Lock
Lock
JUC Lock锁的特性及用法
提示
相对Java synchronized,JUC Lock有何优势?
尽管synchronized的底层原理比较复杂,但是使用起来却非常简单。从本节开始,我们来学习另外一种互斥锁:JUC并发包提供的Lock锁。相对于synchronized内置锁,JUC Lock锁提供了更加丰富的特性,比如支持公平锁、可中断锁、非阻塞锁、可超时锁等。本节,我们就详细介绍一下JUC Lock锁的各种特性及其用法。下一节,我们再结合AQS,对这些特性的实现原理做深入讲解。
1、JUC锁概述
JUC提供了几种不同的锁,继承和实现层次关系如下图所示。本节重点讲解Lock锁(也就是Lock接口及其实现类ReentrantLock),下下节讲解读写锁(也就是ReadWriteLock接口及其实现类ReetrantReadWriteLock)以及读写锁的升级版StampedLock。
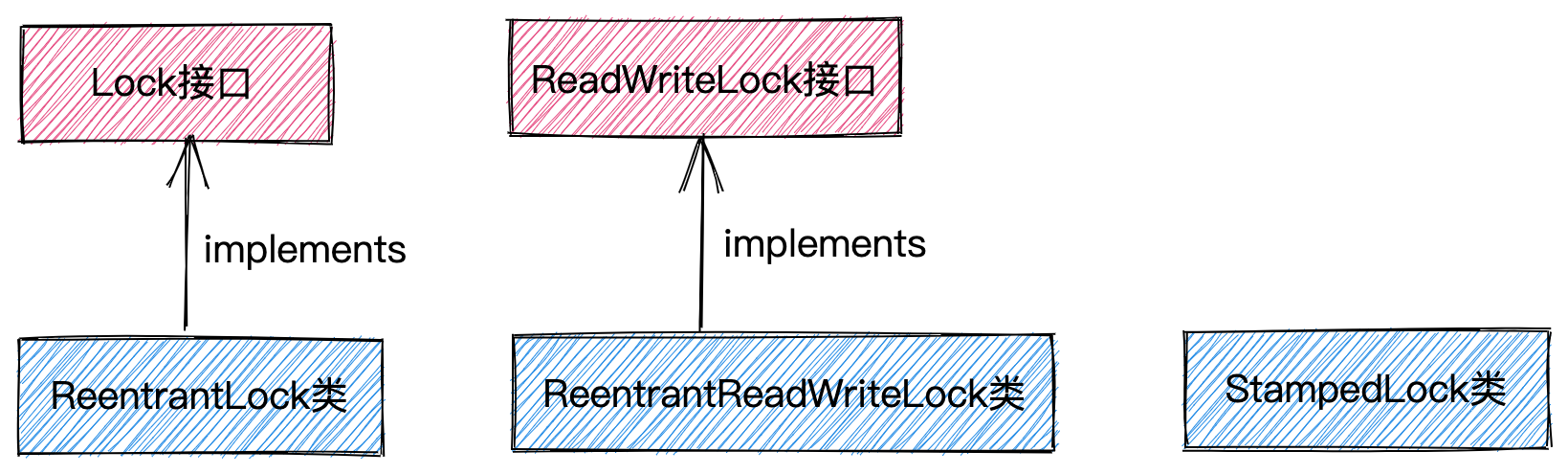
我们先来看Lock接口,其接口定义如下所示。因为在平时的开发中,我们用到的锁都是可重入锁,所以,Lock接口只有 一个可重入的实现类ReentrantLock。
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
2、可重入锁
可重入锁指的是可以被同一个线程多次加锁的锁。注意,这里说的多次加锁,并不是说解锁之后再次加锁,而是在锁没有解锁前再次加锁。
如下代码所示,为了保证线程安全,getEvenSeq()函数和increment()函数中的代码都加了锁。getEvenSeq()函数调用increment()函数,导致getEvenSeq()函数在锁释放前再次加锁。如果JUC提供的锁不支持可重入特性,那么,getEvenSeq()中的第二次加锁需要等待锁释放,而锁释放又需要加锁之后才能执行,于是,getEvenSeq()就会出现死锁。
public class Demo {
Lock lock = new ReentrantLock();
private int seq = 0;
public int getEvenSeq() {
lock.lock();
try {
// ...省略其他操作...
if (seq%2 == 1) {
increment();
}
return seq;
} finally {
lock.unlock();
}
}
public void increment() {
lock.lock();
seq++;
lock.unlock();
}
}
对于上述代码,我们稍微解释一下。之所以getEvenSeq()函数使用finally来释放锁,是为了避免代码抛出异常而导致锁无法正常释放。而之所以increment()函数没有使用finally来释放锁,是因为代码比较简单,我们可以确定代码不会抛出异常。
JUC提供的锁都是可重入锁。实际上,Java synchronized内置锁也是可重入锁。从侧面上,我们也可以得出,可重入是对锁的基本要求。为了实现可重入特性,可重入锁中需要有一个变量来记录重入的次数。每重入一次,变量就增一;每解锁一次(调用unlock()或退出synchronized代码块),变量就减一,直到变量值为0时,才会释放锁唤醒其他线程执行。
3、公平锁
对于公平锁来说,线程会按照请求锁的先后顺序来获得锁,也就是我们经常说的FIFO。对于非公平锁,多个线程请求锁时,非公平锁无法保证这些线程获取锁的先后顺序,有可能后申请锁的线程先获取到锁。
Java将synchronized设计为只支持非公平锁,而JUC提供的ReentrantLock既支持公平锁,也支持非公平锁。默认情况下,ReentrantLock为非公平锁。如果需要创建公平锁,那么我们只需要在创建ReentrantLock对象时,将构造函数的参数设置为true即可。如下代码所示。
Lock lock = new ReentrantLock(true); // 公平锁
接下来,我们再来看下,公平锁和非公平锁的实现原理。
在讲解synchronized的底层实现原理时,我们讲到,多个线程竞争锁,竞争到锁的线程就去执行任务了,没有竞争到锁的线程会放入Monitor锁的_cxq队列中等待锁,并且还需要调用park()函数阻塞自己。当持有锁的线程释放锁时,它会从_EntryList队列中取一个线程,取消阻塞状态,让它去重新竞争锁,而不是直接将锁给它。而此时如果有新来的线程也要竞争这个锁,新来的线程有可能不需要排队,就能直接获取锁,显然,这是一种“插队”的行为。
当然,我们也可以让synchronzied支持公平锁。实现起来也很简单。新来的线程在申请获取锁时,如果_EntryList队列和_cxq队列中有排队等待锁的线程,那么,不管此时锁有没有释放,新来的线程都直接放入_cxq队列中排队,按照先来后到的顺序等待锁,以避免新来线程的“插队”行为。这样实现的锁就是公平锁。
实际上,ReentrantLock实现公平锁和非公平锁的方法,跟上述synchronized的实现方法,其基本原理是一致的。区别在于,ReentrantLock使用AQS(抽象队列同步器)来存储排队等待锁的线程。关于AQS,我们在下一节中详细讲解。
既然实现公平锁并不复杂,而且从直觉上,公平锁比非公平锁更加合理,但是,synchronized为什么只支持非公平锁?主要原因有以下3个方面。
1)历史的原因:synchronized早期开发时没有考虑那么全面;
2)需求的原因:绝大部分业务场景都不需要严格规定线程的执行顺序,如果真的需要,我们可以通过条件变量(wait()、notify()等)等同步工具来实现;
3)性能的原因:非公平锁的性能比公平锁的性能更好。我们知道,加入等待队列并调用park()函数阻塞线程,涉及到用户态和内核态的切换,是比较耗时。对于非公平锁来说,新来的线程直接竞争锁,这样就有可能避免加入等待队列并调用费时的park()函数。
不过,非公平锁也有缺点,在极端情况下,线程竞争锁激烈,频繁有新来的线程插队,就有可能导致,排在等待队列中的线程,迟迟无法获取到锁。
4、可中断锁
对于synchronized锁来说,线程在阻塞等待synchronized锁时是无法响应中断的。而JUC Lock接口提供了lockInterruptibly()函数,支持可响应中断的方式来请求锁。示例代码如下所示。主线程先获取到了锁并一直持有,之后线程t1调用lockInterruptibly()请求锁,因为锁被主线程持有,所以,线程t1阻塞等待。主线程调用interrupt()函数向线程t1发起中断请求,线程t1响应中断请求,退出阻塞等待锁,并打印“I am interrupted”。
public class Demo {
private static Lock lock = new ReentrantLock();
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
System.out.println("I am interrupted");
return;
}
try {
System.out.println("I got lock");
} finally {
lock.unlock();
}
}
});
lock.lock();
t1.start();
t1.interrupt();
lock.unlock();
}
}
可中断锁一般用于线程管理中,方便关闭正在执行的线程。比如,Nginx服务器采用多线程来执行请求。当我们调用stop命令关闭Nginx服务器时,Nginx服务器可以采用中断的方式,将阻塞等待锁的线程中止,然后,合理的释放资源和妥善处理未执行完成的请求,以实现服务器的优雅关闭。
5、非阻塞锁
对于synchronized锁来说,一个线程去请求一个synchronized锁时,如果锁已经被另一个线程获取,那么,这个线程就需要阻塞等待。JUC Lock接口提供了tryLock()函数,支持非阻塞的方式获取锁。如果锁已经被其他线程获取,那么,调用tryLock()函数会直接返回错误码而非阻塞等待。示例代码如下所示。非阻塞锁的实现原理非常简单。竞争锁失败的线程不放入队列排队即可实现非阻塞锁。
public class Demo {
private Lock lock = new ReentrantLock();
public void useTryLock() {
if (lock.tryLock()) {
try {
// ...执行业务代码...
