HashMap
HashMap
为何HashMap中数组的大小必须是2的幂次方?
上两节,我们粗略讲了JCF中的各个容器,给你构建了一个系统性的框架图。本节,我们重点讲一下HashMap。HashMap在Java编程中,使用频率非常高,而且,因为其底层实现比较复杂,在面试中,也经常被面试官拿来考察候选人对技术掌握的深度。本节,我们就从基本原理、哈希函数、装载因子、动态扩容、链表树化等方面,详细剖析HashMap的实现原理。
一、基本原理
HashMap容器实现了接口Map,从功能上讲,它是一个映射,通过键(key)快速获取值(value),键和值具有一一映射关系。HashMap容器使用起来非常简单,如下示例代码所示。注意,HashMap容器中存储的键不可重复,但值可以重复。存储重复的键,后面存储的值会覆盖前面存储的值,相当于执行了修改操作。
public class Demo13_1 {
private static class Student {
public int id;
public int score;
public Student(int id, int score) {
this.id = id;
this.score = score;
}
@Override
public String toString() {
return "Student [id=" + id + "; score=" + score + "]";
}
}
public static void main(String[] args) {
Map<Integer, Student> stuMap = new HashMap<>();
// 增
stuMap.put(1, new Student(1, 90));
stuMap.put(3, new Student(3, 88));
stuMap.put(19, new Student(19, 97));
// 删
stuMap.remove(1);
// 改
stuMap.put(3, new Student(3, 100));
// 查
Student stu = stuMap.get(3);
System.out.println(stu); //Student [id=3; score=100]
}
}
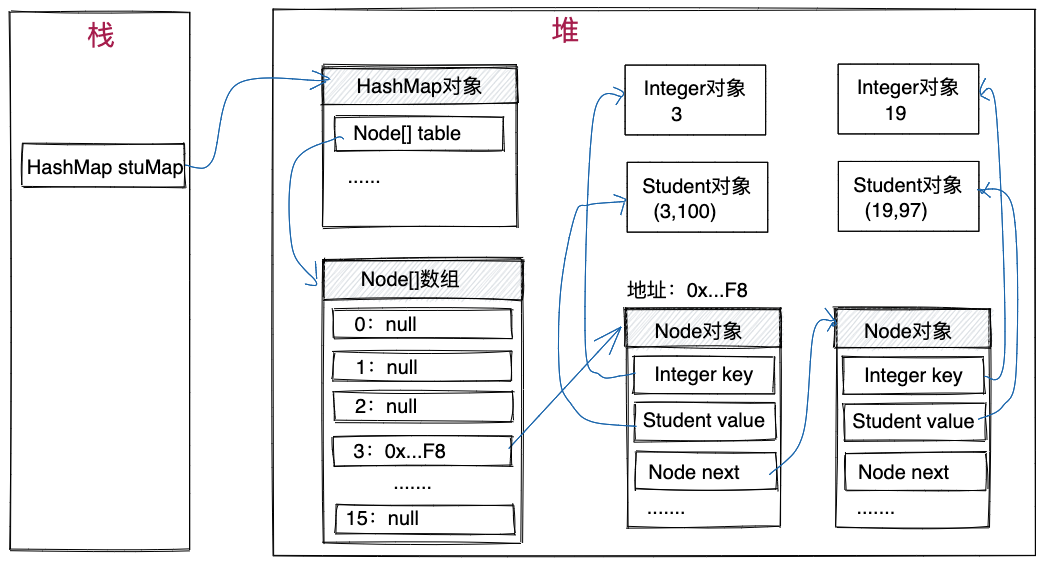
HashMap容器是基于哈希表实现的,对键计算哈希值,并将键和值包裹为一个对象,如下代码中Node类所示,存储在哈希表中。接下来的分析,如果不特别说明,我们都是按照JDK8中HashMap容器的代码实现来讲解。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
//...省略getter、setter等方法...
}
transient Node<K,V>[] table;
//...省略其他属性和方法...
