容器
容器
为什么不推荐在项目中使用Vector、Stack、HashTable?
为了方便开发,Java提供了很多容器,比如ArrayList、LinkedList、HashMap,这些容器底层封装了常用的数据结构,比如数组、链表、哈希表。尽管平时的开发几乎离不开容器,但据我了解,很多程序员只会使用最简单的几个,对容器的全貌没有一个系统性的认识,在使用时,也只是随手抓一个容器就用,不了解其底层实现原理,随便滥用的情况非常常见,极容易影响程序的性能。所以,本节就先粗略地介绍各个容器,让你对Java容器有一个框架性的认识。在后面的章节中,我们再详细讲解重点、难点容器。
一、JCF
Java提供了非常多的容器,但这些容器并非杂乱无章、毫无联系的,而是构成了一个体系,叫作JCF(Java Collections Framework),类似C++中的STL(Standard Template Library)。我们先看一张JCF层次图,里面几乎包含了所有的Java容器,建议你好好看一看。
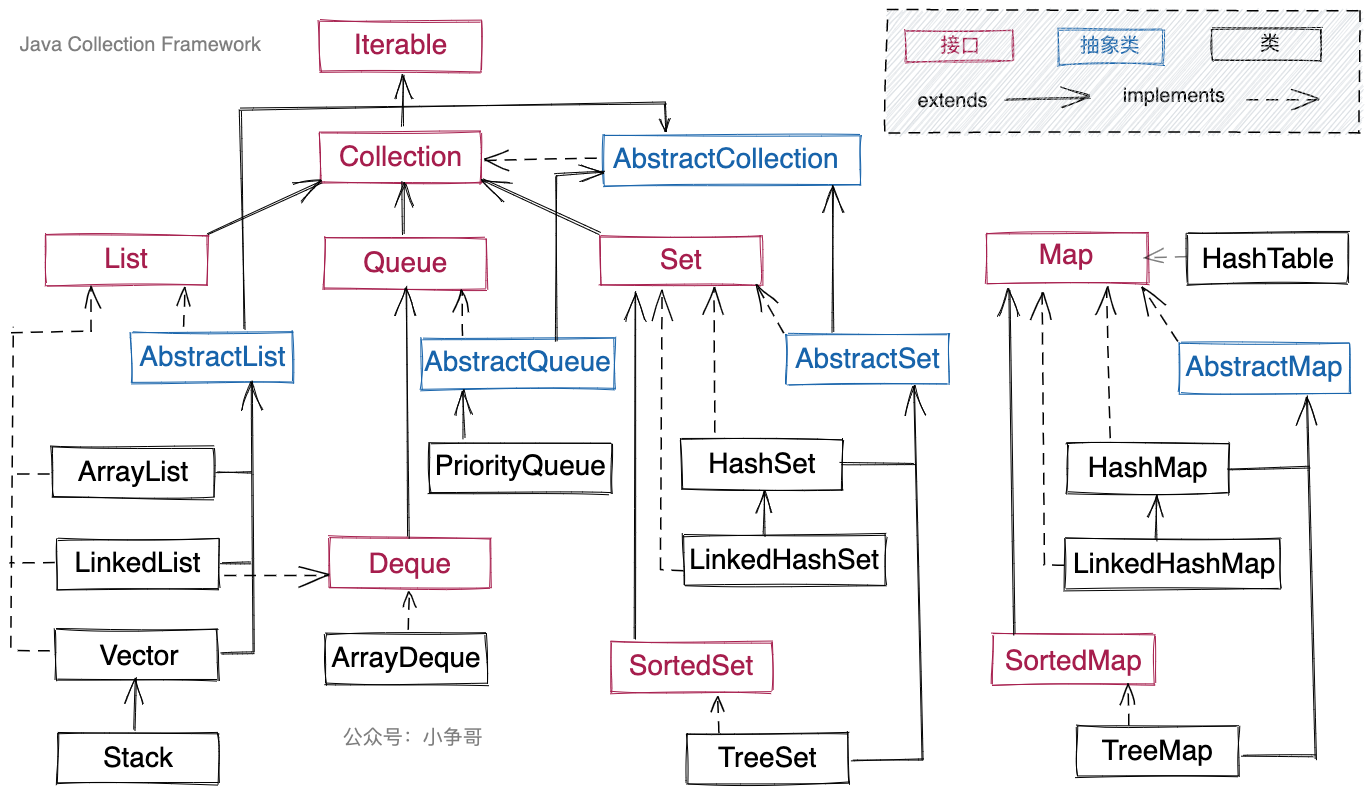
尽管Map容器没有实现上图中Collection接口,但仍然属于JCF的一部分。上图中的Collection接口跟Java Collections Framework中的Collections并非同一个意思。Java Collections Framework中的Collections表示容器的意思,而上图中的Colleciton只是一个接口。
在图中,Map容器跟其他容器毫无关联,这是因为Map容器在用法上跟其他容器不同。Map容器中存储键和值两部分数据,而其他容器只存储单一的值。除此之外,其他容器都支持遍历,而Map容器常用来通过“键”查找“值”,不支持直接的遍历操作。但凡实现Iterable接口的容器,都支持迭代器遍历。所以,Map容器都没有实现Iterable接口,也就没有跟其他容器那样实现Collection接口。
我们将JCF中的容器分为5类,如下所示。
1)List(列表):ArrayList、LinkedList、Vector(废弃)
2)Stack(栈):Stack(废弃)
3)Queue(队列):ArrayDeque、LinkedList、PriorityQueue
4)Set(集合):HashSet、LinkedHashSet、TreeSet
5)Map(映射):HashMap、LinkedHashMap、TreeMap、HashTable(废弃)
之所以这样分类,主要是结合两个方面因素来考虑。一是,从底层数据结构的归类来看,数组、链表、栈、队列、哈希表本应该划分为不同的类。二是,从用法上来看,同类容器往往基于相同的接口来创建,这样在使用过程中,可以互相替换,如下代码所示。尽管Set容器和Map容器都是基于哈希表来实现的,但在用法上无法互相替换,所以不能归为一类。同理,Stack、Queue也几乎不会基于List接口创建,所以也单独做了分类。
List<Integer> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
Stack<Integer> stack = new Stack<>();
// List<Integer> statck = new Stack<>(); //不会有人这么写
