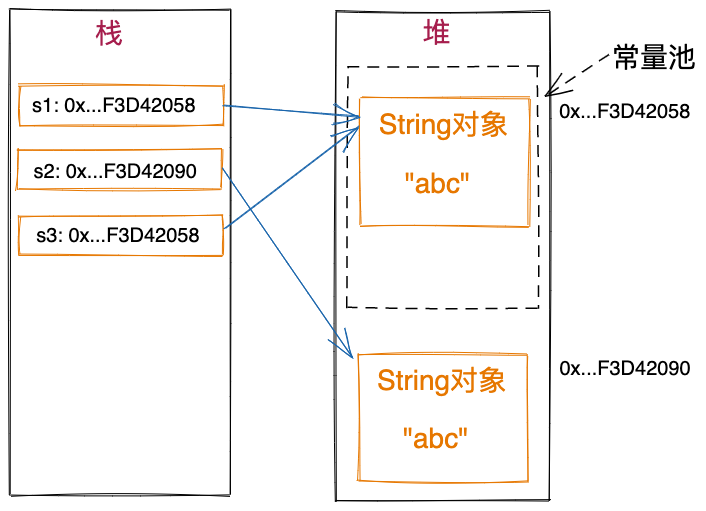
String s1 = "abc";
String s2 = new String("abc");
String s3 = s2.intern();
System.out.println(s1 == s2); //打印false
System.out.println(s1 == s3); //打印true
System.out.println(s2 == s3); //打印false
在上述代码中,s2.intern()语句返回的是字符串“abc”在常量池中的String对象。所以,s1和s3引用相同的String对象。上述String对象对应的内存存储结构如下图所示。
谈一下自己的理解:s1使用了字符串赋值的方式创建对象,触发了常量池,所以"abc"被保存到了常量池中。s2使用了new的方式创建对象,将另一个"abc"创建到了堆上,属于另一个地址;s3是将s2指向的"abc"在常量池中复制一份,但是常量池中已经有了,所以s3和s1指向的地址相同,他俩跟s2指向的地址不同。
在平时的开发中,什么时候使用intern()方法呢?
当我们无法通过字符串常量来给String变量赋值(比如使用现成的API从文件或数据库中读取字符串),但又存在大量重复字符串(比如数据库中有一个“公司”字段,有大量重复值)时,我们就可以将读取到的String对象,调用intern()方法,复制到常量池中。代码中使用常量池中的String对象,原String对象就被JVM垃圾回收掉。示例代码如下所示。
String companyName = dao.query(...).intern();
既然从JDK7开始,String常量池存储在堆中,通过new创建的String对象也存储在堆中,那么,为什么不把通过new创建的String对象,也放到常量池中呢?这样,复用率岂不是更高,更加节省存储空间?
之所以分开存储是因为,在String常量池中创建String对象前,需要先查询此String对象是否已经存在。尽管String常量池组织成类似哈希表一样的数据结构,但查询总是要耗时的,特别当String常量池中的数据太多时,耗时就会增多。不仅如此,创建的过程要将对象放入一定的数据结构中,也要比直接在堆中创建要耗时多。对于没有太多重复的字符串,我们没必要将它放入常量池中。所以,Java提供了灵活的String对象创建方式,由程序员自己决定是否将String对象放入常量池。
四、String的不可变性
String类是不可变类。不可变的意思是:其对象在创建完成之后,所有的属性都不可以再被修改,包括引用类型变量所引用的对象的属性。那么,为什么Java将String设置成不可变类呢?主要有以下几点原因。
1)原因一:常量池
因为String类使用了常量池技术,有可能很多变量会引用同一个String对象。如果String对象允许修改,某段代码对String对象进行了修改,其他变量因为引用同一个String对象,获取到的数据值也紧跟着修改,这样显然不符合大部分的业务开发需求。
2)原因二:哈希
字符串和整型数经常用来作为HashMap的键(key)。在平常的开发中,我们经常将对象的某个String类型或整型类型的属性作为key,对象本身作为value,存储在HashMap中。如果之后属性值又改变了,那么,此对象在HashMap中的存储位置,需要作相应的调整,否则就会导致此对象在HashMap中无法查询。这显然增加了编码的复杂度。
讲到这里,我们再说一下String类中的hash属性。String类定义了自己的hashcode()函数。等到讲到容器的时候,我们会讲到,当将对象存储在HashMap(哈希表)中时,HashMap会调用对象的hashcode()函数来计算哈希值。对于String不可变对象来说,hash值在计算得到之后是不会再改变的,所以,使用一个属性hash来缓存这个值,避免重复计算。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {//h不为0,表示已经计算过
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
3)原因三:包装类的思路
我们前面反复提到,String的设计思想非常贴近基本类型,比如支持+运算符等,所以,基本类型及其包装类都是不可变的,所以,String也延续了它们的设计思路,也设计为不可变的。
五、StringBuilder
因为String是不可变类,当我们在拼接多个字符串时,效率(空间和时间)会比较低。如下代码所示。在for循环中,每次都会创建一个新的String对象,再赋值给s,而并不能直接修改s对应的String对象。所以,下述代码创建了大量的String对象,空间和时间效率都很低。
String s = "a";
for (int i = 0; i < 100000; i++) {
s += "x"; // s = s+"x";创建一个新的对象拼接s和“x”,赋值给s
}
于是,为了解决这个问题,Java设计了一个新的类StringBuilder,支持修改和动态扩容。使用StringBuilder类将上述代码重构,如下所示。这样就避免了for循环创建大量的String对象。
String s = "a";
StringBuilder sb = new StringBuilder();
sb.append(s);
for (int i = 0; i < 100000; i++) {
sb.append("x");
}
s = sb.toString();
在平时的开发中,我们经常使用加号(+)连接多个字符串,实际上,底层就是采用StringBuilder来实现的。如下所示。
String s1 = "abc";
String s2 = "def";
String s3 = "hij";
String s4 = s1 + s2 + s3;
//上一句的底层实现逻辑如下
//String s4 = (new StringBuilder()).append(s1)
// .append(s2).append(s3).toString();
实际上,我们可以把StringBuilder看做是char类型的ArrayList(ArrayList<Character>)。关于StringBuilder的扩容方式,我们在容器部分讲解。
六、课后思考题
在JDK8和JDK9下,这段代码分别打印什么结果?
String latinS = "abc";
System.out.println("" + latinS.getBytes().length);
String utf16S = "王abc争";
System.out.println("" + utf16S.getBytes().length);
有些同学学了本节的内容之后,可能认为上述代码的打印结果在JDK8和JDK9下分别是:6,10 和 3,10,实际上是不对的。提示:研究一下getBytes()获取到是什么?