阻塞等待
阻塞等待
提示
如何实现支持阻塞读写的线程安全队列(阻塞并发队列)?
在讲解条件变量和信号量时,我们留给大家思考如何使用条件变量或信号量来实现阻塞并发队列。本节我们就结合JUC源码来看下工业级的阻塞并发队列,到底是怎么实现的,都有哪些值得我们学习的地方。
一、阻塞并发队列
阻塞并发队列具有两个特点,第一个是线程安全,也就是名称中“并发”的含义,第二个是支持读写阻塞,也就是名称中“阻塞”的含义。读阻塞指的是,当从队列中读取数据时,如果队列已空,那么读操作阻塞,直到队列有新数据写入,读操作才成功返回。写阻塞指的是,当往队列中写入数据时,如果队列已满,那么写操作阻塞,直到队列重新腾出空位置,写入操作才成功返回。阻塞并发队列一般用于实现生产者-消费者模型。
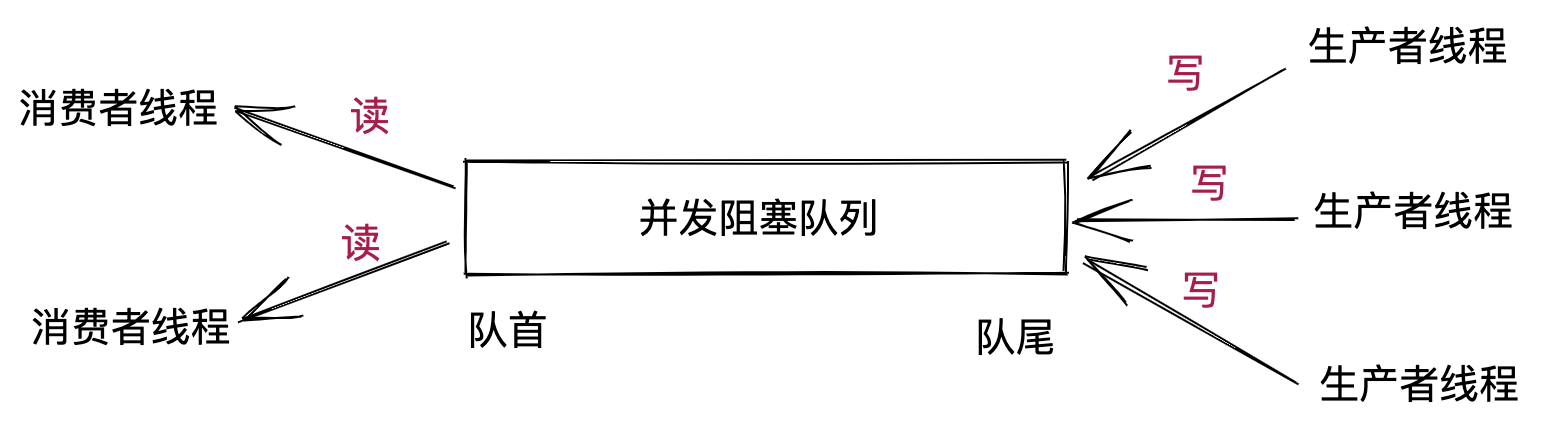
在《数据结构与算法之美》中,我们讲到,队列可以分为无界队列和有界队列。无界队列指的是队列的大小没有限制。有界队列指的是队列的大小有限制。对于有界队列,读、写均可以阻塞。对于无解队列,读可阻塞,但写不会阻塞。
JUC提供的阻塞并发队列有很多,比如ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque、PriorityBlockingQueue、DelayQueue、SynchronousQueue、LinkedTransferQueue。接下来,我们讲解一下这些阻塞并发容器的用法和实现原理。
二、BlockingQueue
ArrayBlockingQueue、LinkedBlockingQueue、LinkedBlockingDeque、PriorityBlockingQueue的实现原理类似,它们都是基于ReentrantLock锁来实现线程安全,基于Condition条件变量来实现阻塞等待,因此,我们把这4个阻塞并发队列放在一起来讲解,并且拿其中的ArrayBlockingQueue重点讲解。对于剩下的3个阻塞并发容器,我们只讲解跟ArrayBlockingQueue有差异的地方。
ArrayBlockingQueue是基于数组实现的有界阻塞并发队列,队列的大小在创建时指定。ArrayBlockingQueue跟普通队列的使用方式基本一样,唯一的区别在于读写可阻塞。这里就不再举例了。接下来,我们结合源码具体讲解它的实现原理,重点看下它是如何实现线程安全且可阻塞的。ArrayBlockingQueue的部分源码如下所示。
public class ArrayBlockingQueue<E>
extends AbstractQueue<E> implements BlockingQueue<E> {
final Object[] items;
int takeIndex; //下一次入队时,数据存储的下标位置
int putIndex; //下一次出队时,出队数据的下标位置
int count; //队列中的元素个数
final ReentrantLock lock; //加锁实现线程安全
private final Condition notEmpty; //用来阻塞读,等待非空条件的发生
private final Condition notFull; //用来阻塞写,等待非满条件的发生
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0) throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
//...省略核心函数...
