容器工具类
容器工具类
请描述TimSort和DualPivotQuickSort的实现原理
上一节,我们罗列了JCF中的容器,实际上,JCF还提供了一个工具类Collections,是开发中非常常用的一个类。Collections类中包含大量操作容器的静态函数,比如sort()函数、emptyList()函数等。其中涉及的一些知识点,也在面试中经常被考到,比如sort()函数底层的TimSort和DualPivotQuickSort两种排序算法的实现原理和区别是什么。
下面从函数定义、使用方法、底层原理三个方面,详细讲讲Collections工具类中常用的并且比较复杂的函数,它们分别是:sort()函数、binarySearch()函数、emptyXXX()函数、synchronizedXXX()函数、unmodifiableXXX()函数。其中,XXX可以替换为List、Colleciton、Set、Map等。对于其他比较简单的函数,比如copy()函数、addAll()函数等,你可以自行查阅学习。
一、sort()函数
Colletions类中的sort()函数用来对List进行排序,默认排序方式为从小到大排序。也可以通过向sort()函数,传入Comparator接口的匿名类对象,改变排序方式。 sort()函数的定义如下所示。
public static <T extends Comparable<? super T>> void sort(List<T> list);
public static <T> void sort(List<T> list, Comparator<? super T> c);
前面讲到,但凡实现中要涉及到元素比较操作的类或函数,几乎都会用到Comparable和Comparator这两个接口。所以,如果List容器中的元素对应的类,没有实现Comparable接口,并且没有在sort()函数中传入Comparator接口的匿名类对象,那么,我们将无法使用sort()函数对这个List容器进行排序。
sort()函数的定义非常简单,我们再来看一下sort()函数的使用方法,示例如下所示。
List<Integer> list = new LinkedList<>(); //或new ArrayList<>();
list.add(3);
list.add(6);
list.add(2);
Collections.sort(list);
for (Integer i : list) {
System.out.println(i); //输出2、3、6
}
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
for (Integer i : al) {
System.out.println(i); //输出6、3、2
}
我们知道,绝大部分排序算法都是运行在数组之上的,因为排序的过程需要要用到数组按照下标快速访问元素的特性,而在上述代码中,我们使用sort()函数,对链表(LinkedList)进行了排序,这又是如何做到的呢?
实际上,不管是ArrayList容器还是LinkedList容器,使用sort()函数进行排序时,底层都会先将其转换为数组,对数组进行排序之后,再将排好序的数据存入容器中。 对应的源码如下所示。
// 位于Collections类中
public static <T extends Comparable<? super T>> void sort(List<T> list) {
list.sort(null);
}
// 位于List接口中
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
在上述源码中,我们看到,Collections类的sort()函数最终调用Arrays类的sort()函数,完成了对数组中数据的排序。Arrays类的作用跟Collections类类似。Collections类是容器的工具类。Arrays类是数组的工具类。Arrays类中定义了一系列处理数组的静态函数,比如sort()、binarySearch()、equals()等。
实际上,从上述源码,我们还可以发现,我们不仅可以使用Collections类的sort()函数对List容器进行排序,还可以直接调用List容器自身的sort()函数进行排序,示例代码如下所示。不管使用哪种方法排序,底层都是依赖Arrays的sort()函数。
List<Integer> list = new LinkedList<>();
list.add(3);
list.add(6);
list.add(2);
//Comparator接口的匿名类对象为null,
//使用Integer实现的Comparable接口进行元素大小比较
list.sort(null);
for (Integer i :list) {
System.out.println(i);
}
学过数据结构和算法的同学都知道,常用的排序算法有插入排序、选择排序、冒泡排序、快速排序、归并排序、堆排序等,那么,Collections类的sort()函数底层依赖的Arrays类的sort()函数,是用哪种算法实现的呢?
