ConcurrentHashMap
ConcurrentHashMap
提示
分段加锁:HashMap线程不安全的原因及ConcurrentHashMap的实现
HashMap是在开发中经常用到的容器,但是,它不是线程安全的,只能应用于单线程环境下。在多线程环境下,Java提供了线程安全的HashTable、SynchronizedMap,但是,两者因为采用粗粒度锁来实现,并发性能不佳。于是,JUC便开发了ConcurrentHashMap,利用分段加锁等技术来提高并发性能。本节,我们就来详细讲解一下ConcurrentHashMap的实现原理,这也是面试中经常被问到的地方。
这里特别声明一下,HashMap和ConcurrentHashMap在JDK7和JDK8中的实现方式均有较大差别,在本节中,我们参照JDK8中的实现方式来讲解。
一、HashMap线程不安全分析
在讲解ConcurrentHashMap之前,我们先要搞清楚,为什么HashMap是非线程安全的?
前面讲到,线程安全问题产生的原因是竞态读写共享资源。对于HashMap来说,共享资源就是table数组及其table数组中的链表。HashMap提供的读写函数有很多,我们拿get()、put()这两个常用的函数来分析。get()函数包含读操作,put()函数除了包含写操作之外,还包含扩容和树化这两个操作,因此,接下来,我们就通过分析读、写、扩容、树化这4个操作之间竞态执行的线程安全性,以此来分析HashMap的线程安全性。
1)读操作与读操作、写操作、扩容、树化之间是否线程安全?
读操作和读操作之间显然不存在线程安全问题。实际上,读操作和写操作之间也不存在线程安全问题。写操作将数据添加到table数组中对应的链表的尾部,读操作从头遍历链表,两者并不冲突。
读操作和扩容之间存在线程安全问题。扩容的大致处理流程如下代码所示。在进行扩容时,HashMap会申请一个新的table数组。HashMap会先更新table引用指向新的table数组(newTable),然后再将旧的table数组(oldTable)中的链表节点一点一点搬移到新的table数组(newTable)。读操作一直在table引用所指向的table数组上进行,这就会导致在扩容初期某些数据还没来得及搬移到新的table数组而无法读取到。当然,HashMap也可以先搬移数据,再更新table引用,但这仍然无法解决线程安全问题。
public class HashMap {
private Node<K, V>[] table; //table引用
public resize() {
Node<K, V>[] oldTable = this.table;
Node<K, V>[] newTable = new Node<K, V>[table.length*2];
this.table = newTable; //先更新table引用
//然后再将oldTable中的数据一点一点搬移到newTable
for (int i = 0; i < oldTable.length; ++i) {
...
}
}
}
读操作与树化之间不存在线程安全问题。因为链表中的节点定义和红黑树中的节点定义并不相同,所以,在执行树化时,HashMap无法将链表中的节点直接搬移到红黑树中,而是采用复制而非搬移的实现方式,重新创建新的红黑树节点,将链表中的key、value等数据复制到新创建的红黑树节点,然后再将红黑树节点添加到红黑树中。跟扩容还有一个不同的地方是,HashMap在红黑树构建完成之后,才将table数组中的引用更新指向红黑树。因此,树化是一个标准的写时复制操作,读操作和树化之间互不影响。
2)写操作与写操作、扩容、树化之间是否线程安全?
写操作和写操作之间存在线程安全问题。写操作实际上就是执行链表尾插。在第39节讲解CAS操作时,我们拿AQS中的等待队列举例,详细讲解了为什么链表尾插是线程不安全的。尽管HashMap中的链表是单链表,AQS等待队列中的链表为双向链表,但是,两者尾插线程不安全的原因是一样的。这里就不再赘述了。
因为扩容是先更新table引用再搬移数据,所以,扩容和写入实际上都是往新的table数组中添加数据,就相当于并行执行写操作,而刚刚讲到写操作与写操作是存在线程安全问题的,因此,写操作和扩容之间也存在线程安全问题。
写操作和树化之间存在线程安全问题。在树化时进行写入操作,在红黑树构建完成之后,但是table数组中的引用还没来得及更新前,这时执行写操作,就导致写入的数据无法搬移到红黑树中,而导致写操作无效。
3)扩容与扩容、树化操作之间是否线程安全?
