写时复制
写时复制
提示
为什么JUC只支持数组类型的写时复制并发容器?
上一节,我们对JUC并发容器做了一个框架性介绍,提到了很多并发容器。本节,我们讲解其中的CopyOnWriteArrayList和CopyOnWriteArraySet,它们都是采用写时复制技术来实现,因此,称为写时复制并发容器。从名称,我们可以发现,这两个容器都跟数组有关。那么,为什么JUC没有提供CopyOnWriteLinkedList、CopyOnWriteHashMap等其他类型的写时复制并发容器呢?带着这个问题,我们来学习本节的内容。
一、基本原理
写时复制是一个比较通用的技术,可以应用于很多技术场景中。当应用于并发容器中时,写时复制指的是,当对容器进行写操作(这里的写可以理解为“增、删、改”)时,为了避免读写操作同时进行而导致的线程安全问题,我们将原始容器中的数据复制一份放入新创建的容器,然后对新创建的容器进行写操作中,而读操作继续在原始容器上进行,这样读写操作之间便不会存在数据访问冲突,也就不存在线程安全问题。当写操作执行完成之后,新创建的容器替代原始容器,原始容器便废弃。
我们结合CopyOnWriteArrayList的源码来理解以上写时复制的处理过程。CopyOnWriteArrayList的部分源码如下所示。CopyOnWriteArrayList是ArrayList的线程安全版本,它跟ArrayList一样,也实现了List接口。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable {
final transient ReentrantLock lock = new ReentrantLock();
private transient volatile Object[] array;
public CopyOnWriteArrayList() { this.array = new Object[0]; }
//...省略其他方法...
}
CopyOnWriteArrayList中包含的读写函数非常多。我们拿其中的4个函数作为代表来分析,它们分别是:get()函数、add()函数、remove()函数、set()函数,分别对应读、增、删、改这4个操作。
1)get()函数
get()函数的代码实现如下所示,get()函数实现读操作,代码逻辑非常简单,直接按照下标访问array数组。从代码中,我们可以发现,读操作没有加锁,因此,即便在多线程环境下,效率也非常高。
public E get(int index) {
return (E) this.array[index];
}
2)add()函数
add()函数的代码实现如下所示,add()函数包含写时复制逻辑,因此相对于get()函数,要复杂一些。当往容器中添加数据时,并非直接将数据添加到原始数组中,而是创建一个长度比原始数组大一的数组newElements,将原始数组中的数据拷贝到newElements,然后将数据添加到newElements的末尾。最后,修改array引用指向newElements。除此之外,为了保证写操作的线程安全性,避免两个线程同时执行写时复制,写操作通过加锁来串行执行。也就是说,读读、读写都可以并行执行,唯独写写不可以并行执行。
public boolean add(E e) {
lock.lock();
try {
int len = array.length;
//Arrays.copyOf()底层依赖native方法System.arrayCopy()来实现,比较快速
Object[] newElements = Arrays.copyOf(array, len + 1);
newElements[len] = e;
array = newElements;
return true;
} finally {
lock.unlock();
}
}
3)remove()函数
remove()函数的代码实现如下所示。remove()函数的处理逻辑跟add()函数类似,先通过加锁保证写时复制操作的线程安全性,然后申请一个大小跟原始数组大小相同的新数组newElements。除了待删除数据之外,我们将原始数组中的其他数据统统拷贝到newElements。拷贝完成之后,我们将array引用指向newElements。
public E remove(int index) {
lock.lock();
try {
int len = array.length;
E oldValue = get(array, index);
int numMoved = len - index - 1;
if (numMoved == 0) { //删除array数组的最后一个元素
array = Arrays.copyOf(array, len - 1);
} else { //删除array数组内部的元素
Object[] newElements = new Object[len - 1];
//拷贝array中下标在[0, index-1]之间的元素到newElements
System.arraycopy(array, 0, newElements, 0, index);
//拷贝array中下标在[index+1, len-1]之间的元素到newElements
System.arraycopy(array, index + 1, newElements, index,numMoved);
array = newElements;
}
return oldValue;
} finally {
lock.unlock();
}
}
4)set()函数
set()函数的代码实现如下所示。set()函数的写时复制处理逻辑,跟add()函数、remove()函数的类似,这里就不再赘述了。你可以参看源码了解其实现原理。
public E set(int index, E element) {
lock.lock();
try {
E oldValue = get(array, index);
if (oldValue != element) {