Queue<Integer> queue = new LinkedList<>();
Queue<Integer> aQueue = new ArrayDeque<>();
Queue<Integer> pQueue = new PriorityQueue<>();
//List<Integer> aQueue = new ArrayQueue<>(); //不会有人这么写
Set<Integer> hashSet = new HashSet<>();
Set<Integer> treeSet = new TreeSet<>();
Set<Integer> linkedHashSet = new LinkedHashSet<>();
Map<Integer, String> hashMap = new HashMap<>();
Map<Integer, String> treeMap = new TreeMap<>();
Map<Integer, String> linkedHashMap = new LinkedHashMap<>();
接下来,我们依次介绍一下这5类容器。
二、List(列表)
ArrayList、LinkedList、Vector这三个类都实现了List接口,并且继承了AbstractList抽象类。仔细观察JCF层次图,我们可以发现,其他类别的容器也具有相同的层次结构:实现一个接口并继承一个抽象类。接口存在的意义不用多说,方便开发中替换不同的实现类。那么,抽象类的作用是什么呢?
答案是复用。ArrayList、LinkedList、Vector中的一些方法的代码实现是相同,为了避免重复编写,我们就得找个地方存放这些公共的代码,那就只好再设计一个抽象类了。
接下来,我们依次来看一下这三个类。
1)ArrayList
这个类应该是用的最多的容器之一了,其底层依赖的数据结构为可动态扩容的数组。动态扩容可以说是容器的必备功能,ArrayList、Stack、ArrayQueue、PriorityQueue、HashSet、HashMap等都支持动态扩容。关于动态扩容,我们在后面的章节中详细介绍。
2)LinkedList
LinkedList底层依赖的数据结构为链表,并且是链表中的双向链表。在算法面试中,跟链表相关的题目大部分都是针对单链表,因为单链表操作起来非常费劲,容易拿来考察候选人的逻辑思维能力。而正因为单链表的这个特点,在项目开发中,我们很少使用单链表,更倾向选择双向链表。双向链表支持双向遍历,并且很多操作实现起来都更加简单,比如插入、删除操作。也正因如此,Java使用双向链表来实现LinkedList。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable,
java.io.Serializable {
transient int size = 0;
transient Node<E> first; //头指针
transient Node<E> last; //尾指针
private static class Node<E> { //双向链表节点
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//...省略其他代码...