} finally {
lock.unlock();
}
} else {
// ...没有获取锁,执行其他业务代码...
}
}
}
6、可超时锁
除了提供不带参数的tryLock()函数之外,JUC Lock接口还提供给了带时间参数的tryLock()函数,支持非阻塞获取锁的同时设置超时时间。也就是说,一个线程在请求锁时,如果这个锁被其他线程持有,那么这个线程会阻塞等待一段时间。如果超过了设定的超时时间,线程仍然没有获取到锁,那么tryLock()函数将会返回错误码而不再阻塞等待。示例代码如下所示。从示例代码中,我们还可以发现,tryLock()跟lockInterruptibly()一样,也可以被中断。这样是为了避免tryLock()阻塞过长时间。
public class Demo {
private Lock lock = new ReentrantLock();
public void useTryLockWithTimeout() {
boolean locked = false;
try {
locked = lock.tryLock(100, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
System.out.println("I am interrupted");
}
if (locked) {
try {
// ...执行业务代码...
} finally {
lock.unlock();
}
} else {
// ...没有获取锁,执行其他业务代码...
}
}
}
接下来,我们再来看看可超时锁的应用场景。
在很多对响应时间比较敏感的系统中,比如面向用户的系统,从用户体验上说,请求失败给与提示,要远好于响应超时而没有反应。我们拿Tomcat等Web服务器来举例。Tomcat采用线程池的方式多线程执行用户请求。如果某个特殊请求不能并发执行,并且请求执行时间比较长,那么,请求的处理代码就需要加锁。当多个线程同时执行多个特殊请求时,有些线程就有可能因为迟迟无法获取到锁而无法执行请求。一方面,这样会导致用户请求超时,给用户带来不好的体验,另一方面,线程一直等待锁,长期被占用,无法执行其他任务,剩余可以执行用户请求的线程变少,从而加重了系统负担,导致更多请求超时。
针对以上问题,我们就可以使用带超时时间的tryLock()函数来请求锁,如果在设定的超时时间内未获取到锁,那么,线程就中止执行用户请求,返回错误信息给用户。当然,这只是保护措施,毕竟,以上问题只有在无法并发执行的特殊请求集中大量到来时才会发生。
JUC Lock底层原理
提示
如何使用AQS(抽象队列同步器)实现JUC Lock?
上一节,我们讲解了JUC Lock的各种特性,比如支持重入锁、公平锁、可中断锁、非阻塞锁、可超时锁。本节,我们就来讲一下JUC Lock的底层实现原理。JUC Lock底层主要依赖AQS来实现。AQS也是JUC中非常重要的基础组件。JUC中很多锁(Lock、ReadWriteLock)和同步工具(Condition、Semaphore、CountDownLatch)都是基于AQS来实现的。因此,在讲解JUC Lock的底层实现原理时,我们会重点讲解AQS。
一、AQS简介
AQS是抽象类AbstractQueueSynchronizer的简称,中文翻译为抽象队列同步器。
前面讲到,在Hotspot JVM中,synchronized主要依赖ObjectMonitor类来实现。类中的_cxq、_EntryList、_WaitSet用来排队线程。其中,_cxq、_EntryList用来实现锁,也就是synchronized,_WaitSet用来实现条件变量,也就是wait()和notify()。实际上,在功能上,AQS跟ObjectMonitor非常类似,都实现了排队线程、阻塞线程、唤醒线程等功能。
class ObjectMonitor {
void * volatile _object; //该Monitor锁所属的对象
void * volatile _owner; //获取到该Monitor锁的线程
ObjectWaiter * volatile _cxq; //没有获取到锁的线程暂时加入_cxq
ObjectWaiter * volatile _EntryList; //存储等待被唤醒的线程
ObjectWaiter * volatile _WaitSet; //存储调用了wait()的线程
}
不过,在实现思路上,AQS跟ObjectMonitor有所不同。首先,ObjectMonitor类是在JVM中基于C++来实现的,因为synchronized、wait()、notify()是Java语言提供的内置的语法和函数。AQS类是在JDK中基于Java语言实现的,因为JUC只是JDK中的一个并发工具包而已。其次,ObjectMonitor使用不同的队列来实现锁和同步工具,AQS使用同一个队列来实现锁和同步工具。
接下来,我们就详细讲解一下AQS的实现原理。
二、数据结构
AQS类中所包含的成员变量并不多,如下代码所示。这几个成员变量构成了AQS实现锁和同步工具所依赖的核心数据结构。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer {
private transient volatile Node head;
private transient volatile Node tail;
private volatile int state;
}
public abstract class AbstractOwnableSynchronizer {
private transient Thread exclusiveOwnerThread;
}
如上代码所示,AQS继承自AbstractOwnableSynchronizer类。AbstractOwnableSynchronizer类只包含一个成员变量exclusiveOwnerThread。AQS连带继承来的一个成员变量,总共有4个成员变量。接下来,我们依次介绍下它们。
1)state
前面在讲到synchronized的底层实现原理时,我们讲到,当多个线程竞争锁时,它们会通过CAS操作来设置ObjectMonitor中的_owner字段。谁设置成功,谁就获取了这个锁。实际上,AQS中的state的作用就类似于ObjectMonitor中的_owner字段。只不过_owner字段是一个指针,存储的是获取锁的线程,而state是一个int类型的变量,存储0、1等整型值。其中,0表示锁没有被占用,1表示锁已经被占用,大于1的数表示重入的次数。当多个线程竞争锁时,它们会通过如下所示的CAS操作来更新state的值。这里CAS指的是先检查state的值是否为0,如果是的话,将state值设置为1。谁设置成功,谁就获取了这个锁。
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
compareAndSetState()函数底层使用Unsafe类提供的native函数来实现。native函数是JVM中的C++函数。如果想要阅读native函数的代码实现,那么,我们需要查看JVM源码。实际上,compareAndSetState()函数经过层层调用,最底层仍然是依靠硬件提供的原子CAS指令来实现。
2)exclusiveOwnerThread
AQS中的exclusiveOwnerThread成员变量存储持有锁的线程,它配合state成员变量,可以实现锁的重入机制。关于重入机制的实现方式,我们稍后讲解。
3)head和tail
在ObjectMonitor中,_cxq、_EntryList用来存储等待锁的线程,_WaitSet用来存储调用了wait()函数(等待条件变量的函数)的线程。相比而言,AQS只有一个等待队列,既可以用来存储等待锁的线程,又可以用来存储等待条件变量的线程。在ObjectMonitor中,_cxq使用单链表来实现,_EntryList和_WaitSet使用双向链表来实现。在AQS中,等待队列使用双向链表来实现。双向链表的节点定义如下所示。AQS中的head和tail两个成员变量分别为双向链表的头指针和尾指针。
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile Thread thread;
volatile Node prev;
volatile Node next;
volatile int waitStatus;
Node nextWaiter;
}
三、基本原理
AQS使用模板方法模式来实现。在《设计模式之美》一书中,我们讲到,模板方法模式包含两个主要的组件:模板方法和抽象方法。模板方法包含主功能逻辑,并且依赖抽象方法来实现部分逻辑的可定制化。当使用模板方法模式时,我们需要定义一个子类,让其继承模板类,并实现其中的抽象方法,然后再使用子类创建对象,调用对象的模板方法来做编程开发。AQS的代码结构和使用方法大致也是如此。
AQS定义了8个模板方法,如下所示**。**以下8个函数可以分为2组,分别用于AQS的两种工作模式:独占模式和共享模式。其中,前4个函数用于独占模式,后4个函数用于共享模式。Lock为排它锁,因此,Lock的底层实现只会用到AQS的独占模式。ReadWriteLock中的读锁为共享锁,写锁为排它锁,因此,ReadWriteLock的底层实现既会用到AQS的独占模式,又会用到AQS的共享模式。Semaphore、CountdownLatch这些同步工具只会用到AQS的共享模式。
public final void acquire(int arg) { ... }
public final void acquireInterruptibly(int arg)
throws InterruptedException { ... }
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException { ... }
public final boolean release(int arg) { ... }
public final void acquireShared(int arg) { ... }
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException { ... }
public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout)
throws InterruptedException { ... }
public final boolean releaseShared(int arg) { ... }
**AQS提供了4个抽象方法,如下所示。**前两个抽象方法用于独占模式的4个模板方法,后两个抽象方法用于共享模式的4个模板方法。在标准的模板方法模式的代码实现中,抽象方法需要使用abstract关键字来定义,以强制子类去实现它。但以下抽象方法并没有使用abstract关键字来定义,而是给出了默认的实现,即抛出UnsupportOperationException异常。这样做是为了减少开发量,即我们不需要在子类中实现所有的抽象方法,用到哪个就实现哪个即可。
protected boolean tryAcquire(int arg) {
throw new UnsupportedOperationException();
}
protected boolean tryRelease(int arg) {
throw new UnsupportedOperationException();
}
protected int tryAcquireShared(int arg) {
throw new UnsupportedOperationException();
}
protected boolean tryReleaseShared(int arg) {
throw new UnsupportedOperationException();
}
**接下来,我们结合ReentrantLock来看下AQS如何使用。**ReentrantLock既支持非公平锁,又支持公平锁,其部分代码如下所示。ReentrantLock定义了两个继承自AQS的子类:NonfairSync和FairSync,分别用来实现非公平锁和公平锁。因为NonfairSync和FairSync的释放锁的逻辑是一样的,所以,NonfairSync和FairSync又抽象出了一个公共的父类Sync。注意,为了更清晰的展示原理,在不改变代码逻辑的情况下,我对本节中的代码均做了少许调整。
public class ReentrantLock implements Lock {
private final Sync sync;
abstract static class Sync extends AbstractQueuedSynchronizer { ... }
static final class NonfairSync extends Sync { ... }
static final class FairSync extends Sync { ... }
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
public void lock() {
sync.acquire(1);
}
public void unlock() {
sync.release(1);
}
//...省略其他方法...