扩容与扩容之间存在线程安全问题。根据上述给出的resize()扩容函数的大致代码实现,我们得知,扩容过程先更新table引用指向新创建的table数组(newTable),然后将老的table数组(oldTable)中的数据搬移到新的table数组(newTable)。两个线程同时执行扩容操作,会争抢搬移老的table数组中的链表节点到各自新创建的table数组,而最终table引用只会指向其中一个新创建的table数组,这就导致数据的大量丢失。
扩容和树化之间也存在线程安全问题。如果在一个线程执行树化的过程中,另一个线程执行扩容,因为扩容会搬移数据,这就会导致树化操作只能针对链表中的部分数据进行,进而导致数据大量丢失。
4)树化与树化之间是否线程安全?
树化通过写时复制来实现。两个树化同时进行只会导致生成两个重复的红黑树,重复更新table数组中的引用,并不会引起数据丢失等问题。因此,树化与树化之间不存在线程安全问题。
对读、写、扩容、树化这4个操作两两之间的线程安全性分析,我们总结了如下一张表格。从表中我们可以看出,HashMap在设计实现时完全没考虑线程安全问题。对于HashMap中的绝大部分操作,多线程竞态执行都存在问题。
| 是否存在线程安全问题? | 读操作 | 写操作 | 扩容 | 树化 |
|---|---|---|---|---|
| 读操作 | 否 | 否 | 是 | 否 |
| 写操作 | 否 | 是 | 是 | 是 |
| 扩容 | 是 | 是 | 是 | 是 |
| 树化 | 否 | 是 | 是 | 否 |
二、ConcurrentHashMap介绍
为了解决HashMap的线程安全问题,Java提供了HashTable和SynchronizedMap。JUC提供了ConcurrentHashMap。
实际上,HashTable和SynchronziedMap在本质上是一样的,都是采用简单粗暴的方式(所有的函数都进行加锁)来解决线程安全问题,因此,并发性能欠佳。Java之所以废弃HashTable,引入SynchronizedMap,主要是为了让JCF框架的类结构更加清晰,线程安全容器和非线程安全容器分离,线程安全容器通过统一的方式(Collections的synchronizedXXX()方法)来创建。
对于ConcurrentHashMap,我们又可以分为JDK7版本的ConcurrentHashMap和JDK8版本的ConcurrentHashMap。这两个版本的ConcurrentHashMap的实现方式有比较大的区别,比如,JDK8版本的ConcurrentHashMap的分段加锁粒度更小、并发度更高,扩容方式有所不同,size()函数实现更加高效等等。在本节中,我们仅对JDK8版本的ConcurrentHashMap的实现原理做讲解。对于JDK7版本的ConcurrentHashMap的实现原理,作为思考题留给你自己来分析。
