Synchronized
Synchronized
提示
线程释放锁之后,如何通知其他线程获取锁?
上一节提到,解决多线程执行非原子操作,导致的线程不安全问题,其中最常用的解决方案便是加锁。Java语言提供了两种类型的锁,一种是synchronized关键字,一种是Lock工具类。在JDK1.5及其以前版本中,synchronized的实现比较简陋,性能没有后起之秀Lock高,但是,在JDK1.6及其之后的版本中,Java对synchronized做了大量优化,其基本实现原理跟Lock的基本实现原理趋于一致,因此,在性能方面,两者也就相差无几了。
接下来我们先重点讲解synchronized。其中,本节课讲解synchronized的基本用法,以及重量级锁的实现原理,下一节讲解Java对synchronized的各种优化,包括偏向锁、轻量级锁、自旋锁、锁粗化、锁消除等。
在开始今天的内容之前,我仍然有几个问题留给你思考:某个Java线程使用synchronized之后,如果没有获取锁,Java是如何阻塞当前代码的执行的?如何停止对应的内核线程执行?当另一个线程释放锁之后,如何通知等待锁的线程获取锁?
带着这些问题,我们开始今天的学习。
基本用法和原理
一、两种作用范围
synchronized关键字既可以作用于方法,也可以作用方法内的局部代码块。
1)synchronized作用于方法
在上一节中,我们展示了一个非线程安全的Counter类。为了让Counter类变为线程安全的,我们可以在add()函数和substract()函数声明中,添加synchronized关键字,代码如下所示。因为add()函数和substract()函数使用同一个锁,所以,在多线程环境下,不仅add()函数本身以及substract()函数本身不可并发执行,add()函数与substract()函数之间也不可并发执行。
public class Counter {
private int count = 0;
public synchronized void add(int value) {
count += value;
}
public synchronized void substract(int value) {
count -= value;
}
}
2)synchronized作用于局部代码块
如果上述Counter类的add()函数和substract()函数内部包含大量其他逻辑,只有count+=value以及count-=value这两个代码块才是真正的临界区,那么,为了尽可能的提高代码执行的并发度,减小加锁范围,我们可以使用synchronized关键字,只对add()函数和substract()函数中的局部代码块加锁。如下代码所示。
public class Counter {
private int count = 0;
public void add(int value) {
...
synchronized (this) {
count += value;
}
...
}
public void substract(int value) {
...
synchronized (this) {
count -= value;
}
...
}
}
现在,我们再修改一下Counter类,如下所示。在修改之后的代码中,尽管add()函数和substract()函数仍然都是线程不安全的,但是,add()函数和substract()函数是可以并发执行的,因为它们访问的共享资源并不相同。针对修改后的Counter类,我们应该如何使用synchronized加锁,既保证类为线程安全的,又保证两个函数可以并发执行呢?
public class Counter {
private int increasedSum = 0;
private int decreasedSum = 0;
public void add(int value) {
increasedSum += value;
}
public void substract(int value) {
decreasedSum -= value;
}
}
如果我们使用前面讲到的两种方法,在方法上或者局部代码块上使用synchronized加锁,那么,add()函数和substract()函数就无法并发执行了,这样做降低了代码的并行度,进而降低了代码在多线程环境下的执行效率。究其原因,主要在于add()函数和substract()函数使用的是同一把锁。为了解决这个问题,我们需要给两个函数加两把不同的锁。
synchronized关键字底层使用的锁叫做Monitor锁。但是,我们无法直接创建和使用Monitor锁。Monitor锁是寄生存在的,每个对象都会拥有一个Monitor锁。如果我们想要使用一个新的Monitor锁,我们只需要使用一个新的对象,并在synchronized关键字后,附带声明要使用哪个对象的Monitor锁即可。实际上,我们对方法添加synchronized关键字,就相当于隐式地使用了当前对象(this对象)的Monitor锁。
为了让add()函数和substract()函数之间能并发执行,我们可以采用如下方式,对add()函数和substract()函数加锁。add()函数使用obj1对象上的Monitor锁,substract()函数使用obj2对象上的锁,两者互不影响。
public class Counter {
private int increasedSum = 0;
private int decreasedSum = 0;
private Object obj1 = new Object();
private Object obj2 = new Object();
public void add(int value) {
synchronized (obj1) {
increasedSum += value;
}
}
public void substract(int value) {
synchronized (obj2) {
decreasedSum -= value;
}
}
}
二、对象锁和类锁
实际上,刚刚我们讲到的锁,都是对象锁。现在,我们再来讲一讲类锁。实际上,在《设计模式之美》一书中,当讲到单例模式时,曾经用到过一个日志框架的例子,很好的诠释了什么是类锁,并且非常贴合实战,强烈建议你去看一下。不过,那个例子有点复杂,今天,我们换一个简单点的例子,来讲解类锁。
我们先来看一段代码,如下所示,Wallet类表示用户钱包,里面有一个transferTo()函数,可以实现将当前钱包的钱,转账给另一个钱包。下面的transferTo()函数是否是线程安全的呢?