}
ReentrantLock中的lock()函数调用AQS的acquire()模板方法来实现,unlock()函数调用AQS的release()模板方法来实现。接下来,我们就来看下acquire()和release()的底层实现原理。
1)acquire()模板方法
acquire()的代码实现如下所示。acquire()的代码实现看似非常简单,实际上,其包含的逻辑可不少。acquire()先调用tryAcquire()方法去竞争获取锁。如果tryAcquire()获取锁成功,acquire()就直接返回。如果tryAcquire()获取锁失败,那么就会执行addWaiter(),将线程包裹为Node节点放入等待队列的尾部,最后调用acquireQueued()阻塞当前线程。selfInterrupt()用来处理中断,如果在等待锁的过程中,线程被其他线程中断,那么,在获取锁之后,将线程的中断标记设置为true。这里的中断不是重点,简单了解即可。
public final void acquire(int arg) {
// tryAcquire() -> addWaiter() -> acquireQueued()
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
tryAcquire()是抽象方法,在NonfairSync和FairSync中实现。代码如下所示。我对代码做了详细的注释,这里就不再重述其中的代码逻辑了。两个tryAcquire()方法的代码实现区别也不大,唯一的区别是在获取锁之前,FairSync会调用hasQueuedPredecessors()函数,查看等待队列中是否有线程在排队,如果有,那么tryAcquire()返回false,表示竞争锁失败,从而禁止“插队”获取锁的行为。
static final class NonfairSync extends Sync {
// 尝试获取锁,成功返回true,失败返回false。AQS用于实现锁时,acquires=1
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState(); //获取state值
if (c == 0) { //1、锁没有被其他线程占用
if (compareAndSetState(0, acquires)) { //CAS设置state值为1
setExclusiveOwnerThread(current); //设置exclusiveOwnerThread
return true; //获取锁成功
}
} else if (current == getExclusiveOwnerThread()) { //2、锁可重入
int nextc = c + acquires; // state+1
if (nextc < 0) //重入次数太多,超过了int最大值,溢出为负数,此情况罕见
throw new Error("Maximum lock count exceeded");
setState(nextc); // state=state+1,state记录重入的次数,解锁的时候用
return true; //获取锁成功
}
return false; //3、锁被其他线程占用
}
}
static final class FairSync extends Sync {
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) { //1、锁没有被占用
if (!hasQueuedPredecessors() && //等待队列中没有线程时才获取锁
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) { //2、锁可重入
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
addWaiter()函数的代码实现如下所示。在多线程环境下,往链表尾部添加节点会存在线程安全问题,因此,下面的代码采用自旋+CAS操作的方式来解决这个问题,这种方式在AtomicInteger等原子类中被大量使用,我们在讲解原子类时再详细讲解。除此之外,addWaiter()函数还需要特殊处理链表为空的情况,同样也存在线程安全问题,也同样是采用自旋+CAS操作解决的。注意,为了方便操作,AQS中的双向链表带有虚拟头节点。关于虚拟头节点,你可以阅读我的《数据结构与算法之美》这本书来了解。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 自旋执行CAS操作,直到成功为止
for (;;) {
Node t = tail;
if (t == null) { //链表为空,添加虚拟头节点
//CAS操作解决添加虚拟头节点的线程安全问题
if (compareAndSetHead(null, new Node()))
tail = head;
} else { //链表不为空
node.prev = t;
//CAS操作解决了同时往链表尾部添加节点时的线程安全问题
if (compareAndSetTail(t, node)) {
t.next = node;
return node;
}
}
}
}
acquireQueued()的代码实现如下所示,主要包含两部分逻辑:使用tryAcquire()函数来竞争锁和使用park()函数来阻塞线程,并且采用for循环来交替执行这两个逻辑。之所以这样做,是因为线程在被唤醒(取消阻塞)之后,并不是直接获取锁,而是需要重新竞争锁,如果竞争失败,那么就需要再次被阻塞。关于代码中涉及的中断的处理逻辑,我们在本节中的中断机制小结中讲解。
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
//自旋(竞争锁+阻塞),因为被唤醒之后不一定能竞争到锁,所以要自旋
for (;;) {
final Node p = node.predecessor();
// 如果线程是被中断唤醒的,那么p就不一定等于head,也就不能去竞争锁
if (p == head && tryAcquire(arg)) {
setHead(node); //把node设置成虚拟头节点,也就相当于将它删除
p.next = null; // help GC
failed = false;
return interrupted;
}
// 调用park()函数来阻塞线程,线程被唤醒有以下两种情况:
// 1、其他线程调用unpark()函数唤醒,此时,节点位于虚拟头节点的下一个,p==head
// 2、被中断唤醒,此时,节点不一定是虚拟头节点的下一个,p不一定等于head
if (parkAndCheckInterrupt()) interrupted = true;
}
} finally { //以上过程只要抛出异常,都要将这个节点标记为CANCELLED,等待被删除
if (failed) cancelAcquire(node);
}
}
private final boolean parkAndCheckInterrupt() {
//底层调用JVM提供的native park()函数来实现,跟synchronized使用的park()函数相同
LockSupport.park(this);
return Thread.interrupted();
}
2)release()模板方法
release()模板方法的代码实现比较简单,如下所示,主要包含两部分逻辑:使用tryRelease()函数释放锁和调用unpark()函数唤醒链首节点(除虚拟头节点之外)对应的线程。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h); //内部调用unpark()函数
return true;
}
return false;
}
tryRelease()是抽象方法。不管是公平锁还是非公平锁,tryRelease()释放锁的逻辑相同,如下所示。代码中有详细的注释,这里就不再赘述代码逻辑了。
static final class Sync extends AbstractQueuedSynchronizer {
// 释放锁,成功返回true,失败返回false。AQS用于实现锁时,releases=1
protected final boolean tryRelease(int releases) {
int c = getState() - releases; // state-1
//不持有锁的线程去释放锁,这不是瞎胡闹嘛,抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
if (c == 0) { //state-1之后为0,解锁
setExclusiveOwnerThread(null);
return true;
}
setState(c); //state-1之后不为0,说明锁被重入多次,还不能解锁。
return false;
}
}
从上述分析,我们可以发现,模板方法acquire()包含加锁的所有逻辑,比如竞争锁、竞争失败之后的排队、阻塞,而竞争锁这部分逻辑由抽象方法tryAcquire()来实现,因此,我们可以在子类中定制如何竞争锁,比如是否支持重入锁、是否支持公平锁等。模板方法release()包含解锁的所有逻辑,比如释放锁、唤醒等待线程,而释放锁这部分逻辑由抽象方法tryRelease()来实现,因此,我们也可以在子类中定制如何释放锁。
四、中断机制
在独占模式下,AQS中对应的模板方法有4个。前面讲到了两个:acquire()和release(),分别用来实现ReentrantLock中的lock()和unlock()函数。接下来,我们再来看下另外两个:aquireInterruptibly()和tryAquireNanos(),它们分别用来实现ReentrantLock中的lockInterruptibly()函数和带超时时间的tryLock()函数。具体如下代码所示。
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit)
throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
acquireInterruptibly()模板方法对应的代码实现如下所示。代码实现也非常简单,如果线程被中断,则抛出InterruptedException异常,否则,调用tryAcquire()竞争获取锁,如果获取锁成功,则直接返回,否则,调用doAcquireInterruptible()函数。
public final void acquireInterruptibly(int arg) throws InterruptedException {
if (Thread.interrupted()) throw new InterruptedException();
if (!tryAcquire(arg)) doAcquireInterruptibly(arg);
}
doAcquireInterruptibly()函数的代码实现如下所示,跟之前讲的acquireQueued()函数的代码实现非常相似。唯一的区别是对中断的响应处理不同。parkAndCheckInterrupt()函数返回有两种情况,一种是其他线程调用了unpark()函数取消阻塞,另一种是被其他线程中断。对于第二种情况,acquireQueued()函数不对中断做任何处理,继续等待锁。doAcquireInterruptibly()函数则是将中断包裹为InterruptedException异常抛出,终止等待锁。因此,调用acquire()实现的lock()函数,在阻塞等待锁时,不会被中断。调用acquireInterruptibly()实现的lockInterruptibly()函数,在阻塞等待锁时,可以被中断。
private void doAcquireInterruptibly(int arg) throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (parkAndCheckInterrupt())
throw new InterruptedException(); //区别:抛出异常!