}
从上述源码,我们还可以发现,ArrayBlockingQueue支持公平和非公平两种工作模式,默认为非公平模式。它的公平性依赖锁的公平性来实现。当线程竞争锁来执行读写操作时,如果此时锁未被持有且锁的等待队列不为空,对于非公平工作模式,线程可以插队竞争锁并执行后续读写操作,对于公平模式,线程会进入等待队列排队等待获取锁。
ArrayBlockingQueue中提供的入队、出队函数有很多,我们重点看下支持阻塞写的put()函数和支持阻塞读的take()函数。其中,put()函数的源码如下所示。put()函数的代码实现是Condition条件变量的标准使用方法:先加锁,为了避免假唤醒,循环调用await()函数等待非满条件的发生,最后执行业务逻辑并解锁。
public void put(E e) throws InterruptedException {
checkNotNull(e);
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await(); //阻塞等待队列非满
enqueue(e);
} finally {
lock.unlock();
}
}
上述put()函数中enqueue()函数的源码如下所示。在下面的代码中,putIndex到达数组的最末尾之后,会重置为0,重新指向数组的开头,因此,我们可以得知,ArrayBlockingQueue是一个循环队列(对循环队列实现原理不清楚的读者,请阅读《数据结构与算法之美》相关章节)。除此之外,put()函数在调用enqueue()函数之前,就已经加了锁并且确保队列非满,因此,enqueue()函数不需要处理线程安全问题以及队列满了的情况。enqueue()函数执行完成之后,队列中添加了新的数据,于是就调用notEmpty条件变量上的signal()函数,唤醒其中一个执行阻塞读的线程。
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal(); //唤醒执行阻塞读,等待队列非空的线程
}
接下来,我们就看下出队操作是如何实现的。对应take()函数的源码如下所示。take()函数代码结构跟put()函数类似,区别在于take()函数调用的是notEmpty条件变量上await()方法,等待非空条件的发生,并且在等到队列真正非空时,执行出队操作,也就是调用dequeue()函数。
public E take() throws InterruptedException {
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
dequeue()函数的源码如下所示。跟enqueue()函数类似,dequeue()函数也不需要处理线程安全问题以及队列为空的情况。当执行完出队操作之后,dequeue()函数调用notFull条件变量上的signal()函数,唤醒其中一个执行阻塞写的线程。
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
notFull.signal();
return x;
}
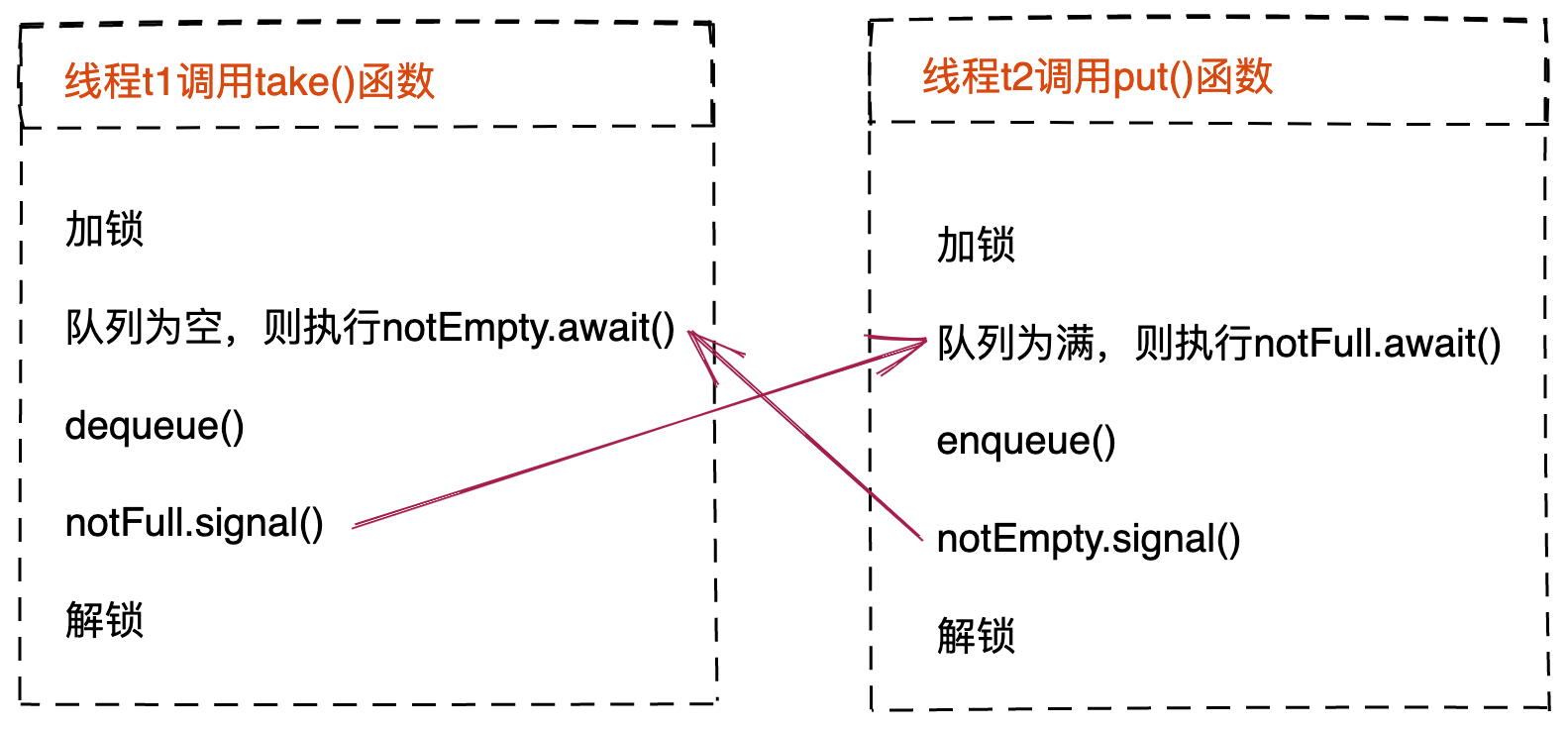