前面的章节中讲到,数组可以分为基本类型数组和对象数组。基本类型数组中存储的是int、long等基本类型元素,对象数组中存储的是Integer、String、Student等对象。
对于基本类型数组排序,在JDK8及其以后版本中,Arrays类使用DualPivotQuickSort来实现,在JDK7及其之前版本中,Arrays类使用快速排序来实现。
对于对象数组,在JDK8及其以后版本中,Arrays使用TimSort来实现,在JDK7及其之前版本中,Arrays类使用归并排序来实现。Arrays类中跟sort()函数相关的源码在JDK8中如下所示。
//(1)基本类型数组排序
//Arrays中还定义了参数为long[]、short[]、char[]、float[]、double[]数组
//的sort()函数,定义和实现跟sort(int[] a)类似,这里就不重复罗列了
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
//(2)对象数组排序
public static void sort(Object[] a) {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a);
else
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);
}
public static <T> void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}
因为Collections类中的sort()函数是对List容器进行排序,而容器只能存储对象,不能存储基本类型数据(跟容器的设计有关,在后面讲到泛型时会讲解)。所以,Collections类中的sort()函数调用的是Arrays类中对对象数组排序的sort()函数,所以,Collections类的sort()函数是使用TimSort排序算法来实现的。只有下面这样,直接使用Arrays类的sort()函数对基本类型数组排序,才会使用DualPivotQuickSort排序算法。
int[] a = {1, 4, 2, 3};
Arrays.sort(a);
for (int i = 0; i < a.length; ++i) {
System.out.println(a[i]);
}
那么,新的问题又来了,为什么要区别对待基本类型数组和对象数组,分别设计不同的排序算法呢?
在《数据结构与算法之美》中,我们讲到,评价一个排序算法的维度有很多,其中一个重要的维度便是稳定性。对于对象数组来说,我们一般会按照对象中的某个属性来排序,在数据结构中,我们把用于构建数据结构的属性叫做键,对象中的其他属性叫做卫星数据,作为附属数据存储在数据结构中。键相同的对象,卫星数据未必相同。稳定性在某些场景中是必须的。所以,针对对象数组的排序,Arrays类使用稳定的TimSort来实现。对于基本类型数组来说,相等的数据谁在前谁在后,毫无差别,所以,针对基本类型数据的排序,Arrays类使用对稳定性没有要求的DualPivotQuickSort来实现。
接下来,我们简单看一下这两种排序算法的实现原理。
1)DualPivotQuickSort
DualPivotQuickSort中文翻译为双轴快速排序算法或者双分区点快速排序算法。名字有点以偏概全,因为在其代码实现中,不仅仅用到了双轴快速排序算法,还用到了插入排序、计数排序、归并排序等多种排序算法。
插入排序、计数排序、归并排序在《数据结构与算法之美》中都有介绍,我们不再赘述。现在,我们来看下双轴快速排序算法。
我们知道,快速排序算法使用一个分区点(pivot)对数组进行分区。双轴快速排序算法使用两个分区点来对数组进行分区。这也是双轴快速排序算法名称的由来。双轴快速排序算法根据两个分区点(LP、RP),将整个待排序区间,分为三个小区间,如图所示,最左边的元素都小于LP,最右边的元素都大于RP,中间的元素大于等于LP小于等于RP。
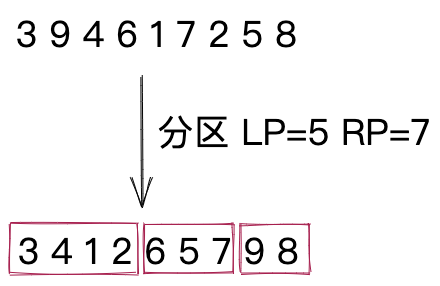
分区点的选择有多种方法,可以使用区间的首元素作为LP,尾元素作为RP,如果首元素大于尾元素,交换两个值。当然,在DualPivotQuickSort中,分区方式更加复杂,采用5数取2法,你可以自己去阅读源码了解。
双轴快速排序算法是对快速排序算法的改进,尽管平均情况下的时间复杂度仍然是O(nlogn),最差情况下的时间复杂度仍然是O(n^2),但在执行过程中,双轴快速排序算法扫描一遍未排序区间,会将区间划分为3个小区间,而快速排序算法只能划分为2个小区间,所以,双轴快速排序算法递归的深度更浅,累计总扫描元素个数,要比快速排序少,所以,执行效率更高。
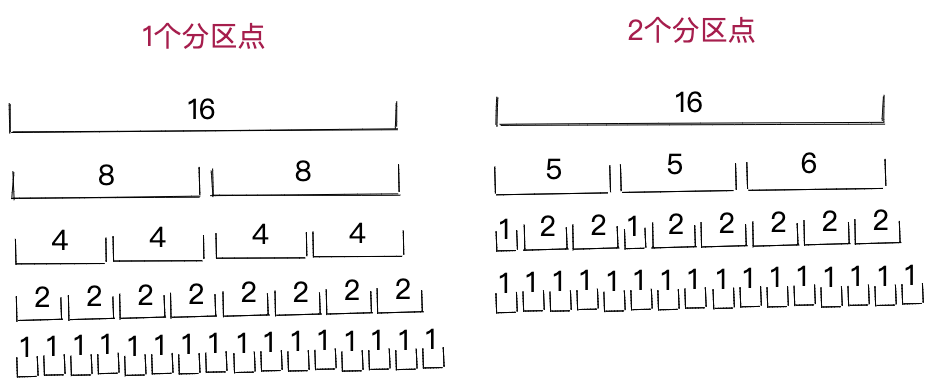
但是不是分区点越多性能越好呢?如果采用更多分区点,将一个区间划分为更多小区间,递归深度会更浅,累计总扫描元素个数会更少,这样是不是效率就更高了呢?
