并发容器
并发容器
提示
如何实现线程安全的数组、链表、哈希表等常用数据结构?
为了方便开发,Java提供了很多容器,比如ArrayList、HashMap、TreeSet等,底层对数组、哈希表、红黑树等常用的数据结构进行了封装。在开发时,我们直接使用这些现成的容器即可,不需要重新从零去开发。对于这些封装了常用数据结构的容器,在多线程环境下,我们如何来保证它们的线程安全性呢?
依靠程序员自己去编写代码,比如对操作加锁,来维护容器的线程安全性,一来耗费开发时间,二来性能没有保证。为了解决这个问题,JUC针对常用的容器,对应开发了高性能的并发容器。在多线程编程中,我们直接使用这些现成的并发容器即可。
从本节开始,我们就来详细讲解一下,JUC并发容器的用法和实现原理。在正式开始之前,本节先对JUC并发容器做一个框架性的介绍,让你对JUC并发容器有一个系统性的认识。
一、Java容器回顾
在讲解JUC并发容器之前,我们先来回顾一下Java提供的普通容器,也就是JCF(Java Collections Framework)。在第11节中,我们将Java容器简单分为以下5类。
1)List(列表):ArrayList、LinkedList、Vector(废弃)
2)Stack(栈):Stack(废弃)
3)Queue(队列):ArrayDeque、LinkedList、PriorityQueue
4)Set(集合):HashSet、LinkedHashSet、TreeSet
5)Map(映射):HashMap、LinkedHashMap、TreeMap、HashTable(废弃)
在上述Java容器中,除了Vector、Stack、HashTable之外,绝大部分容器在设计实现时都没有考虑线程安全问题。Vector、Stack、HashTable这三个容器是JDK1.0引入的。在JDK1.2引入完善的JCF之后,这三个容器就被废弃了,只是为了兼容老的Java项目代码,Java并没有将这三个容器直接从JDK中移除而已。在平时的项目开发中,我们尽量不要使用这三个类。
二、Java并发容器
为了更符合程序员的开发习惯,JCF将非线程安全容器和线程安全容器(也就是并发容器)分开来设计实现。在非多线程环境下,我们使用没有加锁的非线程安全容器,性能更高。例如,替代Vector,JCF设计了非线程安全的ArrayList。在多线程环境下,我们使用Collections工具类提供的并发方法(如synchronizedList()),将非线程安全容器(如List)转换为线程安全容器(如SynchronizedList)来使用。
Java提供的并发容器有以下几种。
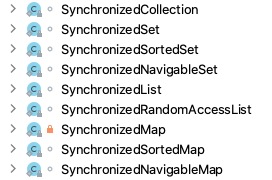
以上容器都是Collections类的内部类。我们一般通过Collections类提供的以下工具方法来创建并发容器的对象。

我们拿SynchronizedList举例讲解,我们通过synchronizedList()方法来创建SynchronizedList对象,具体的创建方法如下所示。
List list = Collections.synchronizedList(new LinkedList<>());
Java并发容器的底层实现原理非常简单,跟Vector、Stack、HashTable类似,都是通过对方法加锁来避免线程安全问题。我们拿SynchronizedList举例讲解,其源码如下所示。所有的函数都使用synchronized加了锁。实际上,我们还可以使用ReentrantReadWriteLock替代synchronized来提高代码的并发性能。
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
static class SynchronizedList<E>
extends SynchronizedCollection<E> implements List<E> {
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
public boolean equals(Object o) {
if (this == o)
return true;
synchronized (mutex) {return list.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
//...省略其他方法...
}
三、JUC并发容器
从上述SynchronizedList的源码,我们可以发现,Java提供的并发容器的代码实现非常简单,但同时也因为锁粒度大而导致并发性能不高。于是,JUC便实现了一套更高性能的并发容器。JUC并发容器之所以比Java并发容器性能更高,是因为JUC利用分段加锁、写时复制、无锁编程等技术对并发容器做了全新的实现,并非像Java并发容器那样只是对原有Java容器简单加锁。当然,从代码实现复杂度上,JUC并发容器的代码实现要比Java并发容器的代码实现复杂得多。
JUC提供的并发容器如下图所示,我们对其进行了简单的分类。
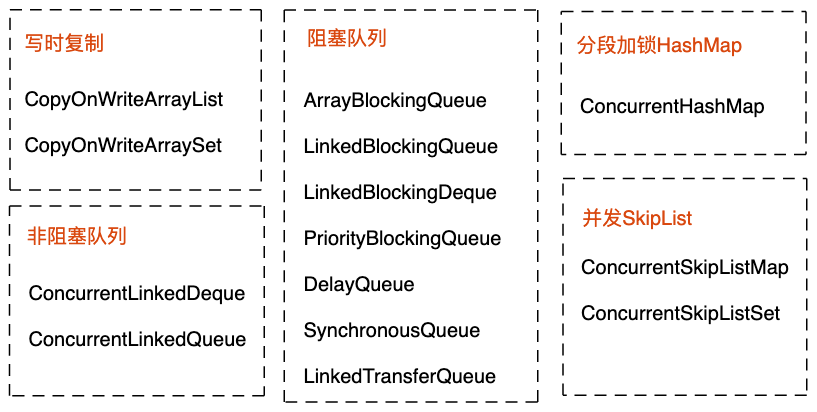
从上图中,我们可以发现,JUC提供的并发容器并不能跟Java容器一一对应,也就说,有些Java容器在JUC并没有对应的线程安全版本,比如LinkedList。相反,Java提供的并发容器是可以跟Java容器一一对应的,任何一个Java容器都可以使用Collections类提供的synchronizedXXX()函数转化为线程安全版本。
对于部分Java容器,之所以JUC没有提供对应的并发容器,是因为对于这些容器,JUC无法通过非加锁方式(比如无锁编程、写时复制、分段加锁)来提高并发性能,无法提供比Java并发容器更高性能的并发容器。对于这部分Java容器,在多线程环境下,我们要么使用Java提供的并发容器,要么使用替代的JUC并发容器。比如,对于LinkedList,我们只能使用Java提供的并发容器SynchronizedList。而对于TreeSet和TreeMap,尽管JUC没有提供对应的并发容器,但是我们可以使用ConcurrentSkipListSet和ConcurrentSkipListMap,它们在功能上完全可以替代TreeSet和TreeMap,既支持快速查找,又支持有序遍历。除此之外,对于栈这种数据结构,其完全可以被双端队列(Deque)替代,因此,不管是在JDK1.2之后的JCF中,还是JUC中,都没有提供栈相关的容器。
四、思考题
Java废弃Vector、Stack、HashTable这三个容器的主要原因是什么呢?提示:废弃的主要原因并非是因为它们的并发性能低。