我们对put()函数和take()函数的实现原理做下总结:读操作和写操作互相等待,如下图所示。读操作调用notEmpty上await()等待非空条件发生,执行完成之后,调用notFull上的signal(),唤醒阻塞等待写的线程。写操作调用notFull上的await()等待非满条件的发生,执行完成之后,调用notEmpty上的signal(),唤醒阻塞等待读的线程。
实际上,除了实现支持阻塞的put()函数和take()函数之外,ArrayBlockingQueue还实现了非阻塞的offer()函数和poll()函数。两个函数的代码实现如下所示,它们只通过ReentrantLock锁来保证线程安全,而并没有通过条件变量来实现阻塞读写。
public boolean offer(E e) {
checkNotNull(e);
lock.lock();
try {
if (count == items.length) {
return false;
} else {
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
public E poll() {
lock.lock();
try {
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
详细了解了ArrayBlockingQueue的实现原理之后,我们再来看下跟ArrayBlockingQueue比较类似的LinkedBlockingQueue、LinkedBlockingDeque、PriorityBlockingQueue。
其中,LinkedBlockingQueue是基于链表实现的有界阻塞并发队列,默认大小为Integer.MAX_VALUE,这个值非常大,实际上就相当于无界队列。当然,我们也可以在创建对象时指定队列大小。LinkedBlockingDeque跟LinkedBlockingQueue的区别在于,它是一个双端队列,支持两端读写操作。PriorityBlockingQueue是一个无界阻塞并发优先级队列,底层基于支持扩容的堆来实现,因此,写操作永远都不需要阻塞,只有读操作会阻塞。
这3个并发阻塞队列的实现方式,跟ArrayBlockingQueue的实现方式类似,也是使用ReentrantLock锁来实现读写操作的线程安全性,使用Condition条件变量实现读写操作的阻塞等待。这里就不再展示源码做讲解了。实际上,从这4个并发阻塞队列的实现方式,我们也可以总结得到,利用锁和条件变量,我们可以实现任何类型的并发阻塞容器,比如并发阻塞栈、并发阻塞哈希表等。具体如何实现,作为思考题留给你来完成。
三、DelayQueue
DelayQueue为延迟阻塞并发队列,底层基于优先级队列PriorityQueue来实现,因为PriorityQueue支持动态扩容,因此DelayQueue是无界队列。DelayQueue中存储的每个元素都必须实现Delayed接口,提供延迟被读取时间delayTime,PriorityQueue按照delayTime的大小将元素组织成小顶堆,也就是说,堆顶的元素是delayTime最小的元素,最先出队。
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit unit);
}