实际上,分区操作本身也是有成本的,如果分区点太多,每个元素都要跟多个分区点比较才能将其放入合适的分区中,这个操作将会消耗比较多的时间,也会影响到整体性能。
DualPivotQuickSort算法的实现,位于java.util.DualPivotQuickSort类中。因为基本类型无法使用泛型,所以,针对不同基本类型的数组,DualPivotQuickSort类定义了不同的sort()函数,如下所示。每个函数都要重复实现了一遍,所以,DualPivotQuickSort类中的代码行数非常多,有2000多行,但核心逻辑并不复杂。
//DualPivotQuickSort类中sort()函数定义
static void sort(int[] a, int left, int right,
int[] work, int workBase, int workLen);
static void sort(long[] a, int left, int right,
long[] work, int workBase, int workLen);
static void sort(float[] a, int left, int right,
float[] work, int workBase, int workLen);
static void sort(double[] a, int left, int right,
double[] work, int workBase, int workLen);
static void sort(short[] a, int left, int right,
short[] work, int workBase, int workLen);
static void sort(char[] a, int left, int right,
char[] work, int workBase, int workLen);
static void sort(byte[] a, int left, int right);
其中,针对int、long、float、double这4种类型的数组,其排序过程几乎相同,对char、short、byte这3类型的数组,其排序过程稍有不同,是在前者基础上的改进。我们先来看下如何排序int、long、float、double这4种类型的数组。
如果待排序数组长度小于预先定义的阈值QUICKSORT_THRESHOLD(值为286),DualPivotQuickSort执行改进后的双轴快速排序算法。在改进后的双轴快速排序算法中,在递归处理过程中,当待排序区间长度小于INSERTION_SORT_THRESHOLD(值为47)时,改为使用插入排序算法。因为对于小规模数据的排序,时间复杂度不再起决定作用,尽管插入排序算法的时间复杂度比较高,但因为处理过程简单,反倒会比快速排序算法执行得快。
如果待排序数组长度大于等于预先定义的阈值QUICKSORT_THRESHOLD(值为286),DualPivotQuickSort会先考察待排序数组的数据的有序性,是杂乱无章还是基本有序?考察方法比较特别:从头到尾扫描数组,统计数组中连续增或连续减的区间个数,如果区间个数超过预先定义的阈值MAX_RUN_COUNT(值为67),则说明待排序数组中的数据偏杂乱无章一些,于是就选择执行改进后的双轴快速排序,否则,就选择执行非递归版的归并排序。之所以这样选择,是因为对于快速排序来说,待排序数组中数据的有序性越高,排序耗时越多,有点反直觉,如有疑惑,可以参看《数据结构与算法之美》书中对快速排序算法的讲解。
当待排序数组中数据的有序性较高时,DualPivotQuickSort选择执行非递归版的归并排序。相对于递归版的归并排序,非递归版的归并排序只有合并过程,没有递归分解过程,省掉了函数调用栈对空间的开销和函数调用对时间的开销。 具体的实现原理大体如下示例所示。
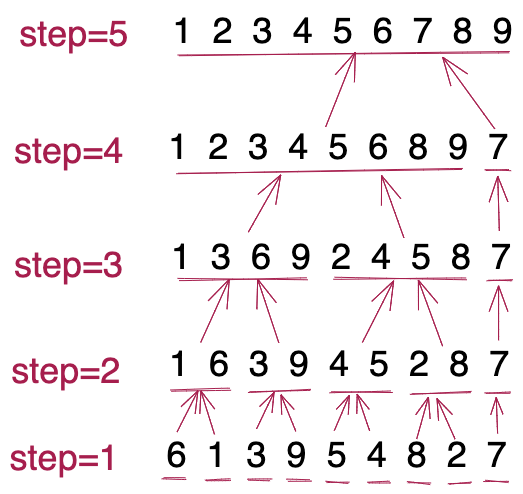
DualPivotQuickSort类中的代码实现比较复杂,为了让你对上述处理过程有比较清晰的了解,我们抛开Java源码实现,我们将上述处理过程,重新实现了一遍,如下代码所示。实际上,以下实现思路也可以应用到链表上的非递归归并排序。
public void mergeSort(int[] arr) {
int n = arr.length;
int step = 1;
// 存放两个相邻区间的起始下标
int[][] intervals = new int[2][2];
while (step < n) {
int seq = 0; // 值为0或1,标记相邻区间中的前一个和后一个
int i = 0; // 区间起始下标
while (i<n) {
int s = i;
int e = i+step; // 分离出区间[s,e)
if (e > n) {
e = n;