}
在《数据结构与算法之美》中,我们讲到,哈希表存在哈希冲突,哈希冲突解决的方法有多种,其中比较常用的就是链表法(也叫做拉链法),这也正是HashMap容器所使用的方法。如上代码所示,table数组便是用来存储链表的。Node类便是链表中节点的定义,key表示键,value表示值,next为链表的next指针(尽管next在Java中为引用,但在数据结构和算法中,我们一般将next称为next指针),hash为由key通过哈希函数计算得到的哈希值,起到缓存的作用,在查询元素时,用此值做预判等。关于这个值的详细介绍,后面会讲到。
根据以上对HashMap基本实现原理的讲解,我们将开头示例代码的存储结构,绘制出来,如下图所示。键3和键19存在哈希冲突,对应的节点存储在同一个链表中。
二、哈希函数
哈希函数是哈希表中非常关键的一个部分。我们来看一下HashMap中哈希函数是如何设计的,如下代码所示。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
我们发现,哈希函数设计的非常简单,借助键的hashCode()函数,将其返回值h,与移位之后的h进行异或操作,最终得到的值作为哈希值。
提示
因为key经过此哈希函数计算之后,得到的哈希值范围非常大,往往会超过table[]的长度n,因此,需要跟n取模,才能最终得到存储在table[]中的下标(我们把这个下标值简称为“key对应数组下标”)。因为取模操作比较耗时,所以,在具体实现时,Java使用位运算实现取模运算,如下代码所示。key将存储在table[index]对应的链表中。
int index = hash(key) & (n-1);
上述计算过程如下图所示。其中,HashMap容器的数组长度n的默认初始值为16。

上面粗略展示了key的哈希值和对应数组下标的计算方式,接下来,我们再对计算方式的细节做些解释。
1)key的hashCode()函数
hashCode()函数定义在Object类中,根据对象在内存中的地址来计算哈希值,当然,我们也可以在Object的子类中重写hashcode()函数,Integer、String类的hashCode()函数如下所示。从代码中,我们可以发现,Integer对象的哈希值就是其所表示的数值(value)本身。
// Integer类的hashCode()函数
public int hashCode() {
return value;
}
// String类的hashCode()函数
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
2)h ^ (h >>> 16)
在hash()函数中,为什么不直接返回h,也就是key的hashCode()返回值作为哈希值?
充分利用信息
这是因为,一般来说,table数组的大小n不会很大,一般会小于(65536)。而hashCode()函数的返回值h为int类型,长度为4个字节。在计算key对应的数组下标时,h跟n求模后,h的高16位信息将会丢失,相当于只使用了h的后16位信息。理论上讲,参与计算的信息越多,得到的数组下标越随机,数组在哈希表中的各个链表中的分布就会越均匀。所以,我们将hasCode()函数的返回值与其高16位异或,这样所有的信息都没有浪费。
3)取模h & (n-1)
之所以可以用上述位运算来实现取模运算,有一个极其关键的前提是:
位运算实现取模操作
HashMap中table数组的大小n为2的幂次方(如何做到的?我们待会再讲)。比如,将其减一之后的二进制串为:1111,跟h求与,相当于取模操作。
也就是说如果模16,那么就和做与运算,即取二进制的后四位。
4)key可为null值
从hash()函数中,我们还可以发现,值为null的key的哈希值为0,对应数组下标为0,所以,值为null的key也可以存储在HashMap中。不过,一个HashMap容器只能存储一个值为null的key,这符合HashMap容器不允许存储重复key的要求。
了解了哈希函数之后,我们再回过头去看下,Node类中的hash属性。hash属性存储的是key的哈希值(也就是通过hash(key)计算得到的值)。这个值的作用是预判等,提高查询速度。将这个值作为属性存储在节点中目的是,避免重复计算。接下来,我们具体来讲讲它是怎么工作的。
当我们调用get(xkey)函数查询键xkey对应的值(value)时,HashMap容器先通过hash(xkey)函数计算得到xkey的哈希值,假设为xhash。xhash跟table数组大小n取模,假设得到数组下标为xIndex,也就说明x应该出现在table[xIndex]对应的链表中。
遍历table[xIndex]所对应的链表,查找属性key等于xkey的节点。当遍历到某个节点node之后,首先会拿node.hash,与x的哈希值xhash比较,如果不相等,则说明node.key跟xkey肯定不相等,就可以继续比较下一节点了。
如果node.hash跟xhash相等,也并不能说明这个节点就是我们要找的节点。 因为哈希函数存在一定的冲突概率,所以,即便哈希值相等,node.key也未必就跟xkey相等。因此,我们需要再调用equals()方法,比较node.key与xkey是否真的相等,如果相等,那么这个节点就是我们要查找的节点。如果不相等,则继续遍历下一个节点,再进行上述比较。
node.key和xkey为对象,需要调用equals()函数比较是否相等。node.hash和xhash为整数,直接使用等号即可判等。后者比前者的执行效率更高。通过预先比对哈希值,过滤掉node.key和xkey不可能相等的节点,以此来提高查询速度。
上述查找过程对应的HashMap类的源码如下所示。
//HashMap类的源码
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && ((k = first.key) == key
|| (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//...省略部分代码...