}
} finally {
if (failed) cancelAcquire(node);
}
}
五、超时机制
tryAquireNanos()模板方法的代码实现如下所示。代码实现也非常简单,如果线程被中断,则直接抛出InterruptedException异常,否则,调用tryAcquire()竞争获取锁,如果获取锁成功,则直接返回,否则,调用doAcquireNanos()函数。
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted()) throw new InterruptedException();
return tryAcquire(arg) || doAcquireNanos(arg, nanosTimeout);
}
doAcquireNanos()函数的代码实现如下所示。在doAcquireInterruptibly()函数的代码实现的基础之上,doAcquireNanos()函数又添加了对超时的处理机制。因此,使用tryAcquireNanos()实现的ReentrantLock的tryLock()函数,既支持中断,又支持设置超时时间。
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L) return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L) return false;
if (nanosTimeout > spinForTimeoutThreshold) //不着急阻塞,先自旋一下
LockSupport.parkNanos(this, nanosTimeout); //超时阻塞
if (Thread.interrupted()) throw new InterruptedException();
}
} finally {
if (failed) cancelAcquire(node);
}
}
为了支持超时阻塞,在阻塞线程时,doAcquireNanos()函数调用parkNanos()函数。parkNanos()函数的实现方式跟park()函数差不多。在讲解synchronized的时候,我们提到,park()函数的代码实现大致如下所示。parkNanos()只需要将其中的pthread_cond_wait()函数替换成了pthread_cond_timewait()函数便可以实现超时等待。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
boolean ready = false;
void park() {
...
pthread_mutex_lock(&mutex);
while (!ready) {
pthread_cond_wait(&cond, &mutex);
}
ready = false;
pthread_mutex_unlock(&mutex);
...
}
读写锁和StampedLock
提示
ReadWriteLock的锁升级与锁降级及其底层实现原理
在上上节中,我们讲到,JUC提供的锁有三类:普通互斥锁(Lock和ReentrantLock)、读写锁(ReadWriteLock和ReentrantReadWriteLock)、StampedLock、上两节,我们介绍了JUC中的Lock,并且讲解了其底层实现原理,特别是AQS。本节,我们讲解读写锁和StampedLock。
一、读写锁的基本用法
为了提高多线程环境下代码执行的并发度,两个读操作是可以并发执行的,但是,读操作和写操作不能并发执行,同理,写操作和写操作也不能并发执行。为了满足这样特殊的加锁需求,JUC提供了读写锁(ReadWriteLock接口和ReentrantReadWriteLock类)。
ReadWriteLock接口的定义,如下所示。跟Lock和ReentrantLock的关系类似,ReadWriteLock也只有一个可重入的实现类ReentrantReadWriteLock。
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}
ReadWriteLock接口中只包含两个函数,其中,readLock()函数返回读锁。读锁用来给读操作加锁。writeLock()函数返回写锁。写锁用来给写操作加锁。读锁是一种共享锁,读锁可以被多个线程同时获取。写锁是排它锁。写锁同时只能被一个线程获取。除此之外,读锁和写锁之间也是排它的。因此,读写锁一般用于读多写少的场景。读写锁的使用示例代码如下所示。两个线程允许并发执行get()函数。
public class Demo {
private List<String> list = new LinkedList<>();
private ReadWriteLock rwLock = new ReentrantReadWriteLock();
private Lock rLock = rwLock.readLock(); //读锁
private Lock wLock = rwLock.writeLock(); //写锁
public void add(int idx, String elem) {
wLock.lock(); //加写锁
try {
list.add(idx, elem);
} finally {
wLock.unlock(); //释放写锁
}
}
public String get(int idx) {
rLock.lock(); //加读锁
try {
return list.get(idx);
} finally {
rLock.unlock(); //释放读锁
}
}
}
ReentrantReadWriteLock既支持公平锁又支持非公平锁。跟ReentrantLock的公平锁和非公平锁的构建方法一样,ReentrantReadWriteLock默认为非公平锁。如果要成创建公平锁,我们只需要在创建ReentrantReadWriteLock对象时,将构造函数的参数设置为true即可,示例代码如下所示。
ReadWriteLock rwLock = new ReentrantReadWriteLock(true); //公平锁
ReadWriteLock rwLock = new ReentrantReadWriteLock(false); //非公平锁
ReadWriteLock rwLock = new ReentrantReadWriteLock(); //默认为非公平锁
二、锁升级和锁降级
前面讲到,绝大部分锁都是可重入锁,读写锁也不例外。一个线程获取读锁之后,在读锁释放前,还可以再次获取读锁。同理,一个线程获取写锁之后,在写锁释放前,还可以再次获取写锁。但是,一个线程在获取读锁之后,在读锁释放前,是否还能再获取写锁?还有,一个线程在获取写锁之后,在写锁释放前,是否还能再获取读锁呢?