int len = array.length;
//Arrays.copyOf()底层依赖native方法System.arrayCopy()来实现,比较快速
Object[] newElements = Arrays.copyOf(array, len);
newElements[index] = element;
array = newElements;
}
return oldValue;
} finally {
lock.unlock();
}
}
JUC提供的写时复制容器有两个,除了刚刚讲到的CopyOnWriteArrayList之外,还有CopyOnWriteArraySet,从名称上,我们可以看出,CopyOnWriteArraySet具备普通Set所具备的功能。CopyOnWriteArraySet的部分源码如下所示。
public class CopyOnWriteArraySet<E> extends AbstractSet<E> {
private final CopyOnWriteArrayList<E> al;
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public boolean add(E e) {
return al.addIfAbsent(e);
}
public boolean remove(Object o) {
return al.remove(o);
}
public boolean contains(Object o) {
return al.contains(o);
}
}
从上述代码,我们可以发现,CopyOnWriteArraySet实际上是基于CopyOnWriteArrayList实现的,CopyOnWriteArraySet中的函数委托给CopyOnWriteArrayList来实现。我们重点看下contains()函数。在HashSet或者TreeSet中,contains()函数基于哈希表或者红黑树来实现,查询效率非常高。而在CopyOnWriteArraySet中,contains()函数基于数组来实现,需要遍历查询,执行效率比较低。
对写时复制的基本原理有了一定了解之后,我们从读多写少、弱一致性、连续存储这三个特点,再对写时复制进行更深入的探讨。
二、读多写少
从以上给出的CopyOnWriteArrayList源码,我们可以发现,一方面,写操作需要加锁,只能串行执行。另一方面,写操作执行写时复制逻辑,涉及大量数据的拷贝。因此,写操作的执行效率很低。写时复制并发容器只适用于读多写少的应用场景。
如果我们将写时复制容器应用于写操作比较多的场景,那么性能表现将会非常差,如下示例代码所示,执行10000次写入操作,使用CopyOnWriteArrayList容器的耗时为50毫秒,使用ArrayList容器的耗时2毫秒,前者的耗时是后者的20多倍。
public class Demo {
public static void main(String[] args) {
List<Integer> cowList = new CopyOnWriteArrayList<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 10000; ++i) {
cowList.add(i);
}
System.out.println(System.currentTimeMillis()-startTime);
List<Integer> list = new ArrayList<>();
startTime = System.currentTimeMillis();
for (int i = 0; i < 10000; ++i) {
list.add(i);
}
System.out.println(System.currentTimeMillis()-startTime);
}
}
既然CopyOnWriteArrayList只适合读多写少的应用场景,那么,对于写也比较多的应用场景,又该怎么办呢?在《数据结构与算法之美》中,我们讲到,在数组内部进行数据的添加、删除操作,会涉及到大量数据的搬移。也就是说,数组的写操作是一个全局操作,要保证其线程安全性,加锁可能是唯一的解决方案,因此,我们可以使用Java提供的并发容器SynchronizedList。
三、弱一致性
从CopyOnWriteArrayList的源码,我们还可以发现,写操作的结果并非对读操作立即可见。写操作在新数组上执行,读操作在原始数组上执行。因此,在array引用指向新数组之前,读操作只能读取到旧的数据,这就导致了短暂的数据不一致。我们把写时复制的这个特点叫做弱一致性。
在某些业务场景下,弱一致性有可能引起代码bug。我们举例解释一下。如下代码所示,当一个线程调用add()函数添加数据的同时,另一个线程调用sum()函数遍历容器求和,那么,遍历容器求和就有可能存在重复统计的问题。请你思考一下,重复统计是如何产生的呢?
public class Demo {
private List<Integer> scores = new CopyOnWriteArrayList<>();
public void add(int idx, int score) {
scores.add(idx, score); //将数据插入到idx下标位置
}
public int sum() {
int ret = 0;
for (int i = 0; i < scores.size(); ++i) {
ret += scores.get(i);
}
return ret;
}
}
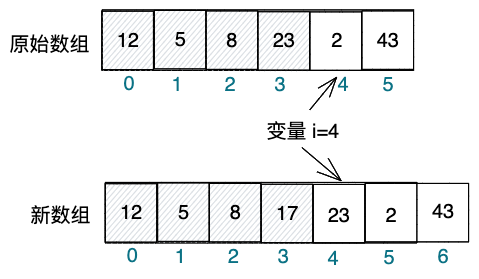
如下图所示。线程A遍历原始数组进行累加,当累加完下标为3的元素23之后,线程B执行add(3, 17)函数,将array引用切换为指向新的数组。此时变量i的值仍然为4,线程A从下标为4的位置开始遍历新的数组,于是,元素23又被遍历累加了一遍。那么,怎么解决重复统计问题呢?