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
三、装载因子
为了方便使用,JCF提供的容器基本上都支持动态扩容,当容器中容纳不下新的元素时,便会扩容,将数据搬移到更大的存储空间中。HashMap容器也不例外。你可能会说,HashMap使用链表法解决哈希冲突,链表可以无限长,不存在无法容纳新元素的情况。但是,当HashMap容器中的数据越来越多时,在table数组大小不变的情况下,链表的平均长度会越来越长,进而影响到HashMap容器中各个操作的执行效率,这种情况下就应该扩容了。
扩容的时机
具体什么时候扩容,主要由table数组的大小(n)和装载因子(loadFactor)决定。当HashMap容器中的元素个数超过n * loadFactor时,就会触发扩容。其中,n * loadFactor在HashMap类中定义为属性threshold。
在HashMap中,装载因子laodFactor的默认值为0.75,table数组的默认初始大小为16。也就说,当添加元素个数超过12(16*0.75)个时,HashMap容器就会触发第一次扩容。当然,我们也可以通过带参构造函数,自定义table数组的初始大小和装载因子,如下代码所示。
//HashMap类的其中一个构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException(
"Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException(
"Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
前面讲到,为了便于使用位运算来实现取模运算,table数组的大小必须是2的幂次方,但是,如果通过构造函数,传入的参数initialCapacity不是2的幂次方,那该怎么办呢?上述代码中使用tableSizeFor()函数,就是为了解决这个问题,它会寻找比initialCapacity大的第一个2的幂次方数。比如tableSizeFor(7)=8,tableSizeFor(13)=16。tableSizeFor()函数的代码实现如下所示。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY)
? MAXIMUM_CAPACITY : n + 1;
}
为什么上述逻辑可以获取到一个数最邻近的2的幂次方数?对此我们不做证明,仅仅通过一个例子,来看下它是如何工作的。如下图所示。

这里稍微解释一下,以免细心的你会有疑问,tableSizeFor(initialCapacity)的值赋值给了threshold,这似乎有些不对。因为tableSizeFor(initialCapacity)的值是table数组的大小,threshold是触发扩容的阈值,按理来说,tableSizeFor(initialCapacity)的值乘以loadFactor才应该是threshold。
实际上,这是因为在创建HashMap对象时,table数组只声明未创建,其值为null。只有当第一次调用put()函数时,table数组才会被创建。但是,HashMap并没有定义表示table数组大小的属性,于是,tableSizeFor(initialCapacity)的值就暂存在了threshold属性中,当真正要创建table数组时,HashMap会类似如下代码所示,先用threshold作为数组大小创建table数组,再将其重新赋值为真正的扩容阈值。