实际上,ConcurrentHashMap提高并发度的核心方法就是分段加锁。在HashTable或SynchronziedMap中,table数组上只有一把锁,所有的读写操作都争抢这一把锁。而在ConcurrentHashMap中,table数组被分段加锁,如果table数组的大小为n,那么就对应存在n把锁,table数组中的每一个链表独享一把锁,不同链表之间的操作可以多线程并行执行,互不影响,以此来提高ConcurrentHashMap的并发性能。
接下来,我们详细讲解一下ConcurrentHashMap中的get()、put()、size()这几个常用函数的具体实现原理。当然,这其中就包含前面提到的读、写、扩容、树化这4个操作。
三、get()函数的实现原理
get()函数对应的就是读操作。在get()函数的代码实现中,我们没有发现任何加锁等线程安全的处理逻辑,因此,get()函数可以跟任何操作(读操作、写操作、树化、扩容)并行执行,并发性能极高。有句老话说的好:哪有什么岁月静好,只不过是有人替你负重前行。之所以get()函数不需要处理线程安全问题,显然是因为其他操作做了特殊处理以兼容并行执行get()函数。
不过,通过以上对HashMap的线程安全性分析,我们可以得知,读操作跟写操作、树化操作之间均不存在线程安全问题,读操作只跟扩容操作之间存在线程安全问题,因此,ConcurrentHashMap中的写操作和树化操作均不需要做特殊处理以兼容并行执行读操作。不过,ConcurrentHashMap中的扩容操作需要做了一些特殊处理以兼容并行执行读操作,待会在讲解扩容的实现原理时,我们再详细说明。
四、put()函数的实现原理
put()函数包含三部分逻辑:写操作、扩容、树化。从上述对HashMap的线程安全性分析,我们得知,除了树化与树化之间,其他任意两个操作之间均存在线程安全问题。因此,为了保证这3个操作并行执行的线程安全性,这3个操作均使用synchronized进行了加锁。接下来,我们依次来看下这3个操作是如何实现的。
1)写操作
写操作有两种加锁方式,分别对应链表为空和不为空这两种情况。通过待插入数据的哈希值定位到链表table[index]之后,如果链表为空(也就是table[index]为null),那么就通过CAS操作将table[index]指向写入数据对应的节点。如果链表不为空(也就是table[index]不为null),那么就对链表的头节点(也就是table[index])使用synchronized加锁,然后再执行写操作。以上处理逻辑对应的代码实现大致如下所示。
public void put(K key, V value) {
//1) 写操作逻辑
int index = hash(key) & (table.length-1);
if (table[index] == null &&
cas(table[index], null, new Node(key, value, null))) {
return; //写入成功
}
synchronzied(table[index]) {
//写入逻辑:遍历链表查看是否存在key跟写入数据相同的节点,
//如果存在,则更新此节点的value值;
//如果不存在,则将写入数据对应的节点插入到链表的尾部。
}
//2) 树化逻辑
//3) 扩容逻辑
}
2)树化