我们举个例子解释一下。示例代码如下所示。job1、job2、job3的delayTime分别为1s、2s、3s。线程t1和t2依次执行take()函数时,因为没有元素到期,所以均会被阻塞。当时间过去1s之后,job1到期,线程t1从阻塞中唤醒,读取到job1。当时间过去2s之后,job2到期,线程t2从阻塞中唤醒,读取到job2。这样就实现了一个简单的任务延迟执行框架。
public class Demo {
public static class Job implements Delayed {
private String name;
private long scheduleTime; //millisecond
public Job(String name, long scheduleTime) {
this.name = name;
this.scheduleTime = scheduleTime;
}
public void run() {
System.out.println("I am " + name);
}
@Override
public long getDelay(TimeUnit unit) {
long delayTime = scheduleTime - System.currentTimeMillis();
return unit.convert(delayTime, TimeUnit.MILLISECONDS);
}
@Override
public int compareTo(Delayed o) {
return (int) (this.getDelay(TimeUnit.NANOSECONDS) -
o.getDelay(TimeUnit.NANOSECONDS));
}
}
public static void main(String[] args) throws InterruptedException {
DelayQueue<Job> jobs = new DelayQueue<>();
jobs.put(new Job("job1", System.currentTimeMillis()+1000));
jobs.put(new Job("job2", System.currentTimeMillis()+2000));
jobs.put(new Job("job3", System.currentTimeMillis()+3000));
Thread t1 = new Thread(new JobRunnable(jobs));
Thread t2 = new Thread(new JobRunnable(jobs));
t1.start();
t2.start();
t1.join();
t2.join();
}
private static class JobRunnable implements Runnable {
private DelayQueue<Job> jobs;
public JobRunnable(DelayQueue<Job> jobs) { this.jobs = jobs; }
@Override
public void run() {
try {
Job job = jobs.take();
job.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