}
// 将区间[s, e)放入到intervals
intervals[seq][0] = s;
intervals[seq][1] = e;
if (seq == 1) { //两个相邻区间凑够了
seq = 0;
merge(arr, intervals[0][0], intervals[0][1],
intervals[1][0], intervals[1][1]);
} else { //相邻区间中的前一个找到了,该找下一个了
seq++;
}
i += step;
}
step *= 2; //待merge区间长度变大
}
}
// 合并两个有序区间[start1, end1)和[start2, end2)
private void merge(int[] arr, int start1, int end1,
int start2, int end2) {
int[] tmp = new int[end2 - start1];
int i = start1;
int j = start2;
int k = 0;
while (i < end1 && j < end2) {
if (arr[i] <= arr[j]) {
tmp[k++] = arr[i++];
} else {
tmp[k++] = arr[j++];
}
}
while (i < end1) {
tmp[k++] = arr[i++];
}
while (j < end2) {
tmp[k++] = arr[j++];
}
for (int ti = 0; ti < tmp.length; ++ti) {
arr[start1+ti] = tmp[ti];
}
}
刚刚讲的是对int、long、float、double这4种类型的数组的排序过程。
但是如果对于char类型和short类型的数组,如果数组元素个数大于COUNTING_SORT_THRESHOLD_FOR_SHORT_OR_CHAR(值为3200),将执行计数排序,否则执行跟上述对int等4种类型的数组相同的排序过程。
对于byte类型的数组,如果数组元素个数大于COUNTING_SORT_THRESHOLD_FOR_BYTE(值为29),将执行计数排序,否则执行插入排序。
2)TimSort
TimSort用来排序对象数组,其使用非递归版本归并排序算法,在归并排序的过程中,大的待排序区间不断被分解为小的待排序区间,如果待排序区间的长度小于MIN_MERGE(值为32),就不再继续分解,转而执行二分插入排序算法。
我们来看下二分插入排序算法是如何工作的。
插入排序算法将数组分为两部分:已排序区间和未排序区间。初始化已排序区间为空,未排序区间为整个数组。每次从未排序区间中取出一个数,插入到已排序区间中,并保持已排序区间继续有序。二分插入排序算法和普通的插入排序算法的区别在于,普通的插入排序算法是通过遍历已排序区间,查找未排序区间中的数据在已排序区间中的插入位置,而二分插入排序是通过二分查找算法,查找未排序区间中的数据在已排序区间中的插入位置。当查找到插入位置之后,通过调用System.arraycopy()函数,将插入点之后的数据整体快速后移一位,腾出位置给要插入的数据。
二、binarySearch()函数
binarySearch()函数用来对已排序的List容器进行二分查找。binarySearch()函数的定义如下所示。二分查找也会涉及到元素的比较大小,所以,跟sort()函数类似,要么List容器中的元素对应的类实现Comparable接口,要么在使用binarySearch()函数时,我们主动传入Comparator接口的匿名类对象。
public static <T> int binarySearch(
List<? extends Comparable<? super T>> list, T key);
public static <T> int binarySearch(
List<? extends T> list, T key, Comparator<? super T> c);
binarySearch()函数的使用方式,如下代码所示。
List<Integer> list = new LinkedList<>(); //也可new ArrayList();
list.add(3);
list.add(6);
list.add(2);
Collections.sort(list);
int idx = Collections.binarySearch(list, 3);
System.out.println(idx); //返回下标1
我们知道,二分查找算法运行在数组之上,因为查找过程需要用到数组支持按照下标快速访问的特性。但是,在上述示例代码中,binarySearch()函数实现的二分查找,也可以运行在链表(LinkedList)之上,这是怎么做到的呢?我们来剖析一下binarySearch()函数的源码。