public class Wallet {
private int balance;
public void transferTo(Wallet targetWallet, int amount) {
if (this.balance >= amount) { //先检查后修改
this.balance -= amount; //先读再改后写
targetWallet.balance += amount; //先读再改后写
}
}
}
我们使用上节中总结的方法,来分析transferTo()函数是否是线程安全的。
transferTo()函数访问了共享资源(balance),并且包含复合操作(先检查再执行以及先读再改后写),因此,transferTo()函数为临界区。除此之外,从业务的角度来看,我们也无法避免两个线程同时执行transferTo()函数来转账,也就是说,transferTo()函数既存在临界区,又存在竞态。因此,transferTo()函数极有可能线程不安全。接下来,我们再通过两个线程交叉执行transferTo()函数,找到线程不安全的具体用例,如下所示,从而证明transferTo()函数真的线程不安全。
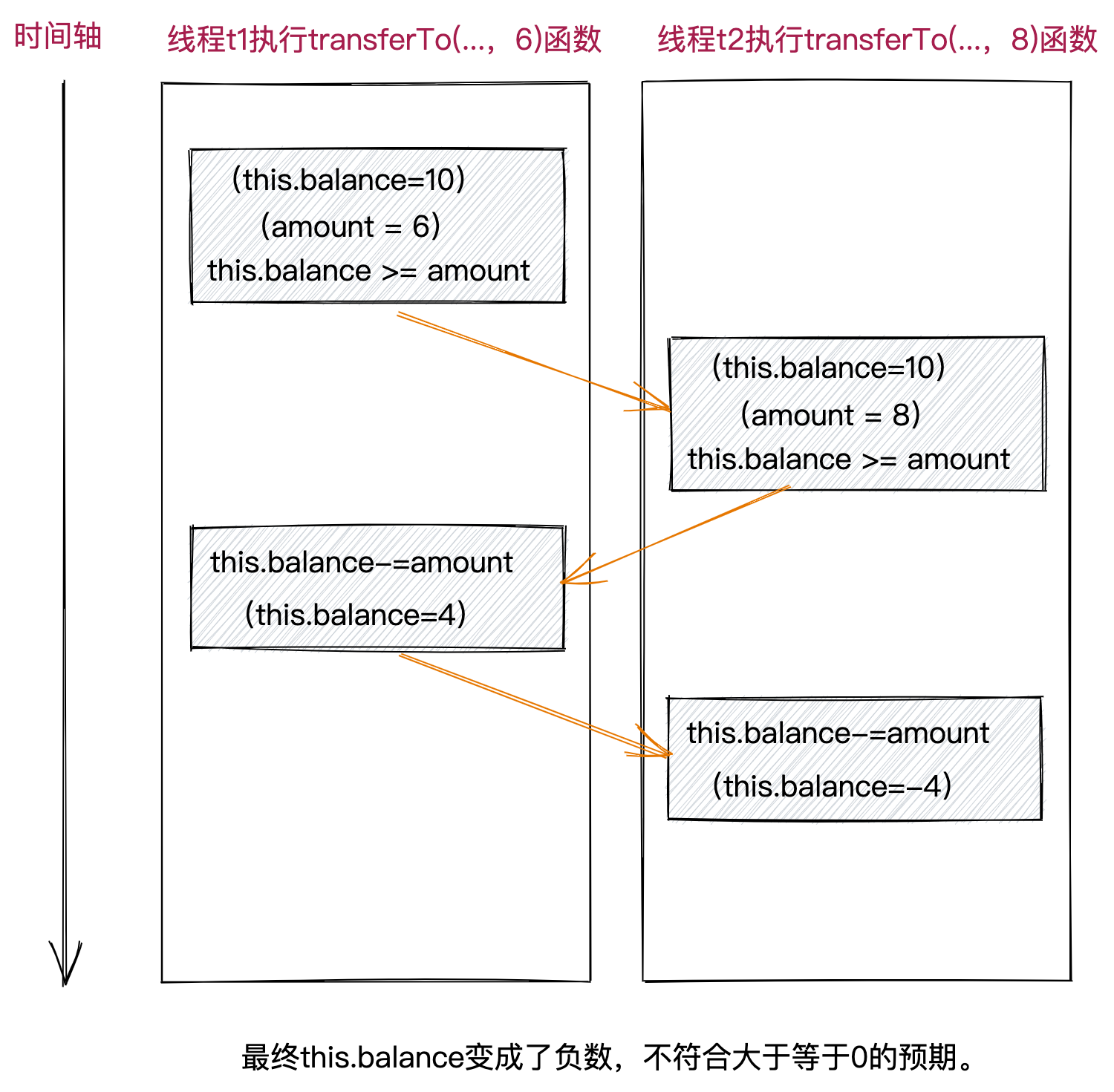
为了让transferTo()函数线程安全,你可能会想到使用synchronized修饰transferTo()函数,但是,这样真的能保证transferTo()函数线程安全吗?
答案是否定的,因为这段代码比较特殊,看似transferTo()函数只访问了一个共享资源(balance),实际上,还访问了其他共享资源(targetWallet的balance)。
假设我们有两个Wallet类对象:wallet1和wallet2。调用wallet1上的transferTo()函数,使用的是wallet1这个对象上的Monitor锁,调用wallet2上的transferTo()函数,使用的是wallet2这个对象上的Monitor锁。因此,使用synchronized修饰transferTo()函数,只能限制两个线程不能并发执行同一个Wallet对象上的transferTo()函数,但不能限制两个线程并发执行不同Wallet对象上的transferTo()函数。一个线程执行wallet1上transferTo()函数像wallet2转账,另一个线程并发执行wallet2上的transferTo()函数向wallet1转账,如下图所示,红色标记部分为复合操作(先读再改后写),并发执行会存在线程安全问题。
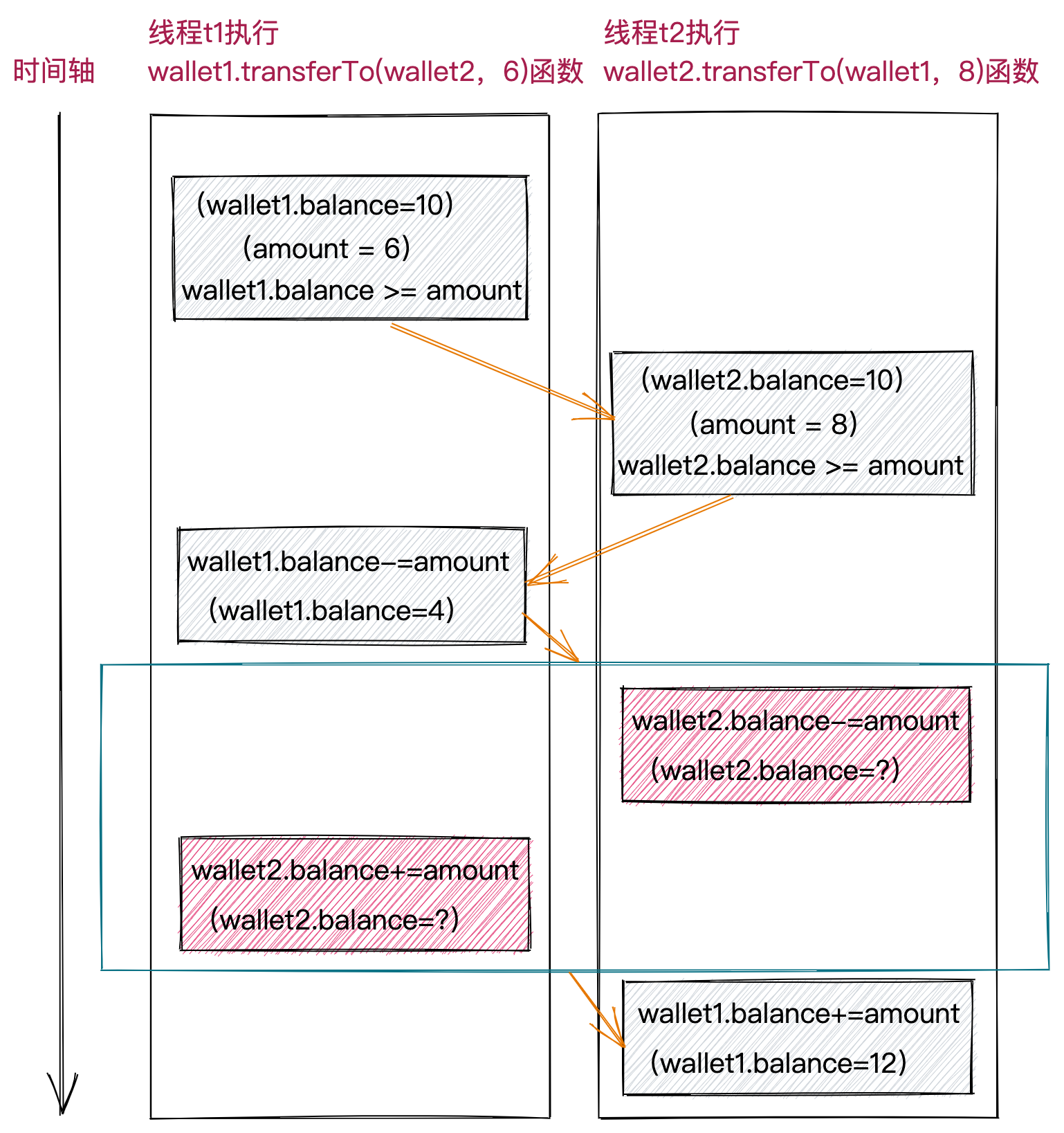
也就说是,不仅一个对象上的transferTo()函数,不能并发执行,同一个类上的所有对象上的transferTo()函数,都不能并发执行。为了实现这样的限制,我们就需要使用类锁来替代对象锁,对transferTo()函数进行加锁。类锁的语法非常简单,如下代码所示,synchronized关键词后跟随某个类的Class类对象即可。
public class Wallet {
private int balance;
public void transferTo(Wallet targetWallet, int amount) {
synchronized (Wallet.class) {
if (this.balance >= amount) {
this.balance -= amount;
targetWallet.balance += amount;
}
}
}
}
前面讲到对象锁时,我们提到,synchronized底层使用的是对象上的Monitor锁。那么,对于类锁来说,synchronzied使用的也是某个对象上的Monitor锁。只不过这个对象比较特殊,是类的Class类对象。Class类是所有类的抽象。每个类在JVM中都有一个Class类对象来表示这个类。这有点不好理解,等讲到JVM模块时,我们再详细解释。
除了显示指定使用哪个类的类锁(类的Class类对象的Monitor锁)之外,如果我们对静态方法添加synchronized关键词,那么,对应的静态方法会隐式地使用当前类的类锁。如下代码所示,add()函数使用Counter类的类锁。
public class Counter {