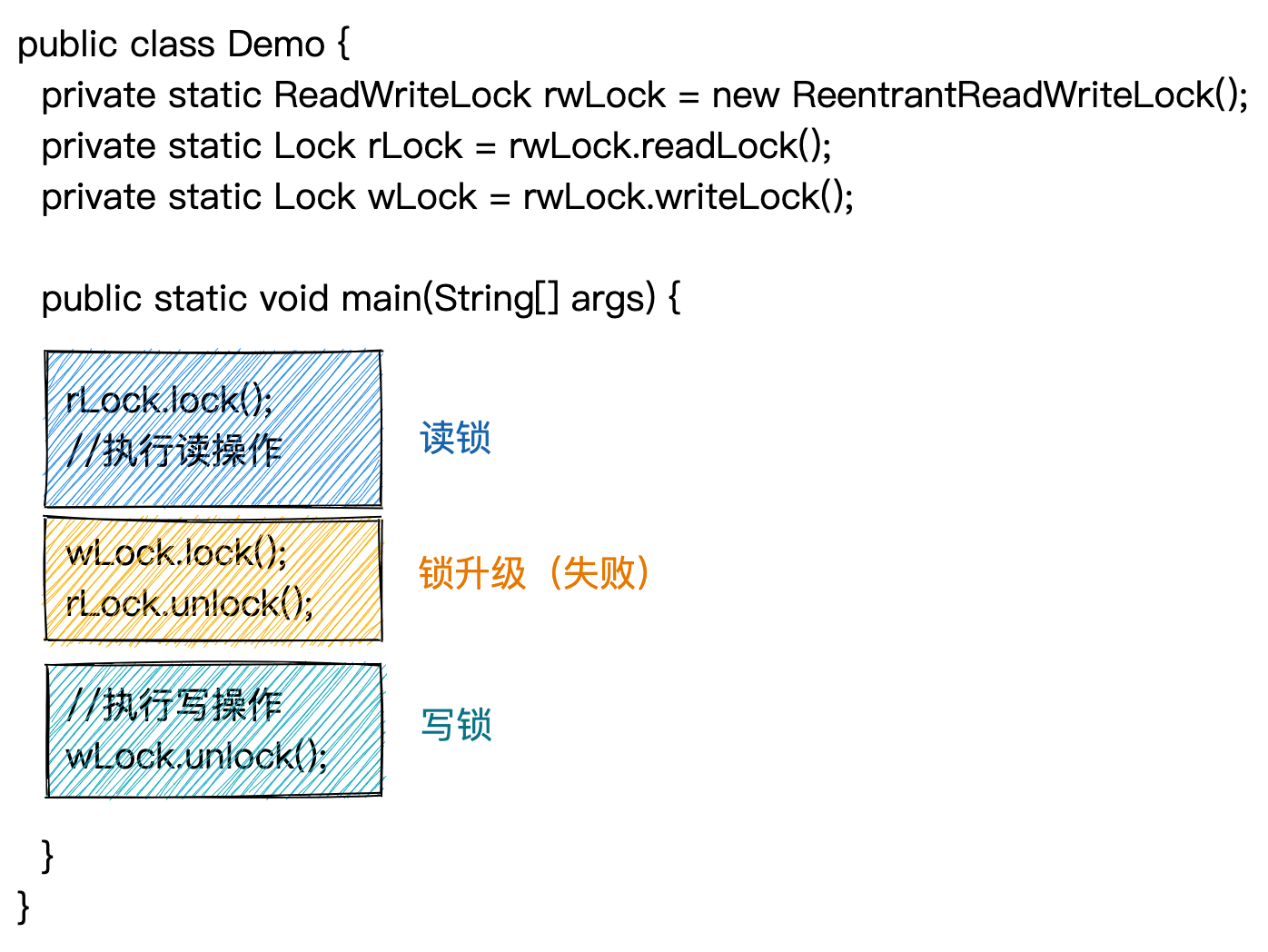
读写锁不支持锁升级,也就是,一个线程获取读锁之后,在读锁释放前,不可以再获取写锁。这是因为在一个线程获取读锁时,有可能同时还有其他线程也获取了读锁,如果将一个线程的读锁升级为写锁,那么就有可能违背了读写锁中读锁和写锁互斥的要求。示例代码如下所示。
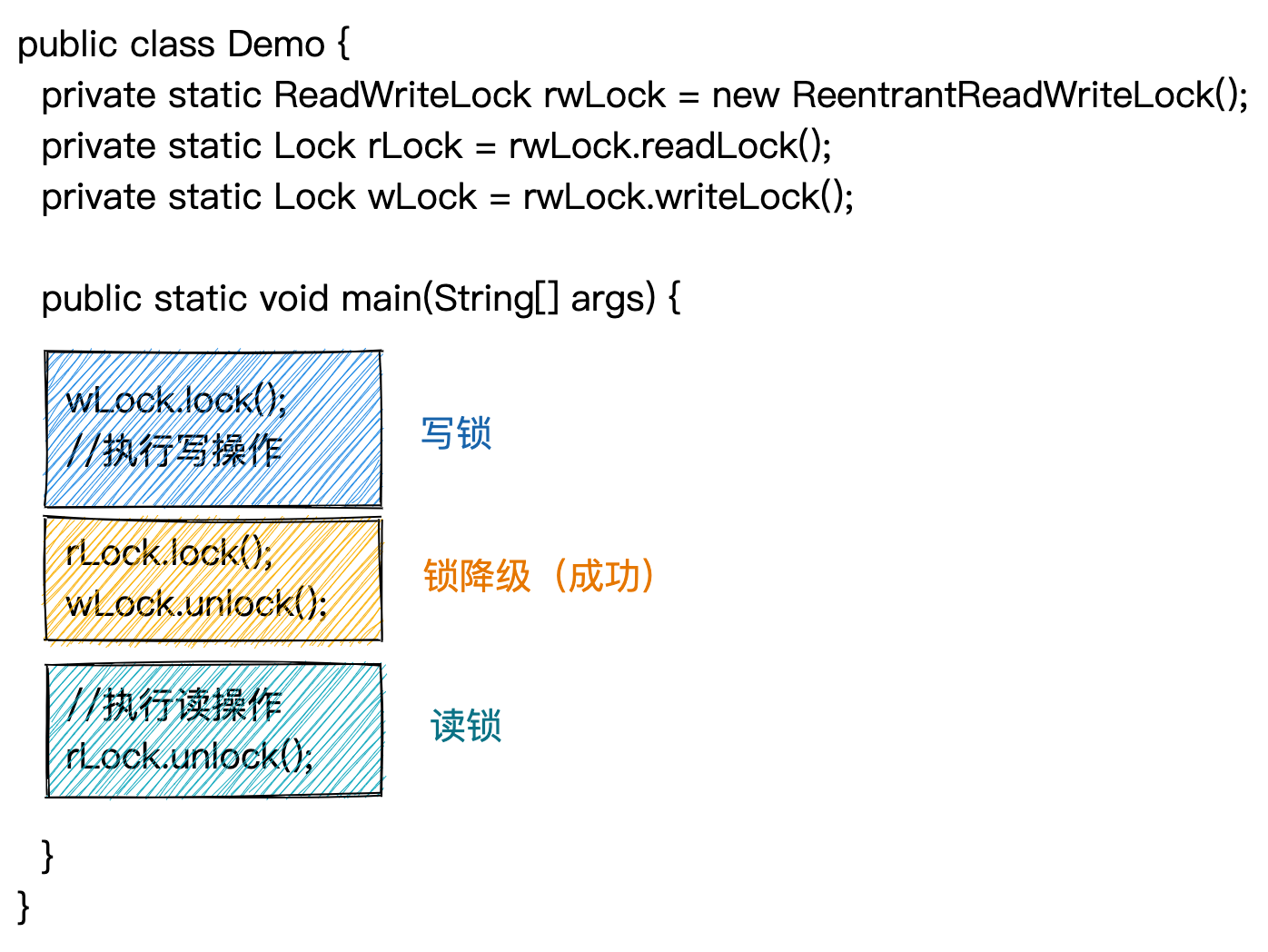
读写锁支持锁降级,也就是,一个线程在获取写锁之后,在写锁释放前,可以再获取读锁。当写锁释放之后,线程持有的锁从写锁降级为读锁,示例代码如下所示。
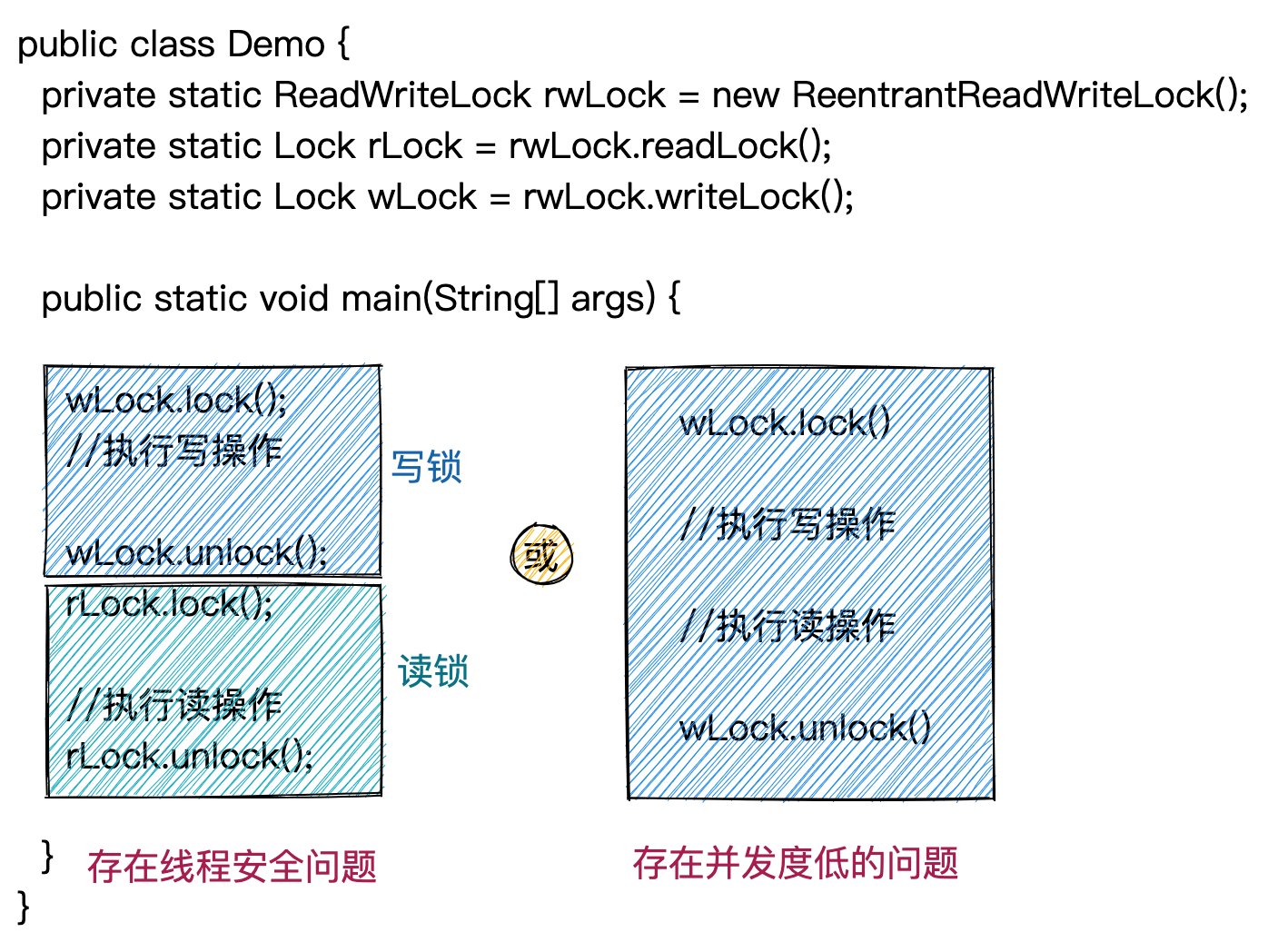
当临界区中既有写操作又有读操作时,如果我们用写锁来给整个临界区加锁,那么代码的并行度就不高。如果我们先加写锁,写操作完成之后释放写锁,再加读锁执行读操作。如下图所示,这样做就有可能存在多线程安全问题,我们无法保证写操作和读操作的组合起来的原子性。写操作完成之后,切换到其他线程执行,更新了共享变量的值,读操作变无法读取之前写操作之后的值了。而使用上图中的锁降级,我们便既可以保证临界区线程安全,又能提到代码的并行度。
三、读写锁的实现原理
前面讲到读写锁跟上一节讲到的普通锁(JUC Lock)一样,既支持公平锁,也支持非公平锁。ReentrantReadWriteLock的代码结构如下所示。
public class ReentrantReadWriteLock implements ReadWriteLock {
private final ReadLock readerLock;
private final WriteLock writerLock;
final Sync sync;
public ReentrantReadWriteLock() { this(false);}
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
public WriteLock writeLock() { return writerLock; }
public ReadLock readLock() { return readerLock; }
// AQS的子类NonfairSync和FairSync的公共父类:Sync
abstract static class Sync extends AbstractQueuedSynchronizer {
abstract boolean readerShouldBlock(); //用来区分公平锁和非公平锁
abstract boolean writerShouldBlock(); //用来区分公平锁和非公平锁
//以下为AQS模板方法的抽象方法的代码实现
protected final boolean tryAcquire(int acquires) { ... }
protected final boolean tryRelease(int releases) { ... }
protected final int tryAcquireShared(int unused) { ... }
protected final boolean tryReleaseShared(int unused) { ... }
//..省略其他方法...
final boolean tryWriteLock() { ... }
final boolean tryReadLock() { ... }
}
static final class NonfairSync extends Sync {
final boolean writerShouldBlock() { return false; }
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
}
static final class FairSync extends Sync {
final boolean writerShouldBlock() { return hasQueuedPredecessors(); }
final boolean readerShouldBlock() { return hasQueuedPredecessors(); }
}
}
上述代码结构跟ReentrantLock的代码结构类似,NonfairSync和FairSync具体化抽象的模板类AQS,并且实现了其中的抽象方法。NonfairSync是非公平锁,FairSync是公平锁。ReentrantReadWriteLock使用NonfairSync或FairSync来编程实现读锁(ReadLock)和写锁(WriteLock)。ReadLock和WriteLock均实现了Lock接口,使用相同的AQS,实现了Lock接口中的所有加锁和解锁函数。ReadLock和WriteLock的代码实现如下所示。
//写锁中的加锁和解锁方法使用AQS的独占模式下的几个模板方法来实现
public static class WriteLock implements Lock, java.io.Serializable {
private final Sync sync;
protected WriteLock(ReentrantReadWriteLock lock) { sync = lock.sync; }
public void lock() { sync.acquire(1); }
public void unlock() { sync.release(1); }
public boolean tryLock( ) { return sync.tryWriteLock(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, unit.toNanos(timeout));
}
}
//读锁中的加锁和解锁方法使用AQS的共享模式下的几个模板方法来实现
public static class ReadLock implements Lock {
private final Sync sync;
protected ReadLock(ReentrantReadWriteLock lock) { sync = lock.sync; }
public void lock() { sync.acquireShared(1); }
public void unlock() { sync.releaseShared(1); }