}
因为ArrayList和LinkedList都实现了List接口,抛开性能来说,在用法上完全可以互相替换。在项目开发或面试中,我们也经常会遇到ArrayList和LinkedList的选择问题。简单来讲,如果需要频繁的在内部而非尾部添加删除元素,那么我们首选LinkedList。对于ArrayList,在内部添加元素因为涉及到数据搬移,时间复杂度为O(n)。如果需要频繁的按照下标查询元素,那么我们首选ArrayList。对于LinkedList,按照下标查询元素,需要遍历链表,时间复杂度为O(n)。
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(4);
list.add(2);
for (int i = 0; i < 1000; ++i) {
list.add(0, i); // 执行效率很低,add()方法的时间复杂度为O(n)
}
List<Integer> list2 = new LinkedList<>();
for (int i = 0; i < 1000; ++i) {
list2.add(0, i); //执行效率高,add()方法的时间复杂度O(1)
}
int sum = 0;
for (int i = 0; i < 1000; ++i) {
sum += list2.get(i); //执行效率很低,get()方法的时间复杂度为O(n)
}
3)Vector
Vector是线程安全的ArrayList,早在JDK1.0就存在了,显然,它是模仿了C++ STL中的Vector。这也应征了,Java中的很多特性都来自于C++。JDK1.0中还没有JCF,只有少数的几个容器,比如Vector、Stack、HashTable,而且都是线程安全的。JDK1.2设计了JCF,定义了一套完善的容器框架,从功能上完全可以替代JDK1.0中引入的Vector、Stack、HashTable。但为了兼容,Java并没有将Vector、Stack、HashTable从JDK中移除。尽管没有废弃,但已经不推荐使用了。所以,在现在的项目开发中,我们很少用到这三个类。
为了更符合程序员的开发习惯,JCF将线程安全容器和非线程安全容器分开来设计。在非多线程环境下,我们使用没有加锁的容器,性能更高。 例如,替代Vector,JCF设计了非线程安全的ArrrayList。对于多线程环境,我们可以使用Collections工具类提供的sychronizedList()方法,将非线程安全的List,转换为线程安全的SynchronizedList(详见容器工具类),或者使用JUC(java.util.concurrent)提供的CopyOnWriteArrayList(在Java的多线程提到)。
三、Stack(栈)
Stack也是JDK1.0的产物,继承自Vector,也是线程安全的,在项目中不推荐使用。 取而代之,我们可以使用Deque双端队列来模拟栈。双端队列支持在一端存入数据、取出数据,支持先进后出的访问模式,可以当做栈来使用。
Deque<Integer> deque = new LinkedList<>();
deque.push(1);
deque.push(2);
deque.push(3);
while (!deque.isEmpty()) {
System.out.println(deque.pop()); //输出顺序:3、2、1
}
四、Queue(队列)
JCF中的队列分为双端队列(Deque)和优先级队列(PriorityQueue)。
普通队列只能队尾添加元素,队首获取元素。双端队列的首尾两端,均可添加和获取元素。在《数据结构与算法之美》中,我们讲到,双端队列有两种实现方式:基于数组来实现和基于链表来实现。在JCF中,ArrayDeque就是基于数组实现的队列,LinkedList就是基于链表实现的队列。 对的,你没看错,基于链表实现的队列,直接复用了LinkedList类,LinkedList类在实现时,实现了Deque接口,如下所示。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable,
java.io.Serializable {
//...省略代码实现...
}
优先级队列底层依赖堆这种数据结构来实现,对应JCF容器PriorityQueue。默认情况下,优先级队列基于小顶堆来实现的,最先出队列的为当前队列中的最小值。当然,我们也可以通过使用Comparator接口的匿名类对象,改变优先级队列的实现方式,改为基于大顶堆来实现 ,此时,最先出队列的为当前队列中的最大值。示例代码如下所示。至于小顶堆、大顶堆的实现原理,建议你查看我的《数据结构与算法之美》一书。
// 默认为小顶堆实现的优先级队列
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(2);
pq.add(3);
pq.add(1);
while (!pq.isEmpty()) {
System.out.println(pq.poll()); //输出1、2、3
}
// 改为大顶堆实现的优先级队列
PriorityQueue<Integer> rpq = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
rpq.add(2);
rpq.add(3);
rpq.add(1);
while (!rpq.isEmpty()) {
System.out.println(rpq.poll()); //输出3、2、1
}
堆的构建过程,需要比较节点中数据的大小,所以,添加到优先级队列中的元素,需要能够比较大小。比较大小的方法有两种:基于Comparable接口和基于Comparator接口。两个接口的定义如下所示。
//不管是使用Comparable的o1.compareTo(o2)方法,
//还是使用Comparator的compare(o1, o2)方法,
//o1小于o2时都返回负数,o1等于o2时都返回0,o1大于o2时都返回正数。
public interface Comparable<T> {
public int compareTo(T o);
}
public interface Comparator<T> {
int compare(T o1, T o2);
}
对于基于Comparable接口实现的比较方法,存储在优先级队列中的元素,需要实现Comparable接口,优先级队列调用compareTo()方法比较元素大小。