public static <T> int binarySearch(
List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess ||
list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
从上述源码中,我们可以发现,如果要查找的List容器实现了RandomAccess接口,比如ArrayList,那就表明容器支持随机访问,即支持按照下标快速访问元素。这种情况下,binarySearch()函数就使用普通的二分查找算法来实现。 代码如下所示。
private static <T> int indexedBinarySearch(
List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = list.get(mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
如果要应用二分查找的List容器没有实现RandomAccess接口,比如LinkedList,这时又分两种情况来看。
如果容器中的元素个数少于BINARYSEARCH_THRESHOLD(值为5000),这时就使用跟ArrayList相同的二分查找实现代码,如上indexedBinarySearch()代码所示。不过,在LinkedList容器上调用get(mid)函数查找中间节点,需要遍历整个链表,时间复杂度为O(n)。每次while循环都会将区间大小变为原来的1/2,最差情况下,直到区间大小为0时,while循环才停止。此时总共进行了logn次while循环,也就是执行了logn次get(mid)函数。综上所述,indexedBinarySearch()函数运行在LinkedList容器上的时间复杂度是O(nlogn)。关于二分查找的复杂度分析,你可以参考《数据结构与算法之美》。
当LinkedList容器中元素个数小于5000个时,尽管indexedBinarySearch()的时间复杂度有点高,但因为数据量比较小,而且代码实现也比较简单,所以,执行效率可以接受。但当容器中的元素个数比较多,大于等于5000个时,我们就需要对indexedBinarySearch()代码进行优化了,转而使用新的二分查找代码实现,如下所示。
private static <T> int iteratorBinarySearch(
List<? extends Comparable<? super T>> list, T key) {
int low = 0;
int high = list.size()-1;
ListIterator<? extends Comparable<? super T>> i = list.listIterator();
while (low <= high) {
int mid = (low + high) >>> 1;
Comparable<? super T> midVal = get(i, mid);
int cmp = midVal.compareTo(key);
if (cmp < 0)
low = mid + 1;
else if (cmp > 0)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found
}
在上述iteratorBinarySearch()函数中,get(i, mid)函数是通过迭代器来查找中间节点。 get(i, mid)函数的代码实现如下所示。get(i, mid)函数每次都从上一个mid的位置向前或向后查找,查找的范围不再是整个链表,而是当前二分查找的区间[low, high]。所以,get(i, mid)函数的查找范围变小了,执行效率相较于indexedBinarySearch()的get(mid)函数变高了。第一次while循环,get(i, mid)函数遍历的区间长度为n/2,第二次while循环,get(i, mid)函数遍历的区间长度为n/4,依次类推,最差情况下,遍历元素的总个数为n/2 + n/4 + ... + 1 ,其值约等于n。综上所述,在LinkedList容器上执行iteratorBinarySearch()函数的时间复杂度为O(n)。
private static <T> T get(ListIterator<? extends T> i, int index) {
T obj = null;
int pos = i.nextIndex();
if (pos <= index) {
do {
obj = i.next();
} while (pos++ < index);
} else {
do {
obj = i.previous();
} while (--pos > index);
}
return obj;
}
三、emptyXXX()函数