public boolean tryLock() { return sync.tryReadLock(); }
public void lockInterruptibly() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireSharedNanos(1, unit.toNanos(timeout));
}
}
从上述代码,我们可以发现,读锁和写锁共用一个AQS。在上一节中,我们讲到,对于JUC Lock,我们使用AQS中state变量来表示加锁情况,0表示没有加锁,1表示已经加锁,大于1的值表示重入次数。对于读写锁来说,我们不仅需要知道有没有加锁、重入次数,还需要知道加的是读锁还是写锁,但是AQS中只有一个表示加锁情况的int类型的state变量。为了让state变量表达更多的信息,我们用state变量中的低16位表示写锁的使用情况,高16位表示读锁的使用情况。
对于低16位所表示的数,值为0表示没有加写锁,值为1表示已加写锁,值大于1表示写锁的重入次数。对于高16位所表示的数,值为0表示没有加读锁,值为1表示已加读锁,不过,值大于1并不表示读锁的重入次数,而是表示读锁总共被获取了多少次(每个线程对读锁重入的次数相加)。那么,读锁的重入次数在哪里记录呢?毕竟重入次数是有用信息,只有重入次数大于0时,才可以继续重入。
当多个线程同时持有读锁时,每个线程都可以对读锁重复加锁,也就就是说,重入次数是跟每个线程相关的数据,我们可以使用ThreadLocal变量来存储,对于ThreadLocal,我们在后面的章节中信息讲解,在这里,你就简单将它看做线程的一个属性或者局部变量即可。
接下来,我们详细看下,读锁和写锁的实现原理。
1)写锁的实现原理
WriteLock写锁是排它,因此,它的实现原理跟上一节讲到的ReentrantLock的实现原理类似。WriteLock实现了Lock接口,因此,它也支持各种不同的加锁方式,比如可中断加锁、非阻塞加锁、可超时加锁。接下来,我们重点讲解WriteLock中的lock()函数和unlock()函数的实现原理。对于WriteLock中的tryLock()、带超时时间的tryLock()、lockInterruptibly()这三个加锁函数,你可以参考ReentrantLock中这三个函数的实现原理,以及结合源码,自行研究。
**我们先来看WriteLock中的lock()函数。**实现比较简单,直接调用了AQS中的acquire()模板方法。
public void lock() {
sync.acquire(1);
}
AQS中的acquire()模板方法如下所示,在上一节中已经讲解,使用tryAcquire()竞争锁,如果竞争锁成功,则直接返回,如果竞争锁失败,则调用addWaiter()将线程放入等待队列的尾部,然后调用acquireQueued()阻塞线程等待被唤醒。
public final void acquire(int arg) {
// tryAcquire() -> addWaiter() -> acquireQeuued()
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
上一节,我们已经详细讲解了addWaiter()函数和acquiredQueued()函数,这里就不再赘述。我们重点看下tryAcquire()竞争锁的逻辑,它是AQS中的抽象方法,在NonfairSync和FairSync的公共父类Sync类中实现。代码如下所示。
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState(); //c为state的值
int w = exclusiveCount(c); //低16位的值,也就是写锁的加锁情况
// 1、已经加读锁或写锁(state!=0)
if (c != 0) {
//已加读锁(w==0)或者当前加写锁的线程不是自己
if (w == 0 || current != getExclusiveOwnerThread())
return false; //去排队
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
setState(c + acquires); //更新写锁的重入次数
return true; //获取到了锁
}
// 2、没有加锁(state==0)
if (writerShouldBlock()) return false; //去排队
if (!compareAndSetState(c, c + acquires)) return false; //去排队
setExclusiveOwnerThread(current);
return true; //获取到了锁
}
我们重点看下writerShouldBlock()这个函数,这个函数控制着锁是否为公平锁。在state=0,也就是没有加读锁和写锁的情况下,如果writerShouldBlock()函数返回值为true,那么,线程不尝试竞争锁,而是直接去排队。如果writerShouldBlock()函数返回值为false,那么,线程先尝试竞争锁,不行再去排队。对于非公平锁,writerShouldBlock()总是返回false。对于公平锁,如果等待队列中有线程,那么writerShouldBlock()返回true。如果等待队列中没有线程,那么writerShouldBlock()返回false。
static final class NonfairSync extends Sync {
final boolean writerShouldBlock() { return false; }
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
}
static final class FairSync extends Sync {
final boolean writerShouldBlock() { return hasQueuedPredecessors(); }
final boolean readerShouldBlock() { return hasQueuedPredecessors(); }
}
在注释中,我对代码逻辑做了详细的介绍。这里就不再赘述。我将tryAcquire()的执行逻辑梳理并绘制成了一张流程图,如下所示,你可以对比着流程和注释来理解tryAcquire()的代码逻辑。