private static int count = 0;
public synchronized static void add(int value) {
count += value;
}
}
三、对应的字节码
为了了解synchronized的底层实现原理,我们先从字节码层面找找答案,看看synchronized对应的字节码长什么样子。我们还是针对synchronized的两种不同的应用方式(作用于方法和局部代码块)来分析。
我们先来看synchronized作用于方法。示例代码如下所示。
public class Counter {
private int count = 0;
public synchronized void add(int value) {
count += value;
}
}
add()函数对应的字节码如下所示。实际上,编译器只不过是在函数的flags中添加了ACC_SYNCHRONIZED标记而已,其他部分跟没有添加synchronized的add()函数的字节码相同。
public synchronized void add(int);
descriptor: (I)V
flags: (0x0021) ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=3, locals=2, args_size=2
0: aload_0
1: dup
2: getfield #2 // Field count:I
5: iload_1
6: iadd
7: putfield #2 // Field count:I
10: return
LineNumberTable:
line 5: 0
line 6: 10
我们再来看synchronized作用于局部代码块,示例代码如下所示。
public class Counter {
private int count = 0;
private Object obj = new Object();
public void add(int value) {
synchronized (obj) {
count += value;
}
}
}
add()函数对应的字节码如下所示。字节码通过monitorenter和monitorexit来标记synchronized的作用范围。除此之外,对于以下字节码,我们有点需要解释。其一,以下字节码中有两个monitorexit,添加第二个monitorexit的目的是为了在代码抛出异常时仍然能解锁。其二,前面讲到,synchronized可以选择指定使用哪个对象的Monitor锁。具体使用哪个对象的Monitor锁,在字节码中,通过monitorenter前面的几行字节码来指定。
public void add(int);
descriptor: (I)V
flags: (0x0001) ACC_PUBLIC
Code:
stack=3, locals=4, args_size=2
0: aload_0
1: getfield #4 // Field obj:Ljava/lang/Object;
4: dup
5: astore_2
6: monitorenter
7: aload_0
8: dup
9: getfield #2 // Field count:I
12: iload_1
13: iadd
14: putfield #2 // Field count:I
17: aload_2
18: monitorexit
19: goto 27
22: astore_3
23: aload_2
24: monitorexit
25: aload_3
26: athrow
27: return
Exception table:
from to target type
7 19 22 any
22 25 22 any
从上述示例对应的字节码,我们可以发现,synchronized语句与字节码之间,只不过是做了一个简单的翻译而已。我们是无法通过synchronized对应的字节码,了解到其底层实现原理的。我们需要继续深挖。
四、底层实现原理
为了提高synchronized加锁、解锁的执行效率,在不同场景下,synchronized底层使用不同的锁来实现,比如偏向锁、轻量级锁、重量级锁等。本节,我们重点讲解重量级锁。对于偏向锁、轻量级锁等其他锁,我们留在下一节中讲解。