emptyXXX()函数用来返回一个空的容器,其中的XXX可以替换为List、Set、Map,函数定义如下所示。
public static final <T> List<T> emptyList();
public static final <T> Set<T> emptySet();
public static final <K,V> Map<K,V> emptyMap();
emptyXXX()函数一般用来替代返回null值,因为返回null值有可能导致外部代码在调用函数时发生NullPointerException异常。 如下示例代码所示。
public class Demo11_1 {
public static List<String> queryNames(List<Integer> ids) {
if (ids == null || ids.isEmpty()) {
return Collections.emptyList();
}
//...
}
public static void main(String[] args) {
List<Integer> ids = new ArrayList<>();
List<String> names = queryNames(ids);
//如果queryNames返回null而不是emptyList(),
//此处将抛出NullPointerException
for (String name : names) {
//...
}
}
}
不过,使用emptyXXX()函数也要相当注意,有时候会产生意想不到的运行结果,如下代码,你觉得运行结果是什么?
List<Integer> ids = new ArrayList<>();
List<String> names = queryNames(ids);
List<String> names2 = queryNames(null);
System.out.println(names == names2);
names.add("wangzheng");
System.out.println(names.size());
上述代码的运行结果是,第一个print语句打印结果为true,第二个print语句未执行,在执行names.add("wangzheng")语句时,代码抛出UnsupportedOperationException运行时异常。
很多人对emptyList()函数有所误解,以为执行return Collections.emptyList()就相当于执行了return new ArrayList()或return new LinkedList()。实际上并不是。Collections.emptyList()函数返回的是一个新类(EmptyList)的对象,并且这个对象是Collections的静态成员变量。 如下代码所示。
// Collections类中的部分代码
public static final List EMPTY_LIST = new EmptyList<>();
public static final <T> List<T> emptyList() {
return (List<T>) EMPTY_LIST;
}
private static class EmptyList<E>
extends AbstractList<E>
implements RandomAccess, Serializable {
public Iterator<E> iterator() {
return emptyIterator();
}
public ListIterator<E> listIterator() {
return emptyListIterator();
}
public int size() {return 0;}
public boolean isEmpty() {return true;}
public boolean contains(Object obj) {return false;}
public boolean containsAll(Collection<?> c) {
return c.isEmpty();
}
public Object[] toArray() { return new Object[0]; }
public <T> T[] toArray(T[] a) {
if (a.length > 0)
a[0] = null;
return a;
}
public E get(int index) {
throw new IndexOutOfBoundsException("Index: "+index);
}
public boolean equals(Object o) {
return (o instanceof List) && ((List<?>)o).isEmpty();
}
public int hashCode() { return 1; }
//...省略部分代码...