因为put()函数不支持阻塞,实现比较简单,只是通过加锁保证线程安全,所以,我们重点看下比较复杂的支持阻塞的take()函数。take()函数的源码如下所示。
public E take() throws InterruptedException {
lock.lockInterruptibly();
try {
for (;;) { //自旋,以免假唤醒
E first = q.peek();
if (first == null) available.await(); //put()函数会调用signal()唤醒它
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0) return q.poll(); //元素到期被读取
if (leader != null) { //非leader线程
available.await();
} else { //leader线程
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay); //等待delay时间自动唤醒
} finally {
if (leader == thisThread) leader = null;
}
}
}
}
} finally {
//唤醒非leader线程
if (leader == null && q.peek() != null) available.signal();
lock.unlock();
}
}
实际上,take()函数包含两部分独立的逻辑:针对leader线程的逻辑和针对非leader线程的逻辑。如下图所示,如果多个线程先后调用take()函数,那么,第一个线程就是leader线程,剩下的线程为非leader线程。第一个线程执行读取操作完成之后,第二个线程便成为leader线程。非leader线程的处理逻辑比较简单,直接调用await()函数阻塞,等待leader线程读取完成之后调用signal()函数来唤醒。leader线程的处理逻辑比较复杂。leader线程读取的是队首的元素。如果队首元素的delayTime大于0,那么,leader线程会调用awaitNanos()阻塞delayTime时间。当delayTime时间过去之后,leader线程自动唤醒,为了避免假唤醒(假唤醒来自于其他线程插队读取,待会讲解),leader线程会检查队首元素的delayTime是否真正变为小于等于0,如果是,则将队首元素出队,并且调用signal()唤醒第二个线程,第二个线程于是就成了leader线程,执行以上leader线程要执行的逻辑。
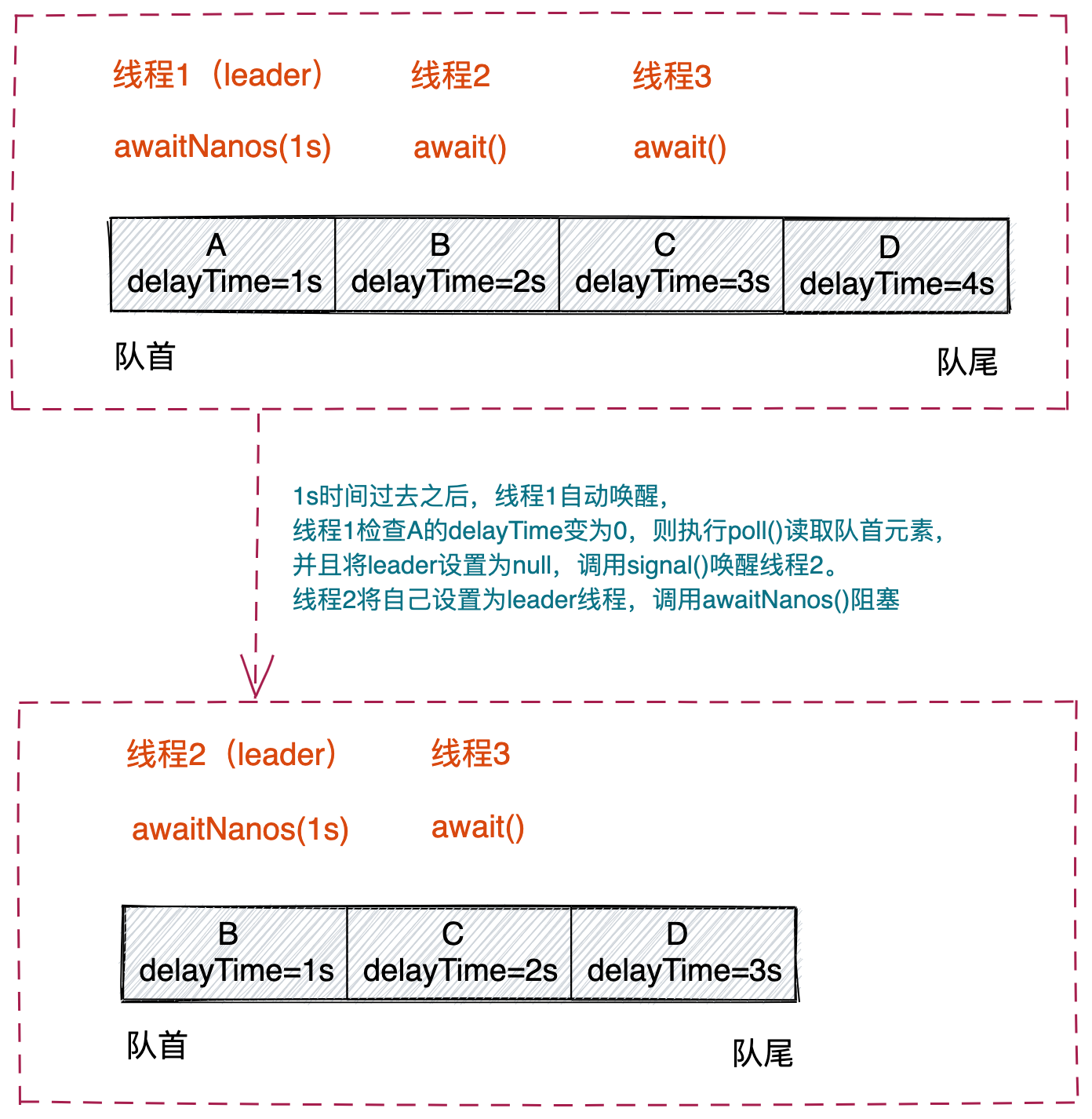
实际上,通过take()函数的源码,我们还可以发现,take()函数的处理过程存在插队的行为。当一个线程执行take()函数时,如果检查发现队列不为空,并且队首元素的delayTime小于等于0,于是,不管是否有其他线程在调用await()或awaitNanos()阻塞等待,这个线程都会直接读取队首元素并返回。
四、SynchronousQueue
SynchronousQueue是一个特殊的阻塞并发队列,用于两个线程之间传递数据,线程执行put()操作必须阻塞等待另一个线程执行take()操作,也就是说,SynchronousQueue队列中不存储任何元素。因为在平时的开发中,SynchronizedQueue很少用到,所以,我们不对其实现原理做深入分析,只对其用法做一个简单介绍,如下示例代码所示。