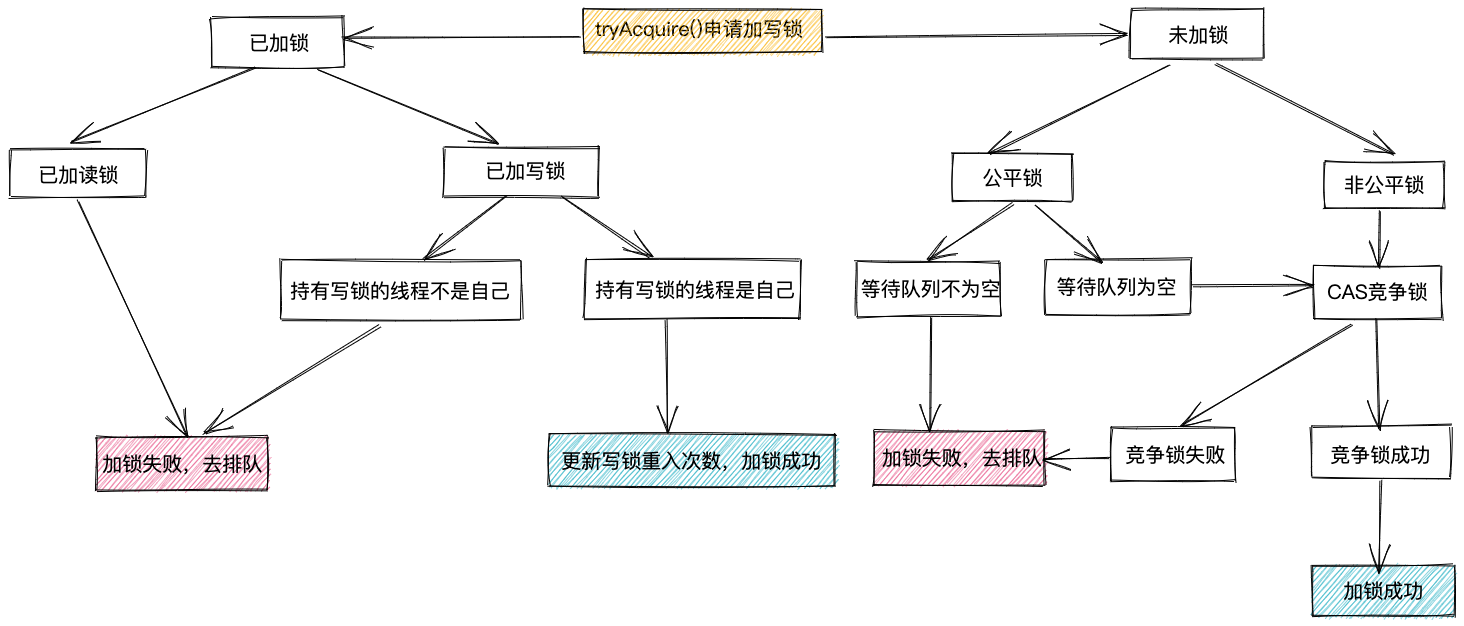
**我们再来看WriteLock的unlock()函数。**代码实现也比较简单,直接调用了AQS的release()模板方法。
public void unlock() {
sync.release(1);
}
AQS中的release()模板方法如下所示,在上一节中已经讲解,使用tryRelease()释放锁,然后唤醒等待队列中位于队首的线程。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
我们重点看下在写锁中tryRelease()抽象方法的代码实现,代码如下所示。tryRelease()的代码实现比较简单,在代码中,我详细作了注释,你可以参看注释了解其代码逻辑。这里就不再赘述了。
protected final boolean tryRelease(int releases) {
// tryRelease()是AQS工作在独占模式下的函数,只能用于排它锁,也就是写锁
if (!isHeldExclusively()) throw new IllegalMonitorStateException();
// 更新state值,写锁的重入次数-releases,对于锁来说,releases总是等于1
int nextc = getState() - releases;
// 只有更新之后的state值为0时,才可以将写锁释放
boolean free = exclusiveCount(nextc) == 0;
if (free) setExclusiveOwnerThread(null);
setState(nextc);
return free;
}
2)读锁的实现原理
刚刚我们讲了读写锁中的写锁的实现原理,现在,我们再来看下读锁的实现原理。写锁是排它锁,实现原理比较简单,而读锁是共享锁,实现原理相对来说更加复杂。跟WriteLock相同,ReadLock也实现了Lock接口。同样,支持各种不同的加锁方式(lock()、tryLock()、带超时时间的tryLock()、lockInterruptibly())。接下来,我们还是重点讲解lock()和unlock()这两个函数。对于其他加锁方式,你可以参看上一节的内容和源码,自行研究。
**我们先来看ReadLock中的lock()函数。**前面讲到,WriteLock中的lock()函数调用了AQS中的acquire()模板方法,这里ReadLock的lock()函数调用的是AQS中的acquireShared()模板方法。acquire()模板方法用于独占模式,acquireShared()模板方法用于共享模式。
public void lock() {
sync.acquireShared(1);
}
我们再来看下AQS中acquireShared()的代码实现,如下所示。对比acquire()的代码实现,acquireShared()的代码实现同样也比较简单,调用tryAquireShared()去竞争锁,如果竞争成功,则直接返回,如果竞争失败,则调用doAcquireShared()去排队等待唤醒。
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0) // 竞争读锁
doAcquireShared(arg); // 竞争失败去排队
}
tryAcquiredShared()为AQS的抽象方法,其在AQS的子类Sync中实现,具体代码如下所示。tryAcquireShared()为了提高性能做了很多代码层面的优化,导致代码量很大。为了聚焦在基本实现原理上,在不改变基本实现原理的情况下,我对tryAcquireShared()中的代码做了简化。如果你想了解完成的代码,请自行查看源码。
// 返回-1表示竞争锁失败,返回1表示竞争锁成功
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
// 如果state没加锁或者是加了读锁,那么线程会通过CAS操作改变state值来竞争锁;
// 如果其他线程也在竞争读锁,并且竞争成功,那么此线程就会竞争失败;
// 于是,此线程就要自旋(for循环)再次尝试去竞争读锁。
for (;;) {
int c = getState();
if (exclusiveCount(c) != 0) { // 已加写锁
// 如果加写锁的线程不是此线程,那么读锁也加不成,直接返回-1
// 否则,读写锁支持锁降级,加了写锁的线程可以再加读锁
if (getExclusiveOwnerThread() != current)
return -1;
}
//理论上讲,如果没有加写锁,不管有没有加读锁,都可以去竞争读锁了,毕竟读锁是共享锁。
//但是,存在两个特殊情况:
//1、对于公平锁来说,如果等待队列不为空,并且当前线程没有持有读锁(重入加锁),
// 那么,线程就要去排队。
//2、对于非公平锁来说,如果等待队列中队首线程(接下来要被唤醒的)是写线程,
// 那么,线程就要去排队。这样做是为了避免请求写锁的线程迟迟获取不到写锁。
if (sharedCount(c) != 0) { // 已加读锁
if (readerShouldBlock()) { //上述1、2两种情况对应此函数的返回值为true
if (readHolds.get().count == 0) // 此线程没有持有读锁,不能重入
return -1;
}
}
// 以下是对上述代码中readHolds的解释:
// readHolds是ThreadLocal变量,保存跟这个线程的读锁重入次数。
// 如果重入次数为0,表示没有加读锁,返回-1去排队。
// 如果重入次数大于等于0,表示已加读锁,可以继续重入,不用排队。
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
//CAS竞争读锁,此时有可能还有其他线程在竞争读锁或写锁
if (compareAndSetState(c, c + SHARED_UNIT)) { //SHARED_UNIT=1<<16
// 竞争读锁成功
readHolds.get().count++; //更新线程重入次数
return 1; //成功获取读锁
}
}
}
从上述代码,我们可以发现,相对于tryAcquire()抽象方法,tryAcquireShared()要复杂很多。在注释中,我对代码逻辑做了详细的介绍。这里就不再赘述。我将tryAcquireShared()的执行逻辑梳理并绘制成了一张流程图,如下所示,你可以对比着流程和注释来理解tryAcquireShared()的代码逻辑。