**实际上,synchronized使用的重量级锁,就是前面提到的对象上的Monitor锁,那么,Monitor锁具体长什么样子?**Monitor锁与对象之间又是如何关联的?
JVM有不同的实现版本,因此,Monitor锁也有不同的实现方式。在常用到Hotspot JVM实现中,Monitor锁对应的实现类为ObjectMonitor类。因为Hotspot JVM是用C++实现的,所以,ObjectMonitor也是用C++代码定义的。ObjectMonitor包含的代码很多,我们只罗列一些与其基本实现原理相关的成员变量,如下所示。
class ObjectMonitor {
void * volatile _object; //该Monitor锁所属的对象
void * volatile _owner; //获取到该Monitor锁的线程
ObjectWaiter * volatile _cxq; //没有获取到锁的线程暂时加入_cxq
ObjectWaiter * volatile _EntryList; //存储等待被唤醒的线程
ObjectWaiter * volatile _WaitSet; //存储调用了wait()的线程
}
现在,我们先重点看下_object,其他成员变量我们稍后讲解。
通过_object这个成员变量,我们可以得这个Monitor锁所属的对象。不过,我们更关心的是,如何通过对象查找到对应的Monitor锁。毕竟synchronized关键字是通过对象来使用Monitor锁的。在第9节中,我们讲过对象的存储结构。其中,对象头中的Mark Word字段,便可以用来记录对象所对应的Monitor锁。因此,Monitor锁和对象之间的关联,如下图所示。实际上,Mark Work是一个可变字段,在不同的场景下,记录的内容和作用均不同,关于这一点,我们留在下一节中深入探讨。
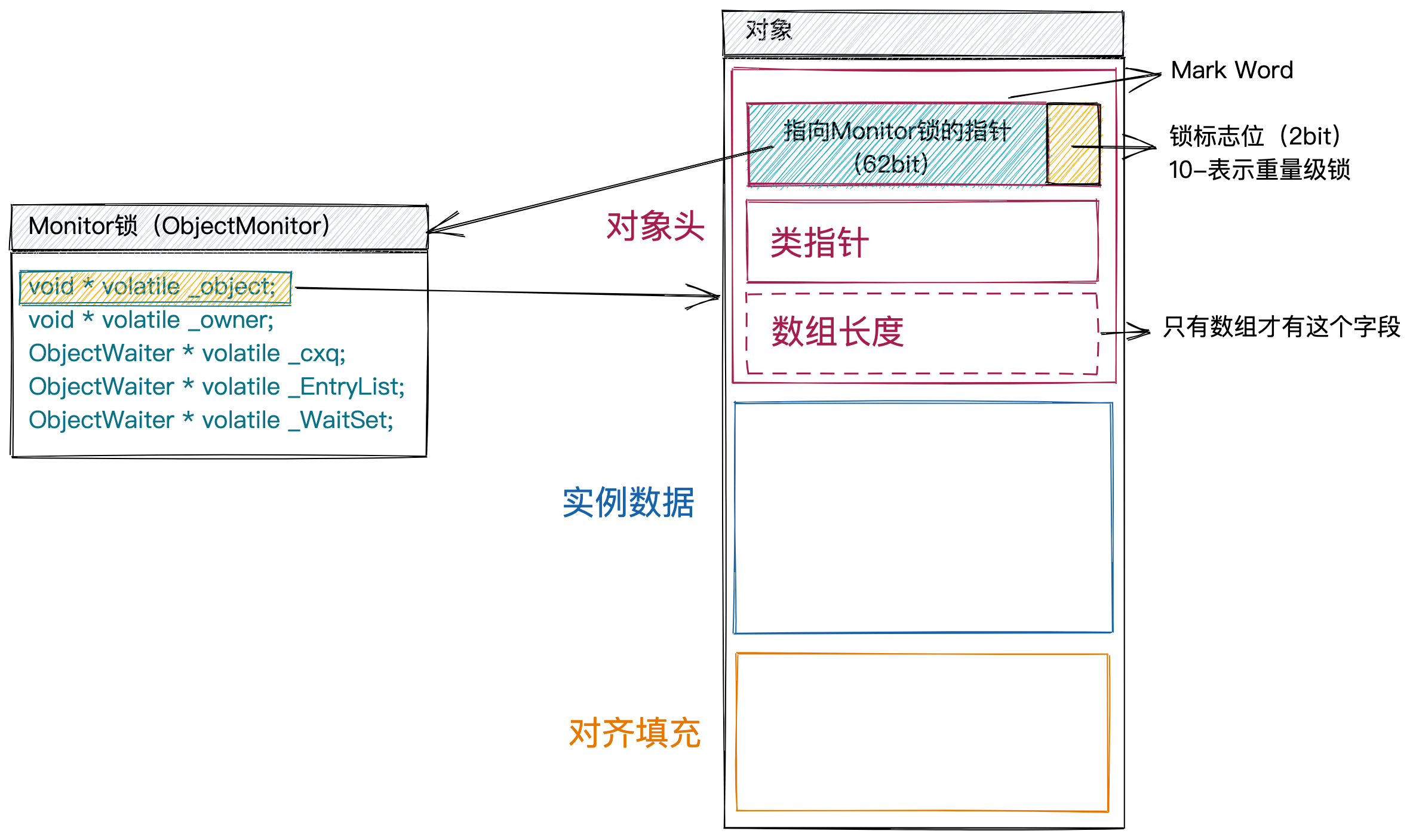
了解了Monitor锁大概的样子,以及如何跟对象关联之后,我们再来看下,Monitor锁是如何实现加锁、解锁的?