this.table = new T[this.threshold];
this.threshold *= this.factor;
在平时的开发中,我们不要轻易修改装载因子。默认值0.75是权衡空间效率和时间效率,精心挑选出来的,除非我们对时间和空间有比较特殊的要求,比如,如果更关注时间效率,我们可以适当减小装载因子,这样哈希冲突的概率会更小,链表长度更短,增删改查操作更快,但空间消耗会更大;相反,如果更关注空间效率,我们可以适当增大装载因子,甚至可以大于1,这样table数组中的空闲空间就更少,不过,这也会导致冲突概率更大,链表长度更长,增删改查以及扩容都会变慢。
四、动态扩容
当我们调用put()函数往HashMap容器中添加键值对时,在添加完成之后,会判断容器中键值对的个数是否超过threshold(table数组大小*装载因子),如果超过,则触发动态扩容,申请一个新的table[]数组,大小为原table数组的2倍,并将原table数组中的节点,一个一个的搬移到新的table[]数组中。
扩容操作会逐一处理table数组中的每条链表。当然,对于JDK8中的HashMap,table数组中存储的还有可能是红黑树而非链表(这点待会会讲)。在扩容时,红黑树的处理方法,跟链表的处理方法类似,所以,我们拿链表的处理方法举例讲解。
因为新的table数组大小newCap是原table数组大小oldCap的两倍,所以,一些节点在新table数组中的存储位置将会改变,我们需要重新计算其对应的数组下标。但因为每个节点的key的哈希值,已经存储在节点的hash属性中,所以,不需要调用哈希函数重新计算,只需要将节点node中存储的hash值跟newCap取模即可。 取模操作仍然可以使用位运算来替代,也就是node.hash & (newCap-1),由此得到节点node搬移到新的table数组中的位置下标。
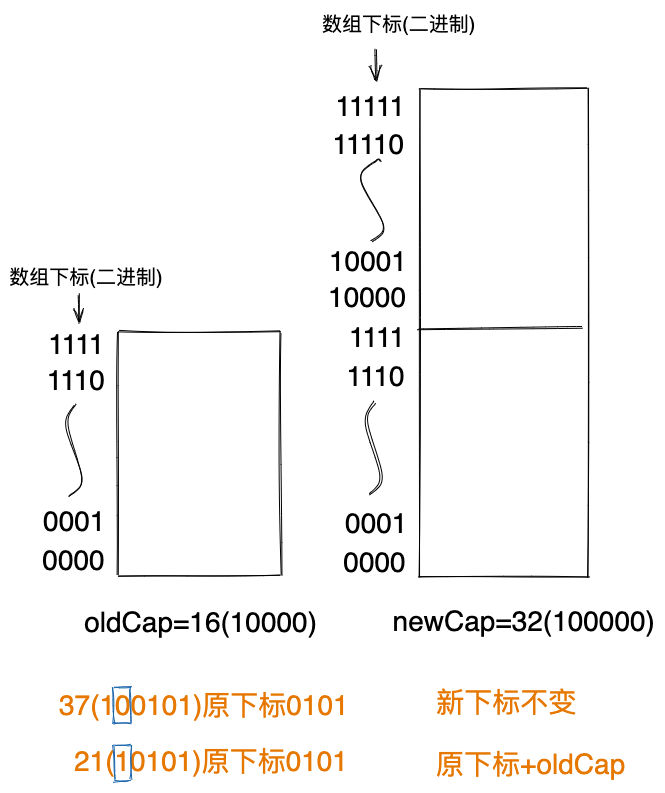
实际上,在JDK8中,新的位置下标的计算,并非通过node.hash跟newCap取模得到的,而是做了更进一步的优化:
扩容后下标的计算方式
如果node.hash & oldCap == 0,则节点在新table数组中的下标不变;
如果node.hash & oldCap != 0,则节点在新table数组中的下标变为i + oldCap(i为节点在原table数组中的下标)。
如下图举例所示,node.hash的二进制表示中,从右向左第5个二进制位为0的的节点,新的数组下标未变,从右向左第5个二进制位为0的的节点,新的数组下标为原下标+16(二进制10000)。
扫描table数组中的每一条链表,根据节点在新table数组中的下标是否更改,将链表中的节点分配到lo链表或hi链表。lo链表中存储的是下标值未变的节点(节点在table数组中存储的位置下标为i,在新的table数组中也是i),hi链表中存储的是下标值有所改变的节点(节点在新的table数组中存储的位置下标变为j)。处理完一条链表之后,将lo链表存储到新的table数组中下标为i的位置,将hi链表存储到新的table数组中下标为j的位置。
五、链表树化
尽管我们可以通过装载因子,限制HashMap容器中不会装载太多的键值对,但这只能限制平均链表长度,对于单个链表的长度,我们无法限制。如下代码所示,12个键值对存储在table数组中下标为1的链表中。
Map<Integer, String> map = new HashMap<>(); //默认table大小为16