在写入操作执行完成之后,如果链表中的节点个数大于等于树化阈值(默认为8),那么,put()函数会执行树化操作。前面讲到,尽管树化是写时复制操作,但是,在树化的同时执行写入操作或扩容,会导致数据丢失。因此,树化操作也需要使用synchronized加锁。大致的代码逻辑如下所示。
//2) 树化逻辑
if (binCount >= TREEIFY_THRESHOLD) {//binCount为table[index]中节点个数,遍历获得
synchronized(table[index]) {
//树化逻辑:创建红黑树,将链表中的数据复制到红黑树,将table[index]指向红黑树
}
}
3)扩容
写操作和树化的加锁逻辑都比较简单,我们再来看下扩容。相对来说,扩容就复杂多了。前面讲到,ConcurrentHashMap提高并发性能的核心方法是分段加锁,每个链表分别加不同的锁。写操作和树化只针对单个链表操作,因此,只需要对单个链表进行加锁,满足分段加锁的设计思路。但是,扩容处理的是整个table数组中的所有链表,需要对整个table数组加锁,是不是就无法分段加锁了呢?
实际上,ConcurrentHashMap中的扩容操作也是分段加锁分段执行的。接下来,我们详细讲解一下ConcurrentHashMap的扩容实现原理。实际上,为了让扩容兼容读、写、树化操作,允许扩容和读、写、树化操作同时执行而不存在线程安全问题,ConcurrentHashMap在HashMap的基础之上,对扩容逻辑进行了很多改进。
**第一点改进是使用写时复制。**在创建好新的table数组之后,ConcurrentHashMap并非像HashMap那样,直接将table引用指向新创建的table数组,而是采用写时复制的方法,在老的table数组中的数据完全复制到新的table数组中之后,才将table引用指向新创建的table数组。
**第二点改进是复制替代搬移。**前面讲到,在HashMap中,扩容会将老的table数组中的节点直接搬移到新的table数组中,而在ConcurrentHashMap中,扩容是基于复制而非搬移实现的,也就是说,将老的table数组中的节点中的key、value等数据,复制一份存储在一个新创建的节点中,再将新创建的节点插入到新的table数组中。
实际上,以上两点改进借鉴的是树化的处理逻辑。
扩容操作会针对table数组中的每条链表逐一进行复制。在复制某个链表之前,先对这个链表加锁(类似写操作和树化的加锁方式)然后再复制,复制完成之后再解锁。在扩容的过程中,table数组中会存在三种不同类型的链表:已复制未加锁链表、在复制已加锁链表、未复制未加锁链表,如下图所示。
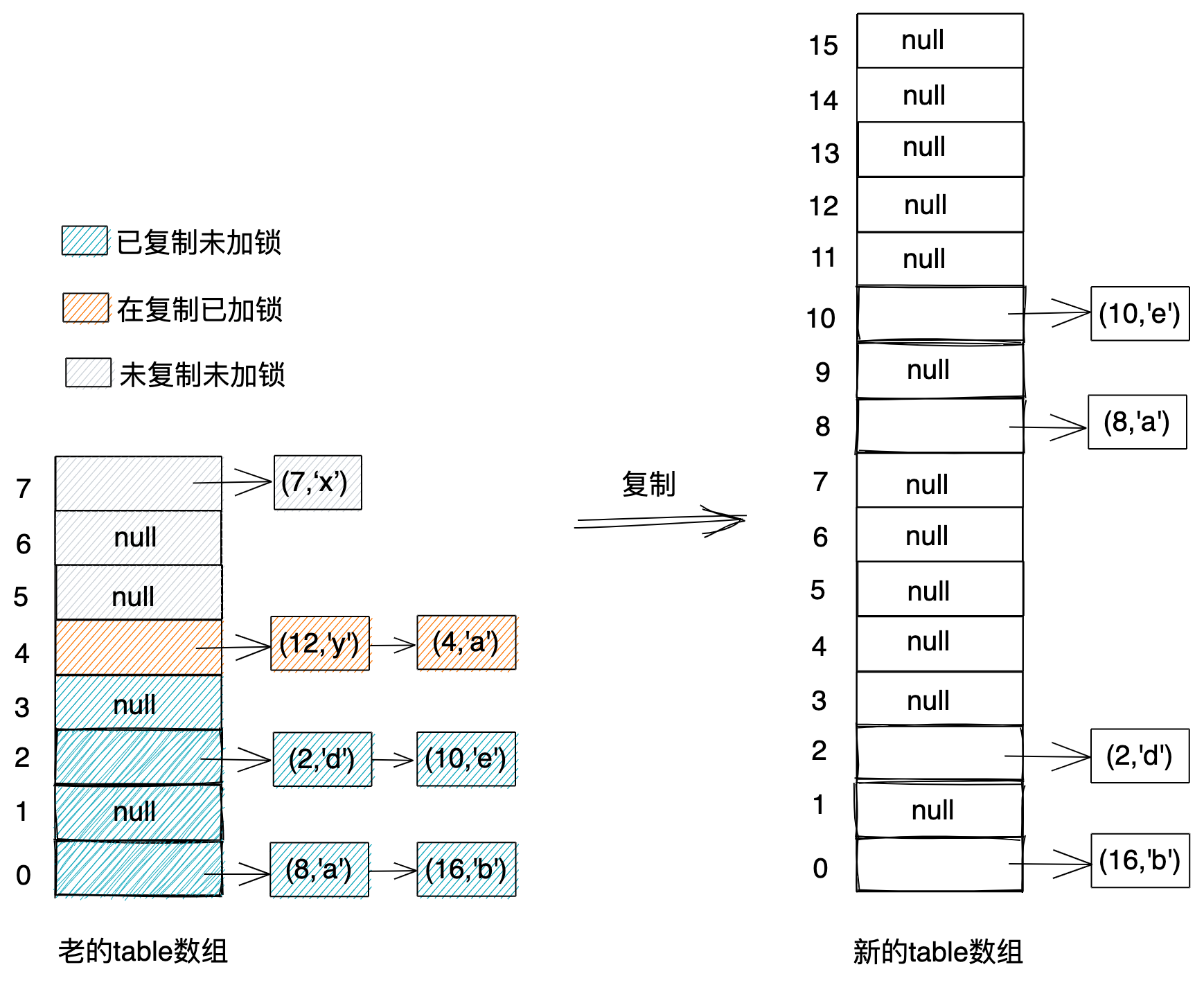
对于未复制未加锁的链表执行读、写、树化操作,以及对于在复制已加锁的链表执行读操作,应该在老的table数组中进行的,而对于已复制未加锁的链表执行读、写、树化操作,应该在新的table数组中进行。因此,在扩容执行的过程中,我们需要对已复制未加锁的链表做标记。当对已标记的链表进行读、写、树化操作时,引导在新创建的table数组中执行。那么,具体是如何标记某个链表是已复制未加锁的呢?