实际上,不管是后面要讲到的JUC(java.util.concurrent) Lock,还是现在正在讲的Java内置synchronized,它们作为多线程的互斥锁,所包含的基本功能是一致的,主要有以下几点:
1)多个线程竞争获取锁;
2)没有获取到锁的线程排队等待获取锁;
3)锁释放之后会通知排队等待锁的线程去竞争锁;
4)没有获取锁的线程会阻塞,并且对应的内核线程不再分配时间片;
5)阻塞线程获取到锁之后取消阻塞,并且对应的内核线程恢复分配时间片。
前面讲到,synchronized所使用的重量级锁就是Monitor锁,而Monitor锁在Hotspot JVM中对应的实现类为ObjectMonitor类。接下来,我们依次详细讲解一下,以上互斥锁的5个基本功能,在ObjectMonitor类中具体是如何实现的。
1)多个线程竞争获取锁
多个线程同时请求获取Monitor锁时,它们会通过CAS操作,来设置ObjectMonitor中的_owner字段。谁设置成功,谁就获取了这个Monitor锁。
这里我们再稍微解释一下CAS操作。CAS英文全称为Compare And Set,也就是我们之前提到的先检查再执行。参与竞争Monitor锁的线程,会先检查_owner是否是null,如果_owner是null,再将自己的Thread对象的地址赋值给_owner。
前面我们讲到,先检查再执行这类复合操作是非线程安全的。那么,这样就会导致多个线程有可能同时检查到_owner为null,然后都去改变_owner值。为了解决这个问题,JVM采用CPU提供的cmpxchg指令,通过给总线加锁的方式,来保证了以上CAS操作的线程安全性。实际上,这就相当于在硬件层面上给以上CAS操作加了锁。关于CAS操作,我们后面会有专门的章节详细讲解,这里稍微了解一下即可。
2)没有获取到锁的线程排队等待获取锁
多个线程竞争Monitor锁,成功获取锁的线程就去执行代码了,没有获取到锁的线程会放入ObjectMonitor的_cxq中等待锁。_cxq是一个单向链表。链表节点的定义如下ObjectWaiter类所示。ObjectWaiter类中包含线程的基本信息以及其他一些结构信息,比如_prev指针、_next指针。
class ObjectWaiter : public StackObj {
public:
enum TStates { TS_UNDEF, TS_READY, TS_RUN, TS_WAIT, TS_ENTER, TS_CXQ } ;
enum Sorted { PREPEND, APPEND, SORTED } ;
ObjectWaiter * volatile _next;
ObjectWaiter * volatile _prev;
Thread* _thread;
jlong _notifier_tid;
ParkEvent * _event;
volatile int _notified ;
volatile TStates TState ;
Sorted _Sorted ; // List placement disposition
bool _active ; // Contention monitoring is enabled
public:
ObjectWaiter(Thread* thread);
void wait_reenter_begin(ObjectMonitor *mon);
void wait_reenter_end(ObjectMonitor *mon);
};
你可能会说,单链表只需要_next指针,不需要_prev指针呀。实际上,ObjectWaiter不仅仅用来表示单链表的节点(用于_cxq),还用来表示双向链表的节点(用于_EntryList和_WaitSet)。这样设计是为了方便复用。当用来表示单链表的节点时,ObjectWaiter中的_prev指针设置为null。
3)锁释放之后会通知排队等待锁的线程去竞争锁
当持有锁的线程释放锁之后,它会从_EntryList中取出一个线程。被取出的线程会再次通过CAS操作去竞争Monitor锁。之所以不是直接让这个线程获取锁而再去竞争锁,是因为此时有可能有新来的线程(非_EntryList里的线程)也在竞争锁。
如果_EntryList中没有线程,我们就会先将_cxq中将所有线程一股脑的全部搬移到_EntryList中,然后再从_EntryList中取线程。那么,为什么我们不直接从_cxq取线程,而是要将_cxq中的线程倒腾到_EntryList中再取呢?
实际上,这样做的目的是减少多线程环境下链表存取操作的冲突。_cxq只负责存操作(往链表中添加节点),_EntryList负责取操作(从链表中删除节点),冲突减少,线程安全性处理就变得简单。多个线程有可能同时竞争锁失败,同时存入_cxq中,我们需要通过CAS操作来保证往链表中添加节点的线程安全性。而因为只有释放锁的线程才会从_EntryList中取线程,所以,_EntryList的删除节点操作是单线程操作,不存在线程安全问题。但是,当_EntryList为空时,将所有节点从_cxq搬移到_EntryList中的操作,需要对_cxq加锁。
_EntryList是一个双向链表,其节点定义跟_cxq中的节点定义相同,也是ObjectWaiter。那么,为什么_cxq是单链表,而_EntryList是双向链表呢?
这是因为,_cxq链表只支持添加节点和从头部删除节点(用于往_EntryList中搬移节点),这些操作在单链表中就可以高效执行。实际上,如果只需要实现一个FIFO队列的功能,那么_EntryList使用单链表实现就够了,但是,为了扩展性,synchronized预留支持各种等待线程的排队方式,因此,使用双向链表操作起来更加方便。
刚刚讲了_cxq、_EntryList,我们顺带讲下_WaitSet,_WaitSet并不是用于实现synchronized锁,而是用来实现wait()、notify()线程同步功能。实际上,_cxq、_EntryList、_WaitSet非常类似后面讲到的AQS,因此,对于_cxq、_EntryList等的操作细节,这里就不展开讲解了,我们留在AQS中详细讲解。
4)没有获取锁的线程会阻塞,并且对应的内核线程不再分配时间片
前面讲到,Java线程采用1:1线程模型来实现,一个Java线程会对应一个内核线程。应用程序提交给Java线程要执行的代码(Runnable接口的run()方法中的代码),会一股脑地交给对应的内核线程来执行。内核线程在执行的过程中,如果遇到synchronized关键字,会执行上述的1)2)3)。如果竞争到锁,则顺利往下执行。如果没有竞争到锁,则内核线程会调用park()函数将自己阻塞,这样CPU就不再分配时间片给它。
在Linux操作系统下,park()函数的大致实现思路如下代码所示。park()函数使用Linux操作系统下Posix函数库提供的pthread_cond_wait()函数来实现。pthread_cond_wait()函数就相当于我们后面要讲到的wait()函数,其在使用前需要先获取锁,因此,park()函数还用到了pthread_mutex_lock()函数。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
void park() {
...
pthread_mutex_lock(&mutex);
pthread_cond_wait(&cond, &mutex); //阻塞等待其他线程发送信号
pthread_mutex_unlock(&mutex);
...
}
5)阻塞线程获取到锁之后取消阻塞,并且对应的内核线程恢复分配时间片
实际上,准确的说法是从等待队列里唤醒的线程会取消阻塞。持有锁的线程在释放锁之后,从_EntryList中取出一个线程时,就会调用unpark()函数,取消对应内核线程的阻塞状态,这样才能让它去执行竞争锁的代码。在Linux操作系统下,unpark()函数的大致实现思路如下代码所示,通过pthread_cond_signal()函数给调用park()函数的线程发送信号。
void unpark() {
...
pthread_mutex_lock(&mutex);
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
...
}
Synchronized优化
提示
Java对synchronized进行了哪些性能优化?