//示例代码先后输出:sleep done! take done! put done!
public class Demo {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue<String> sq = new SynchronousQueue<>();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
try {
sq.put("a");
System.out.println("put done!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread.sleep(3000);
System.out.println("sleep done!");
sq.take();
System.out.println("take done!");
}
}
五、LinkedTransferQueue
LinkedTransferQueue是一个基于链表实现的无界阻塞并发队列,它是LinkedBlockingQueue和SynchronousQueue的综合体,既实现了LinkedBlockingQueue的功能,又实现了SychronousQueue的功能。LinkedTransferQueue提供的transfer()函数,跟SynchronousQueue中的put()函数的功能类似。调用transfer()函数的线程会一直阻塞,直到数据被其他线程消费才会返回。同样,在平时的开发中,LinkedTransferQueue用到的也比较少,我们对其实现原理也不做深入分析,我们只简单介绍一下它的用法,示例代码如下所示。
// 示例代码先后输出:put done! sleep done! take done! transfer done!
public class Demo {
public static void main(String[] args) throws InterruptedException {
LinkedTransferQueue<String> ltq = new LinkedTransferQueue<>();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
ltq.put("a"); //不需要阻塞等待
System.out.println("put done!");
try {
ltq.transfer("b"); //等待b被读取才返回
System.out.println("transfer done!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread.sleep(3000);
System.out.println("sleep done!");
ltq.take(); //读取put()写入的数据
ltq.take(); //读取tranfer()写入的数据
System.out.println("take done!");
}
}
六、思考题
请借鉴阻塞并发队列的实现方式,实现阻塞并发栈和阻塞并发哈希表。