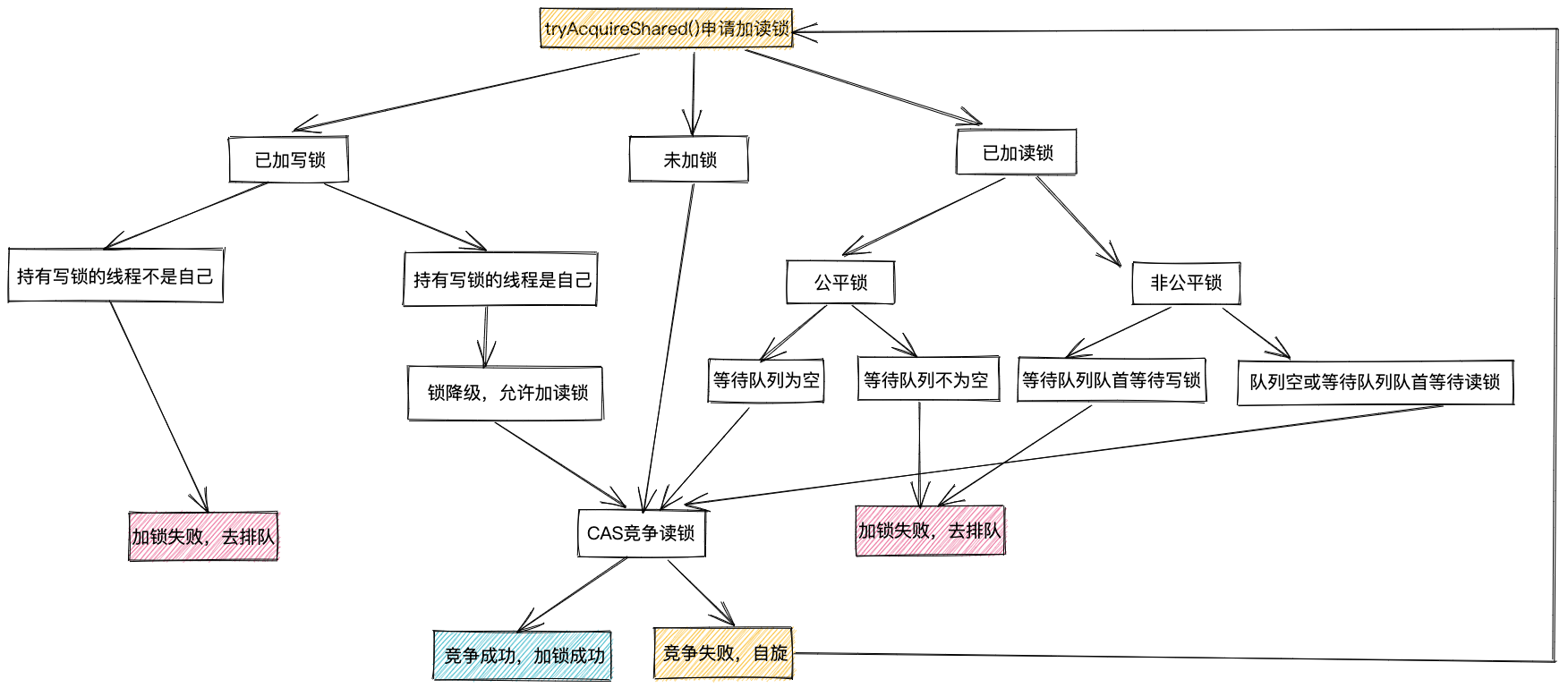
接下来,我们再来看下doAcquireShared()函数,此函数负责排队和等待唤醒,代码如下所示。doAcquireShared()函数跟上一节讲到的acquireQueued()函数非常类似。区别主要有两点,如下注释所示。区别一是等待读锁的线程标记为SHARED,区别二是线程获取到读锁之后,如果下一个节点对应的线程也在等待读锁,那么也会被唤醒。下一个节点对应的线程获取到读锁之后,又会去唤醒下下个节点对应的线程(如果下下个节点对应的线程也在等待读锁的话)。唤醒操作一直传播下去,直到遇到等待写锁的线程为止。
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);//区别一:标记此线程等待的是共享锁(读锁)
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {
int r = tryAcquireShared(arg);
if (r >= 0) {
//区别二:如果下一个节点对应的线程也在等待读锁,那么顺道唤醒它
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted) selfInterrupt();
failed = false;
return;
}
}
if (parkAndCheckInterrupt()) interrupted = true;
}
} finally {
if (failed) cancelAcquire(node);
}
}
**我们先来看ReadLock中的unlock()函数。**代码实现也比较简单,直接调用了AQS的releaseShared()模板方法。
public void unlock() {
sync.releaseShared(1);
}
AQS中的releaseShared()模板方法如下所示,调用tryReleaseShared()释放读锁,只有当所有的读锁都释放之后,state变为0,才会调用doReleaseShared()唤醒等待队列中位于队首的线程。
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
doReleaseShared()的代码实现比较简单,我们重点看下tryReleaseShared()。tryReleaseShared()是AQS中的抽象方法,在Sync中实现,代码如下所示。
//当所有的读锁都释放之后(state变成0)才会返回true
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
readHolds.get().count--; //更新本线程对读锁的重入次数
for (;;) { //因为有可能多个线程同时释放读锁,同时CAS更新state,因此要自旋+CAS
int c = getState();
// c-SHARED_UNIT:相当于将读锁的加锁次数-1
int nextc = c - SHARED_UNIT; //SHARED_UNIT=1<<16
if (compareAndSetState(c, nextc))
return nextc == 0; //state变为0才会返回true,才会去唤醒等待队列中的线程
}
}
四、读写锁的升级版
StampedLock是对ReadWriteLock的进一步优化,在读锁和写锁的基础之上,又提供了乐观读锁。实际上,乐观读锁并没有加任何锁。在读多写少的应用场景中,大部分读操作都不会被写操作干扰,因此,我们甚至可以将读锁也省略掉。只有验证读操作真正有被写操作干扰的情况下,线程再加读锁重复执行读操作。我们举一个例子解释一下。代码如下所示。
public class Demo {
private StampedLock slock = new StampedLock();
private List<String> list = new LinkedList<>();
public void add(int idx, String elem) {
long stamp = slock.writeLock(); //加写锁
try {
list.add(idx, elem);
} finally {
slock.unlockWrite(stamp); //释放写锁
}
}
public String get(int idx) {
long stamp = slock.tryOptimisticRead(); //加乐观读锁
String res = list.get(idx);
if (slock.validate(stamp)) { //没写操作干扰
return res;
}
// 有写操作干扰,重新使用读锁,重新执行读操作
stamp = slock.readLock(); //加读锁
try {
return list.get(idx);
} finally {
slock.unlockRead(stamp); //释放读锁
}
}
}
在上述代码中,tryOptimisticRead()获取的是乐观读锁,返回一个时间戳stamp。因为乐观读锁并非真正加锁,所以,乐观读锁并不需要解锁。在执行完读操作之后,我们只需要验证stamp是否有被更改,如果有被更改,说明执行读操作期间,writeLock()函数有被执行,也就说明有对共享资源的写操作发生(也就是执行了add()函数),此时,之前得到的结果需要作废,使用读锁来重新获取数据。
思考题
在本节的示例代码中,我们把lock()、tryLock()、lockInterruptibly()函数的调用,都放置于try-finally代码块之外,这是为什么?是否可以移到try-finally代码块之内呢?
本节中,我们讲到,ReentrantLock中的lock()函数使用AQS中的acquire()模板方法来实现,unlock()函数使用AQS中的release()模板方法来实现,lockInterruptibly()函数使用acquireInterruptibly()模板方法来实现,带超时时间的tryLock()函数使用AQS中的tryAcquireNanos()模板方法来实现,那么,ReentrantLock中的tryLock()函数是如何实现的呢?
如果一个线程在获取读锁之后,在读锁释放前,再次请求写锁,将会发生什么事情?