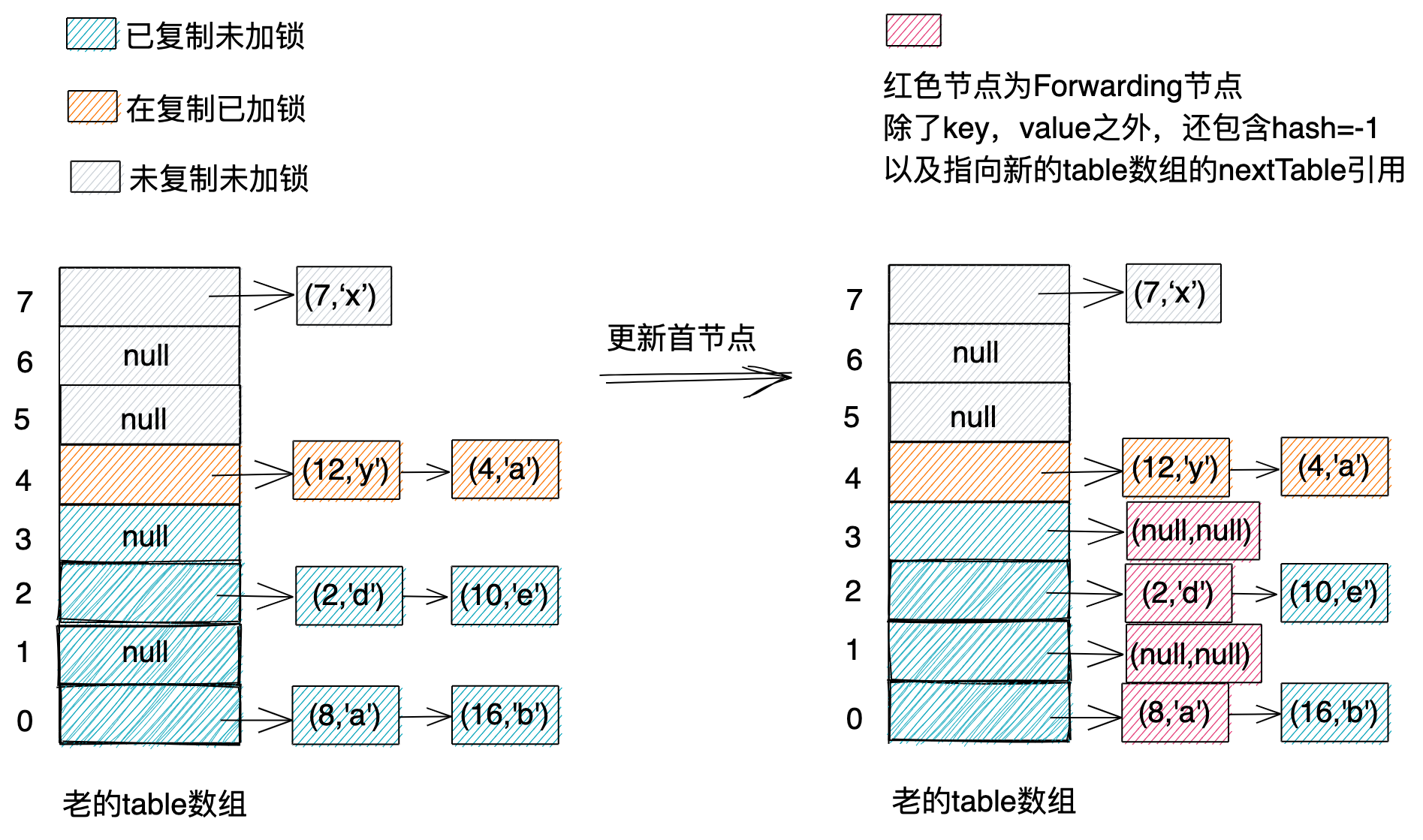
ConcurrentHashMap定义了一个新的节点类型:ForwardingNode,代码如下所示。ForwardingNode继承自Node,将节点中的hash值设置为特殊值-1,以起到标记的作用。
static final int MOVED = -1; // hash for forwarding nodes
//特殊链表节点定义
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K, V>[] nextTable;
ForwardingNode(Node<K, V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
//链表节点定义
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
}
在扩容的过程中,当某个链表复制完成之后,ConcurrentHashMap会将这个链表首节点替换为ForwardingNode节点,并且将ForwardingNode节点中的nextTable属性指向新创建的table数组。对于空链表,ConcurrentHashMap会补充一个key、value均为null的ForwardingNode节点。具体如下图所示。当读、写、树化table数组中的某个链表时,ConcurrentHashMap先检查链表首节点的hash值,如果hash值等于-1,那么就在这个节点的nextTable属性所指向的table数组中重新查找对应的链表,再执行读、写、树化操作。
上述讲解了ConcurrentHashMap如何让扩容可以跟读、写、树化操作并行执行,接下来,我们再来看下,ConcurrentHashMap如何让扩容和扩容并行执行。
在ConcurrentHashMap中,多个线程可以协作共同完成扩容,每个线程负责相邻的几个链表的复制工作,具体负责哪几个,这就由共享变量transferIndex来决定。transferIndex初始化为table.length。多个线程通过CAS修改transferIndex共享变量,如下代码所示,谁成功更新transferIndex,谁就获取了下标在[transferIndex-stride, transferIndex)之间的stride个链表的复制权。如果某个线程竞争执行CAS失败,则自旋重新执行CAS。除此之外,某个线程处理完分配的stride个链表之后,可以再次自旋执行CAS竞争剩余链表的复制权。
public void transfer(Node<K, V>[] tab, Node<K, V> nextTable) {
int n = tab.length;
int stride; //每个线程负责相邻的stride个链表
int NCPU = Runtime.getRuntime().availableProcessors();
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // MIN_TRANSFER_STRIDE=16
//循环获取stride个链表的处理权并处理,直到没有剩余的链表要处理
while(transferIndex>0) {
int oldIndex = tranferIndex;
int newIndex = oldIndex>stride ? oldIndex-stride : 0;