对于基于Comparator接口实现的比较方法,我们创建一个Comparator接口的匿名类对象,优先级队列会调用compare()方法比较元素的大小。
实际上,在Java中,所有需要比较元素大小的地方,都是使用这两种方法来实现,比如Collections.sort()、TreeMap等。
// 实现Comparable
public class Student implements Comparable<Student> {
public int id;
public int age;
public int score;
public Student(int id, int age, int score) {
this.id = id;
this.age = age;
this.score = score;
}
@Override
public int compareTo(Student o) {
return this.id - o.id;
}
@Override
public String () {
return "[id: " + id + ", age: "
+ age + ", score: " + score + "]";
}
}
//使用Comparator灵活定义优先级
PriorityQueue<Student> q = new PriorityQueue<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.score - o1.score;
}
});
q.add(new Student(2, 10, 89));
q.add(new Student(3, 9, 78));
q.add(new Student(1, 11, 99));
while (!q.isEmpty()) {
System.out.println(q.poll());
}
Java提供的类,比如Integer、String,大都实现了Comparable接口,但如果是我们自己定义的类,需要主动去实现Comparable接口。
如果一个类既没有实现Comparable接口,也没有创建Comparator接口的匿名类对象,那么使用PriorityQueue存储这个类的对象将会报运行时异常。如果两种比较方法同时实现,则优先使用基于Comparator接口的比较方法。 如PriorityQueue中的代码所示。
//PriorityQueue部分源码
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
// 采用第一种方法,元素实现Comparable接口,使用compareTo()对比
@SuppressWarnings("unchecked")
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
// 采用第二种方法,定义Comparator对象,使用compare()方法对比
@SuppressWarnings("unchecked")
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
五、Set(集合)
Set容器跟List容器都可以用来存储一组数据。不同的地方在于,List容器中有下标的概念,不同下标对应的位置可以存储相同的数据,而Set容器没有下标的概念,不允许存储相同的数据。
Set容器包括HashSet、LinkedHashSet、TreeSet。从代码实现上来说,这三个类底层分别是依赖HashMap、LinkedHashMap、TreeMap这三个类实现的。 例如,往HashSet中存储对象obj,底层实现如下代码所示,将obj值作为键,一个空的Object对象做为值,一并存储到HashMap中。所以,Set容器相当于是Map容器的封装,我们重点讲解Map容器。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable {
// 数据存储在这个Map中
private transient NavigableMap<E,Object> m;
// 存储在Map中的默认value值
private static final Object PRESENT = new Object();
public TreeSet() {
this(new TreeMap<E,Object>());
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
public boolean contains(Object o) {
return m.containsKey(o);
}
//...省略其他属性和方法...
}
六、Map(映射)
Map容器包括HashMap、LinkedHashMap和TreeMap。跟Set容器类似,Map容器也不支持存储重复的键。在这个三个容器中,HashMap和LinkedHashMap的底层实现原理比较复杂,其底层实现原理是面试中非常常考的知识点。所以,接下来,我们会用两节课的时间详细地讲解这两个容器。在本节,我们介绍一下比较简单的TreeMap。
TreeMap是基于红黑树来实现的。TreeMap基于键值对的键来构建红黑树,值作为卫星数据,附属存储在红黑树的节点中。具体红黑树的实现原理,我们就不在这里讲述了,如果不了解,你可以参看一下《数据结构与算法之美》。
前面讲到,PriorityQueue底层依赖堆,堆的构建需要比较元素的大小,我们可以基于Comparable接口或Comparator接口,为PriorityQueue提供比较元素大小的方法。而TreeMap底层依赖红黑树,红黑树的构建也需要比较元素的大小,所以,跟PriorityQueue类似,如果在使用TreeMap时,要么键值对中的键实现Comparable接口,要么在创建TreeMap时传入Comparator接口的匿名类对象。
从JCF层次图中,我们可以发现,TreeMap直接实现的接口是SortedMap ,而非Map。这是因为TreeMap底层依赖红黑树来实现,其中序遍历的结果是有序的,因此,相较于基于哈希表实现的HashMap,TreeMap可以提供更加丰富的功能,比如查看最大键值、最小键值、大于某个值的键值、有序输出所有的键值等等,这些操作都定义在SortedMap接口中。 对于这些操作的实现原理,你可以自行阅读代码。
七、课后思考题
容器为什么设计成泛型?有什么好处?为什么不支持存储基本类型数据?