}
因此,两次调用Collections.emptyList()函数获取的值相同,也就是说,names和names2指向相同的EmptyList对象,第一条println语句打印结果为true。
因为EmptyList类并未重新实现add()函数,add()函数继承自AbstractList类,而AbstractList类中的add()函数的代码实现如下所示,所以,当执行names.add(“wangzheng”)语句时会抛出异常。
public void add(E element) {
throw new UnsupportedOperationException();
}
为了避免以上问题,我们一般会在外部代码中重新定义一个容器,将调用函数返回的结果通过addAll()添加到容器中。示例代码如下所示。
List<Integer> ids = new ArrayList<>();
List<String> names = new ArrayList<>();
names.addAll(queryNames(ids));
names.add("wangzheng");
System.out.println(names.size()); //打印结果1
四、synchronizedXXX()函数
上一节讲到,JCF中的容器都是非线程安全的,那么如果我们要使用线程安全的容器,该怎么办呢?当然,我们首选使用不管是性能还是功能都更优的JUC(java.util.concurrent)并发容器,如ConcurrentHashMap、CopyOnWriteArrayList等。当没有合适的JUC并发容器可以使用时,我们可以使用Collections类中的synchronizedXXX()函数来创建线程安全的容器。synchronizedXXX()函数的定义如下所示。
public static <T> Collection<T> synchronizedCollection(Collection<T> c);
public static <T> List<T> synchronizedList(List<T> list);
public static <T> Set<T> synchronizedSet(Set<T> s);
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
我们可以按照如下代码所示,创建线程安全的容器。
List list = Collections.synchronizedList(new LinkedList<>());
synchronizedXXX()函数的底层实现原理非常简单,仅仅通过对每个方法进行加锁,来避免了并发访问。如下源码所示。这也是导致其性能不高的原因。
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
public boolean equals(Object o) {
if (this == o)
return true;
synchronized (mutex) {return list.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
//...省略其他方法...
}
五、unmodifiableXXX()函数
unmodifiableXXX()函数用来返回不可变容器,这里的不可变指的是容器内的数据只能访问,不可增删。unmodifiableXXX()函数的定义如下所示。
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c);
public static <T> List<T> unmodifiableList(List<? extends T> list);
public static <T> Set<T> unmodifiableSet(Set<? extends T> s);
public static <K, V> Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m);
使用场景示例如下所示。查询商品列表的listItems()函数返回的容器不能被更改,外部程序只能通过类暴露的接口来添加删除商品。
public class ShoppingCart {
public static class Item {
private int id;
private int price;
public Item(int id, int price) {
this.id = id;
this.price = price;
}
}
private List<Item> items = new ArrayList<>();
public void addItem(Item item) {
items.add(item);
}
public void removeItem(Item item) {
items.remove(item);
}
public List<Item> listItems() {
return Collections.unmodifiableList(items);
}
}
public class Demo11_1 {
public static void main(String[] args) {
ShoppingCart cart = new ShoppingCart();
cart.addItem(new Item(1, 10));
cart.addItem(new Item(2, 13));
List<Item> items = cart.listItems();
//抛出UnsupportedOperationException异常
items.add(new Item(3, 12));
}
}
实际上,unmodifiableXXX()函数的实现也比较简单,其实现原理跟synchronizedXXX()函数的实现原理类似。如下代码所示,定义新的UnmodifiableXXX类,重写add()、remove()等增删操作,让其抛出UnsupportedOperationException异常。
public static <T> List<T> unmodifiableList(List<? extends T> list) {
return (list instanceof RandomAccess ?
new UnmodifiableRandomAccessList<>(list) :
new UnmodifiableList<>(list));
}
static class UnmodifiableList<E>
extends UnmodifiableCollection<E> implements List<E> {
final List<? extends E> list;
UnmodifiableList(List<? extends E> list) {
super(list);
this.list = list;
}
public boolean equals(Object o) {
return o == this || list.equals(o);
}
public int hashCode() { return list.hashCode(); }
public E get(int index) { return list.get(index); }
public E set(int index, E element) {
throw new UnsupportedOperationException();
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public E remove(int index) {
throw new UnsupportedOperationException();
}
//...省略其他方法和属性...
}
六、课后思考题
Collections为什么设计成工具类?是否可以将其中的方法转移到相关的List类中?