上一节,我们讲解了synchronized底层用到的重量级锁的实现原理,重量级锁要维护等待队列(_cxq、_EntryList),并且还要调用操作系统的系统调用(例如pthread_mutext_lock、pthread_cond_wait、pthread_cond_signal、pthread_mutext_unlock)来阻塞和唤醒线程,涉及到用户态和内核态的切换,因此,加锁、解锁比较耗时。在JDK1.6版本中,Java对synchronized做了较大的优化,引入了偏向锁、轻量级锁、锁粗化、锁消除等优化手段,进一步提高了加锁、解锁的性能。本节,我们就来详细讲解一下这些优化手段。
一、偏向锁
引入偏向锁、轻量级锁,是基于这样一个推断:尽管我们需要对存在线程安全问题的代码加锁,但是,这只是出于防御的目的。实际上,出现同一时刻多个线程竞争锁的概率很小,甚至一个锁在大部分情况下都只被一个线程使用。
对于一个synchronized锁,如果它只被一个线程使用,那么,synchronzied锁底层使用偏向锁来实现。如果它被多个线程交叉使用(你用完我再用),不存在竞争使用的情况,那么,synchronized锁底层使用轻量级锁来实现。如果它存在被竞争使用的情况,那么,synchronized锁底层使用重量级锁来实现。
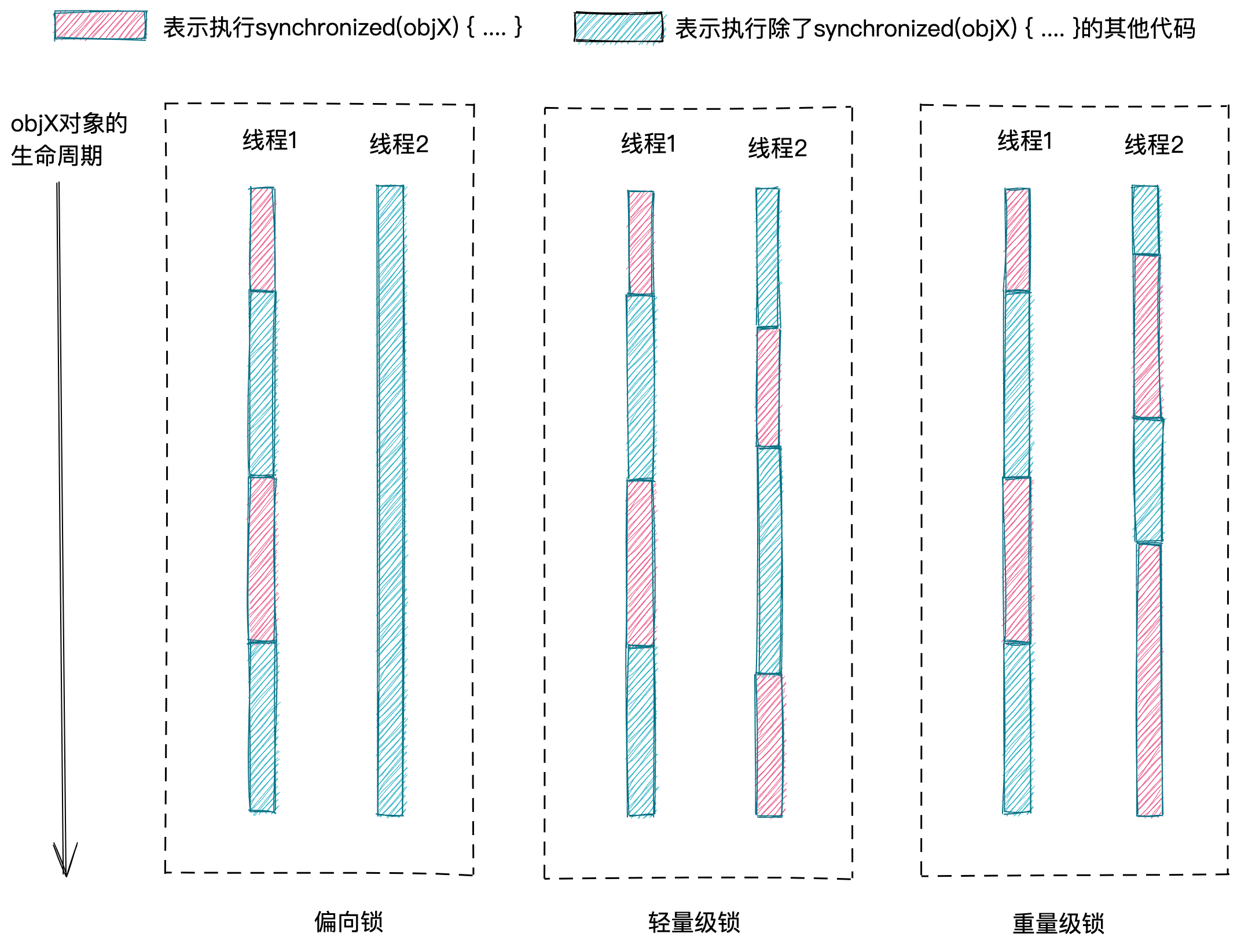
上一节,我们讲到,重量级锁需要用到对象头的Mark Word,实际上,偏向锁和轻量级锁也需要用到Mark Word。Mark Word是一个可变字段,在不同的情况下,存储不同的内容。这样做的目的是为了节省存储空间,减少对象对内存空间的占用。在64位JVM中,Mark Word长度为8字节,也就是64bits,其结构如下所示。根据锁标志位的不同,Mark Word存储的内容也不同,例如,锁标志位为10时,Mark Word存储的是指向Monitor锁的指针。(因为64位JVM是主流,32位JVM已经很少使用,所以,我们不再对32位JVM的Mark Word做介绍)
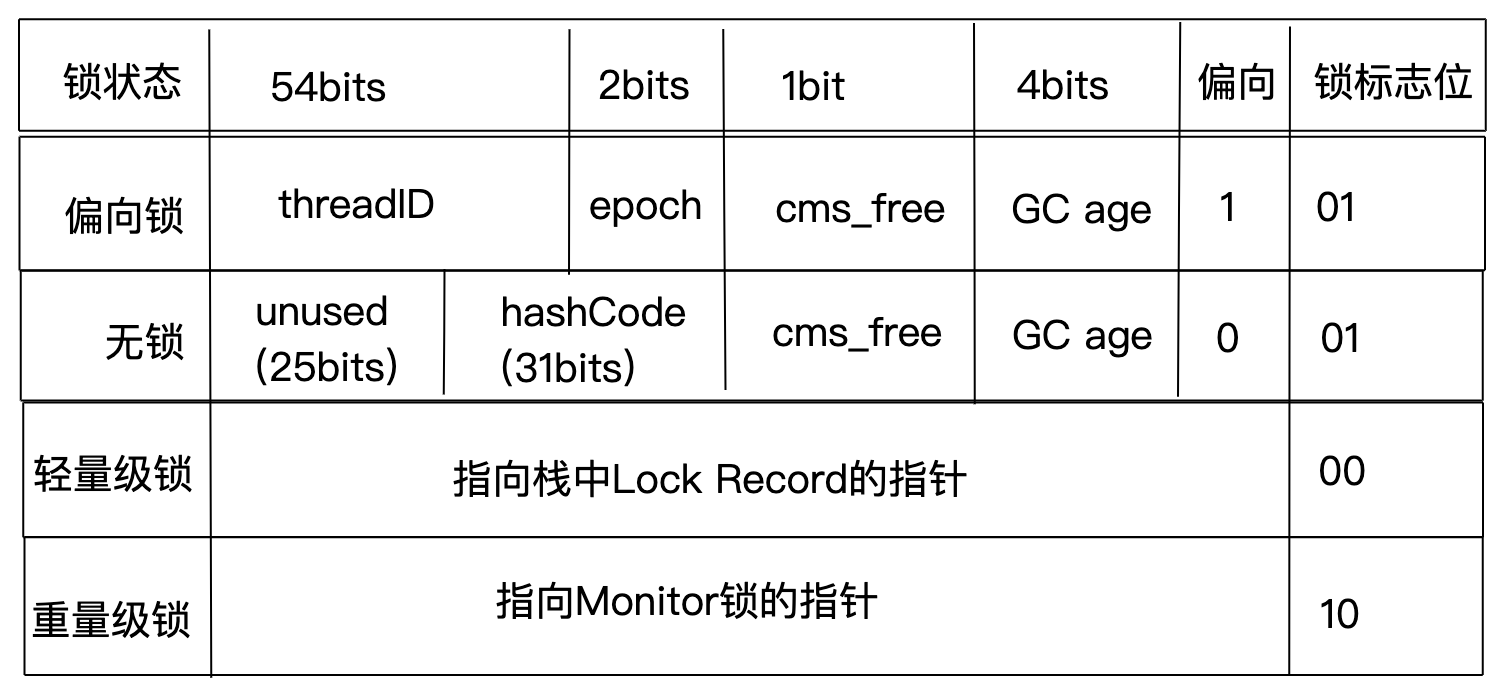
大概了解了Mark Word的结构之后,接下来,我们先来看下偏向锁的实现原理。