实际上,CopyOnWriteArrayList提供了用来专门遍历容器的迭代器。如下源码所示,在创建迭代器对象时,CopyOnWriteArrayList会将原始数组赋值给snapshot引用,之后的遍历都是在snapshot上进行的,因此,即便array应用切换为指向新的数组,也并不影响到snapshot引用继续指向原始数组。
//位于CopyOnWriteArrayList.java中
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
static final class COWIterator<E> implements ListIterator<E> {
private final Object[] snapshot; //指向原始数组
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
@SuppressWarnings("unchecked")
public E next() {
if (!hasNext()) throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
//...省略其他方法...
}
我们使用迭代器对sum()函数进行重构,重构之后的代码如下所示。
public int sum() {
int ret = 0;
Iterator<Integer> itr = scores.iterator();
while (itr.hasNext()) {
ret += itr.next();
}
return ret;
}
四、连续存储
在本节的开头,我们提到,JUC提供了CopyOnWriteArrayList、CopyOnWriteArraySet,却没有提供CopyOnWriteLinkedList、CopyOnWriteHashMap等其他类型的写时复制容器,这是出于什么样的考虑呢?
在写时复制的处理逻辑中,每次执行写操作时,哪怕只添加、修改、删除一个数据,都需要大动干戈,把原始数据重新拷贝一份,如果原始数据比较大,那么,对于链表、哈希表来说,因为数据在内存中不是连续存储的,因此,拷贝的耗时将非常大,写操作的性能将无法满足一个工业级通用类对性能的要求。而CopyOnWriteArrayList和CopyOnWriteArraySet底层都是基于数组来实现的。数组在内存中是连续存储的。JUC使用JVM提供的native方法,如下所示,通过C++代码中的指针实现了内存块的快速拷贝,因此,写操作的性能在可接受范围之内。
//位于System.java中
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
JUC没有提供非数组类型的写时复制容器,是出于对于一个工业级通用类的性能的考量,而在平时的业务开发中,对于一些读多写少的业务场景,在确保性能满足业务要求的前提下,我们仍然可以使用写时复制技术来提高读操作性能。不过,对于非数组类型的容器,我们需要自己去开发相应的写时复制逻辑。在《设计模式之美》中,当讲解原型设计模式时,我们引入了一个非常贴近实战的示例,展示了如何在HashMap容器之上应用写时复制技术。因为那个示例比较复杂,所以,我们就不重新表述了,这里我们举一个简单一点的例子。
假设系统配置存储在文件中,在系统启动时,配置文件被解析加载到内存中的HashMap容器中,之后HashMap容器中的配置会频繁地被用到。系统支持配置热更新,在不重启系统的情况下,我们希望能较实时地更新内存中的配置,让其跟文件中的配置保持一致。为了实现热更新这个功能,我们在系统中创建一个单独的线程,定时从配置文件中加载解析配置,更新到内存中的HashMap容器中。
对于这样一个读多写少的应用场景,我们就可以使用写时复制技术,如下代码所示,在更新内存中的配置时,使用写时复制技术,避免写操作和读操作互相影响。相对于ConcurrentHashMap来说,读操作完全不需要加锁,甚至连CAS操作都不需要,因此,读操作的性能更高。
public class Configuration {
private static final Map<String, String> map = new HashMap<>();
//热更新,这里不需要加锁(只有一个线程调用此函数),也不需要拷贝(全量更新配置)
public void reload() {
Map<String, String> newMap = new HashMap<>();
//...从配置文件加载配置,并解析放入newMap
map = newMap;
}
}
五、思考题
写时复制是一个通用的技术,请思考一下写时复制技术还可以应用到哪些其他技术场景中?