if (!cas(transferIndex, oldIndex, newIndex)) {
continue; //失败继续,自旋CAS
}
//CAS成功,处理下标在[newIndex, oldIndex)之间的table数组中的链表
}
}
前面讲到,ConcurrentHashMap的扩容是写时复制操作,在将老的table数组中的所有链表全部赋值到新的table数组之后,才会将table引用更新为指向新的table数组。那么,多个线程协作扩容,谁来执行最后将table引用更新为指向新的table数组这一操作呢?显然,谁最后完成就谁来做。怎么来标记谁最后完成呢?
ConcurrentHashMap中的定义了一个int类型的共享变量sizeCtl,用来标记当前正在参与扩容的线程个数。sizeCtl初始值为0。当某个线程参与扩容时,就通过CAS将sizeCtl更新为sizeCtl+1,当这个线程手上持有的链表都复制完成,并且table数组中没有剩余的链表可以分配时,这个线程就通过CAS将sizeCtl更新为sizeCtl-1。当某个线程执行完sizeCtl-1操作之后,如果sizeCtl变为0,那么就表示这个线程就是最后一个线程,负责将table引用更新为指向新的table数组。
实际上,sizeCtl也可以声明为AtomicInteger类型,这样就避免了自己实现CAS操作。不过,尽管使用封装好的AtomicInteger更加方便,但性能却没有使用自己实现CAS操作高,这也是ConcurrentHashMap没有使用AtomicInteger的原因。
五、size()函数的实现原理
size()函数返回ConcurrentHashMap容器中的元素个数。实现size()函数的方法有很多种,如下所示。
1)扫描统计
最简单的实现方法是扫描统计。每次调用size()函数时,我们把table数组中的所有链表都遍历一遍,统计得到总的元素个数。但是,如果size()函数不加锁,那么,在扫描统计的同时执行写操作,就会导致扫描统计的结果不准确。如果size()加锁,那么,就会跟写操作、树化、扩容互斥,并发性能降低。除此之外,每次调用size()都扫描整个table数组,执行效率也非常低。
2)实时统计
为了提高size()函数的执行效率,我们可以改用实时统计的方法来实现。在ConcurrentHashMap中维护一个size成员变量,每当执行增、删元素操作时,都同步更新size。但是,不管是将size设置为AtomicInteger,还是通过CAS更新size,又或者加锁更新,在高并发场景下,多个线程同时竞争更新size,就会存在性能问题,进而影响增、删操作的性能。
3)非一致性统计
为了解决实时统计存在的问题,我们可以借鉴LongAdder的实现思路,每个链表维护一个实时统计的cellSize,表示这个链表的节点个数。当调用size()函数时,我们将每个链表的cellSize相加,便得到了ConcurrentHashMap容器中总的元素个数。当然,这也会导致统计结果的不准确或者不一致,关于这点,你可以参看LongAdder的讲解。
六、思考题
1)对于JDK7中的HashMap,两个线程并发执行扩容操作,有可能会导致后续的读操作死循环,请分析具体产生的原因(课程结束之后都会给答案的,放心,自己研究下,这个也不难)。
2)请对比JDK8中ConcurrentHashMap的实现原理,简单分析一下JDK7中ConcurrentHashMap的实现原理。