当一个对象刚被创建时,Mark Word处于无锁状态,并随即很快变为偏向锁状态,当然,如果我们设置JVM参数-XX:BiasedLockingStartupDelay=0,那么,Mark Word会在对象被创建之后,直接进入偏向锁状态。总之,新诞生的对象在没有任何操作之前,最终会进入偏向锁状态。此时,Mark Word字段中的threadID为0,意思是还没有线程持有偏向锁。这里你可能会有点疑惑,新创建的对象不应该进入无锁状态吗?为什么会进入偏向锁状态呢?关于这一点,我们待会再解释。
如果某个线程在某个对象上使用synchronized关键字,发现这个对象的Mark Word处于偏向锁状态,并且threadID为0,那么,这就说明这个偏向锁还没有被使用过,这个线程就会使用CPU提供的CAS原子操作来竞争这个偏向锁。这里的CAS操作指的是:先检查Mark Word值是否等于5(5就表示偏向锁状态,并且threadID是0),如果Mark Word等于5,再设置threadID的值为自己的线程ID,获取偏向锁成功。以上CAS操作需要使用硬件层面提供的CPU指令来完成,以保证原子性和线程安全性。
按照前面的假设,大部分情况下,一个锁只被一个线程使用。因此,大部分情况下,线程执行CAS操作都会成功获取到了偏向锁。如果线程执行CAS操作失败,说明其他线程先它一步,设置了threadID,抢占了偏向锁。对于获取偏向锁失败的情况,涉及到的偏向锁的升级,稍后再讲。我们先看线程成功获取到偏向锁这种情况。
线程成功获取到偏向锁之后,就去执行业务代码了(也就是synchronized关键字所包围的代码)。执行完业务代码之后,线程并不会解锁偏向锁,也就是,不会更改Mark Word字段将threadID设置为0。这是偏向锁有别于轻量级锁和重量级锁,非常独特的一点。这样做的目的是提高加锁的效率。当同一个线程再次请求这个偏向锁时,如下代码所示,线程查看Mark Word,发现Mark Word处于偏向锁状态,并且threadID值就是自己的线程ID。这时,线程不需要做任何加锁操作,就直接可以去执行业务代码了。
public class Demo {
private static Object obj = new Object();
private static int count = 0;
public static void main(String[] args) {
synchronized(obj) { //处于偏向锁状态
count++;
}
...