for (int i = 0; i < 12; ++i) { //16*0.75=12,超过12个键值对才扩容
map.put(1+i*16, "value"+i);
}
当链表长度过长时,HashMap上的增删改查操作都需要遍历链表(增加键值对的时候需要查看这个键是否已经存在,所以也需要查找),所以都会变慢。针对这种情况,JDK8做了优化,当某个链表中的节点个数大于等于8(此值定义在HashMap类的静态常量TREEIFY_THRESHOLD中),并且table数组的大小大于等于64时,将会把链表转化为红黑树,我们把这个过程叫做treeify(树化)。对于长度为n的链表,增删改查的时间复杂度为O(n),而对于节点个数为n的红黑树来说,增删改查的时间复杂度是O(logn)。显然,性能提高了很多。
需要注意的是,如果table数组长度小于64,即便链表中的节点个数大于等于8,也不会触发treeify,而是会触发扩容操作,试图通过扩容,将长链表拆分为短链表。这样做的原因是,小数据量的情况下,扩容要比treeify更简单,更省时间。
当红黑树中节点个数比较少时,HashMap会再将其转换回链表。毕竟维护红黑树平衡的成本比较高,对于少许节点,使用链表存储反倒会比红黑树高效。红黑树转换为链表的过程,叫做untreeify。触发untreeify的场景有两个,一个是删除键值对时,另一个是扩容时。
在删除键值对时,如果红黑树中的节点个数变得很少,那么就触发untreeify。不过,是否触发untreeify,并非直接由红黑树中的节点个数来决定,而是通过判断其结构来决定。当红黑树的结构满足如下代码所示的条件时,便会触发untreeify。
if (root == null || (movable && (root.right == null
|| (rl = root.left) == null
|| rl.left == null))) {
tab[index] = first.untreeify(map); // too small
return;
}
通过分析此时红黑树的结构,我们反推得到这样的结论:以上结构的红黑树的节点个数应该处于[2,6]之间。也就是说,触发untreeify时,红黑树的节点个数有可能是2个、3个、4个、5个、6个,红黑树结构的不同,导致触发untreeify时节点的个数不同,但红黑树中节点个数超过6个时,肯定不会触发untreeify。
尽管treeify的阈值是8,但是untreeify的阈值却不是8,而是[2,6]之间的某个数。之所以treeify的阈值和untreeify的阈值不相等,是为了避免频繁的插入删除操作,导致节点个数在7、8之间频繁波动,进而导致链表和红黑树之间频繁的转换。毕竟转换操作也是耗时的。
我们再来看另一个触发untreeify的场景,那就是扩容时。前面讲到,扩容时,每一条链表都会分割为lo和hi两条链表,同理,每一个红黑树也会分割为lt和ht两个红黑树,lt中存储的是下标位置不变的节点,ht中存储的是下标位置变化的节点。不过,我们在构建lt和ht之前,会先统计属于lt的的节点个数lc,以及属于ht的节点个数hc,如果lc小于等于6(此值定义在HashMap的静态常量UNTREEIFY_THRESHOLD中),在新的table数组中,HashMap会使用链表来存储下标不变的节点。同理,如果hc小于等于6,在新的table数组中,HashMap会使用链表来存储下标改变的节点。
六、默认装载因子为什么是0.75?
上一节中,我们讲到,装载因子的默认值为0.75。那么0.75这个值是从何而来的呢?默认值为啥不是0.6、0.8等其他值呢?我们先来看Java本身对这个值的解释。如下所示。以下内容来自JDK8中HashMap源码中的注释。
* <p>As a general rule, the default load factor (.75) offers a good
* tradeoff between time and space costs. Higher values decrease the
* space overhead but increase the lookup cost (reflected in most of
* the operations of the <tt>HashMap</tt> class, including
* <tt>get</tt> and <tt>put</tt>). The expected number of entries in
* the map and its load factor should be taken into account when
* setting its initial capacity, so as to minimize the number of
* rehash operations. If the initial capacity is greater than the
* maximum number of entries divided by the load factor, no rehash
* operations will ever occur.
在注释中,HashMap的开发者给出了一些选择0.75为装载因子默认值的理由,意思大概是说,这个值是权衡时间效率和空间效率之后的结果。如果装载因子太小,会导致空间浪费太大;如果装载因子太大,会导致各个操作的执行效率太低。
那么,对于装载因子来说,多小才算是太小?多大才算是太大呢?
尽管我们无非给出一个标准的答案,但是,按照常理,我们可以预估一个范围,装载因子应该处于0.5~1之间,小于等于0.5就算太小,大于等于1就算太大。为什么这么说呢?我们进一步解释。
如果装载因子为0.5,那么当数组大小为n,存储元素超过n/2时,就会触发扩容,永远都只有一半的空间可用,一半的空间被浪费。如果n比较大,那么浪费的空间就相当可观了。所以,从感性认识上来讲,0.5这个值应该是装载因子的底线了。
如果装载因子为1,n个元素存储到长度为n的数组中,那么哈希表中发生冲突的概率会非常高。你可能会说,即便存在一些冲突,又有什么关系呢?冲突的数据会放入链表,链表很短的情况下,对HashMap性能的影响似乎不大。
在《数据结构与算法之美》中,我们讲到两种解决冲突的常用方法:链表法和开放寻址法。对比两种方法,链表法确实会比开放寻址法,对冲突的容忍度更高。采用开放寻址法解决冲突的哈希表,装载因子最大值为1。当装载因子接近1时,各个操作的执行速度就已经非常慢了。但对于链表法解决冲突的哈希表来说,即便装载因子设置为大于1的值,比如2,也只不过会导致链表的平均长度变为2而已,增删改查各个操作的时间复杂度仍然是O(1)的。
不过,时间复杂度只能粗略表明执行效率,对于HashMap这种非常常用的容器来说,其性能的优化应该做到极致。如果链表平均长度变为2,那么,尽管增删改查的时间复杂度未变,但粗略估算,执行时间将会变为原来的2倍。性能下降为原来的1/2,显然是不容忽视的。
实际上,不管是用链表来解决冲突,还是链表树化,这些措施都只是无奈之举。万一出现了哈希冲突、链表过长这些极端情况,我们可以通过链表和红黑树来兜底解决。在设计HashMap时,我们追求的理想情况是几乎没有冲突,也就说,链表平均长度不超过1,这样性能才能达到最高。为了做到这一点,即便HashMap采用链表法解决冲突,装载因子也不能超过1。
综上所述,我们已经明确了,装载因子必须在0.5~1之间。那么,HashMap的开发者为什么选择了其中的0.75而非其他值作为装载因子的默认值呢?
尽管有资料解释,0.75这个值可以利用二项分布的概率计算公式来求得,但是其推导过程做了不合理的假设:每次插入数据,发生冲突和不发生冲突的概率相同,均为0.5。假设都不合理,推导和结论就更无正确可言。所以,这里我们就不展开讲解利用二项分布的概率计算公式的推导方法了。
至于为什么选择0.75作为装载因子的默认值,我觉得很有可能就如HashMap源码中的注释所说:“As a general rule...”,0.75这个值可能也只不过是作者在一个合理范围内随意选择的值。不过,我们也可以大胆猜测一下,这里随意可能也并没那么随意。我们前面讲到,table数组的大小为2的幂次方,也就是2、4、8、16...这样的数,默认table数组大小n为16,当然,我们也可以将其改为其他2的幂次方值。触发扩容的阈值threshold是由公式n*loadFactor计算得到的,如果要保证threhold的值在任何情况下都为整数,那么0.5~1之间(不包含0.5和1),我们只能选择0.75作为loadFactor的值。你可能说,如果table数组的大小n被设置为2,即便loadFactor为0.75,threshold也不为整数,这种情况改该怎么办?实际上这种情况不可能发生,没人会将table数组大小设置为2。
七、链表树化阈值为什么是8?
装载因子限定的是链表的平均长度,用来保证HashMap的整体性能。链表树化限定的是链表长度的最大值,用来保证HashMap的最差情况下的性能。不过,链表树化比较耗时,并且红黑树的节点包含左右两个指针,而链表的节点只包含next指针,存储同样多的数据,红黑树占用的空间要比链表大,所以,我们希望链表树化这种情况极少发生。
上一节中,我们讲到,链表树化的阈值为8,只有链表中节点的个数大于等于8时,才会触发树化操作。那么这里的8是如何得来的呢?为什么不是5、6、7等其他值呢?
要解释8的由来,我们需要用到一个统计学的知识:泊松分布。泊松分布用来表示在某个单位时间内(比如一天、一周、一小时,可以随意定义),某个事件发生的频率对应的概率分布。我们举例解释一下。一个月内一台机器发生事故的平均次数是5次,但5只是平均值,有的月份事故会多点,有的月份事故会少点,一般来讲,事故发生的频率对应的概率分布如下图所示。事故发生5次的概率最大,事故发生次数远大于5或者远小于5的概率会很低。
虽然我们知道大概的概率分布图,但是如果我们想要知道,一个月内机器发生k次事故的概率具体是多少,该如何计算呢?这时候泊松分布就出场了。科学家发现,在单位时间内很多事件发生的频率对应的概率分布具有相同的特点,如上图所示,比如一天内出生孩子的个数、一周内下雨天数等等。科学家将这类概率分布,叫做泊松分布,并且为它设计了概率计算公式,让我们能够通过公式,轻松计算出某件事情发生k次对应的概率。泊松分布的概率计算公式如下所示。
其中,e为数学常数,值约等于2.71828,λ为事件发生的平均次数。如果我们要计算一个月内机器发生3次的概率,那么将k=3,λ=5套入公式,如下所示,最终计算得到的概率约为0.14。
了解了泊松分布之后,我们回过头来看链表树化阈值问题。实际上,对于一个HashMap来说,链表的长度各式各样,有的为1,有的为2,还有的为0......链表的长度对应的概率分布也符合泊松分布。因此,我们就可以通过泊松分布的概率计算公式,来计算链表长度为k对应的概率。公式中的λ值对应的是链表长度的平均值。那么,链表长度的平均值是多少呢?
我们知道,HashMap的默认装载因子为0.75,只有当即将扩容时,链表的平均长度才为0.75,所以,在大部分情况下,链表的平均长度都小于0.75,我们选择0.5作为大部分情况下链表的平均长度,也就是说λ等于0.5。当然,这里的0.5是预估值,因为我们无法给出链表平均长度的精确值。将λ带入泊松分布的概率计算公式,我们得到链表长度对应的概率的计算公式,如下所示。
我们将k=0、1、2...8依次带入上述公式,得到链表长度分别为0、1、2...8对应的概率值,如下所示。从中我们可以发现,链表长度达到8这种情况发生的概率为千万分之六,已经非常低了。也就是说,在哈希函数设计合理(比如哈希值比较随机)、装载因子设置合理(比如0.75)的情况下,链表长度大于等于8这种情况极少发生。为了尽可能避免链表树化,于是,我们选择8作为链表树化的阈值。
链表长度:概率值
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
你可能会说,链表长度为9的概率会更低,为什么不选择9作为树化阈值呢?这是因为链表长度越长,HashMap的性能就越低,在避免树化的同时,链表的最大长度(也就是树化阈值)要尽量小。所以,8、9概率都很低的情况下,我们肯定选择较小的那一个8了。
八、课后思考题
当调用put()函数添加键值对时,在添加完成之后,会检查是否需要扩容,那么,为什么是在添加完成之后再扩容,而不是先检查是否需要扩容再添加键值对呢?
请编程测试HashMap在装载因子为0.75和2时的性能差距。