synchronized(obj) { //再次请求偏向锁
count--;
}
}
}
上一节,我们讲到,为了保证CAS操作的原子性和线程安全性,CAS操作一般使用硬件层面提供的CPU指令来实现,本质上就是在硬件层面上对CAS操作加锁(总线锁)。在多核计算机上,这样的做法的执行效率比较低。因此,减少CAS操作也会大大提高加锁的性能,而这正是偏向锁相对于轻量级锁更加高性能的地方(轻量级锁虽然也不需要排队线程、不需要通过操作系统的系统调用去阻塞和唤醒线程,但仍然需要大量的CAS操作)。线程只需要在第一次获取偏向锁时,使用一次CAS操作,之后再次加锁,就不再需要执行CAS操作了。
以上讲的是理想情况,即在对象有限的生命周期里,这个对象对应的锁只被一个线程使用。接下来,我们再来看看非理想情况。非理想情况有两种,前面已经提到了一种:对象诞生之后处于偏向锁状态,但还没被任何线程获取过,两个线程通过CAS操作竞争偏向锁,一个线程获取到偏向锁,另一个线程没有获取到偏向锁。这个时候,另一个线程该咋办?这是第一种非理想情况。我们再来看第二种非理想情况:一个线程获取了某个偏向锁,但之后又有另一个线程请求这个偏向锁,如下代码所示。这个时候,另一个线程该怎么办?实际上,第一种情况是第二种情况的特殊情况。
public class Demo {
private static Object obj = new Object();
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
synchronized (obj) { //主线程获取了偏向锁
count++;
}
Thread t = new Thread(new Runnable() {
@Override
public void run() {
synchronized (obj) { //线程t又请求偏向锁
count--;
}
}
});
t.start();
t.join();
}
}
对于以上两种非理想情况,显然已经不再符合偏向锁的应用场景了(一个锁只被一个线程使用)。这个时候,请求偏向锁的线程就会将偏向锁升级为轻量级锁。前面讲到,偏向锁不会主动解锁。线程使用完偏向锁(退出synchronized作用范围)之后,仍然保持持有状态(Mark Word中的threadID的值仍然是这个线程的ID)。因此,升级偏向锁时,虚拟机需要暂停持有偏向锁的线程,然后查看它是否还在使用这个偏向锁(是否还在执行synchronized代码块中的代码),如果线程已经不再使用这个偏向锁了,那么虚拟机就将Mark Word设置为无锁状态。如果线程还在使用这个偏向锁,那么虚拟机就将偏向锁升级为轻量级锁。
关于以上升级过程,有几点需要进一步解释一下。
1)首先,偏向锁升级时,为什么要暂停持有偏向锁的线程?这是因为虚拟机要根据持有偏向锁的线程是否正在使用偏向锁,来决定是将偏向锁转为无锁状态还是轻量级锁。实际上,这个过程也是先检查后设置这类复合操作。但是,检查持有偏向锁的线程是否正在使用偏向锁,这个过程比较复杂,无法使用CPU提供的原子CAS指令来实现。于是,这个过程就存在线程安全问题,如下图所示。为了解决这个问题,偏向锁升级时,虚拟机需要暂停持有偏向锁的线程。
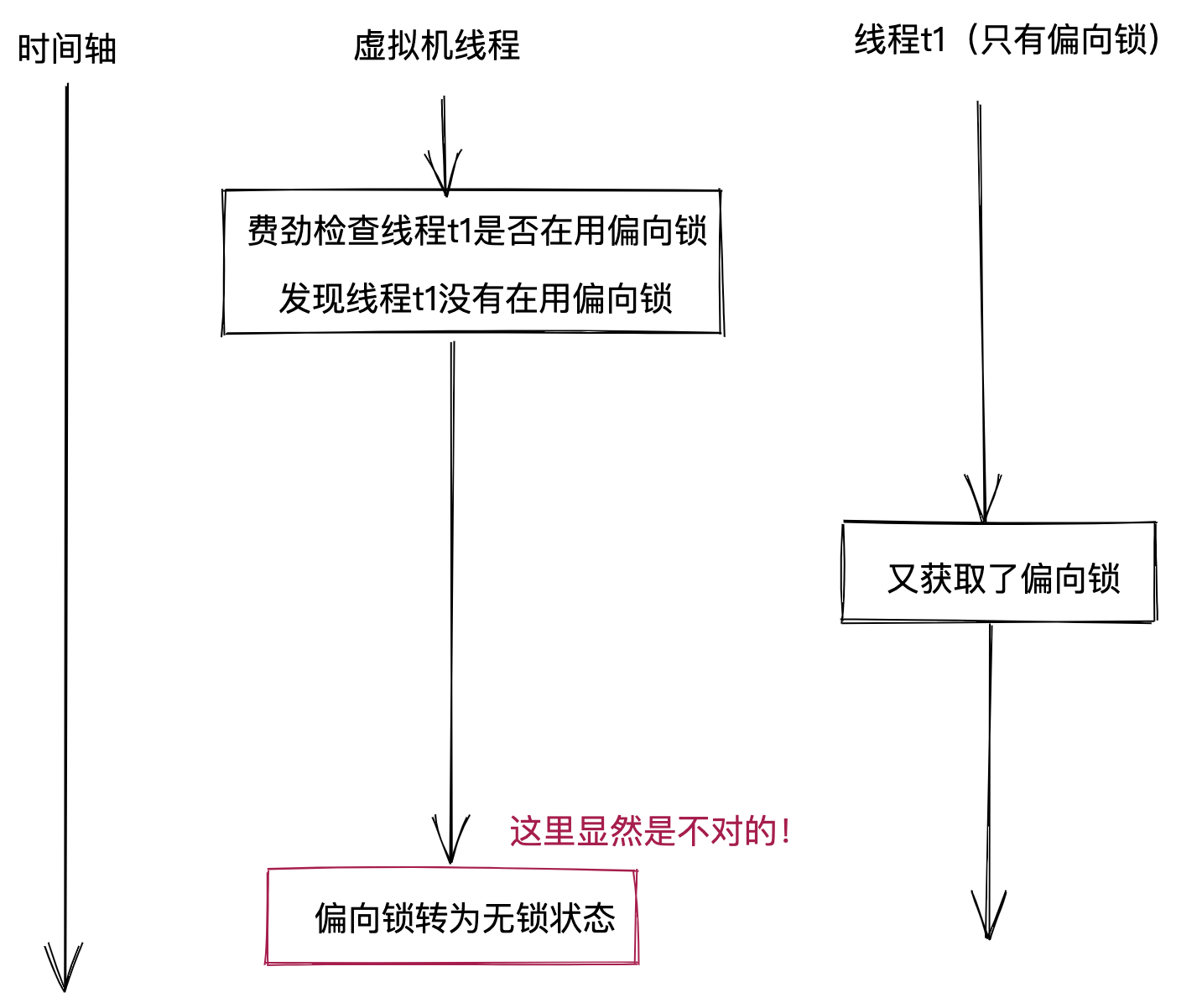
2)其次,如何暂停持有偏向锁的线程?当然,我们可以使用操作系统提供的挂起线程的系统调用来实现,但是,这类系统调用在不同平台上表现不一样,在某些平台上,会导致IO操作出问题。因此,虚拟机最终选择复用垃圾回收器中的STW(Stop The World)功能,来暂停持有偏向锁的线程。
3)最后,如果持有偏向锁的线程没有在使用偏向锁,那么,能否不把Mark Word变为无锁状态,而继续保持偏向锁状态(只把threadID设置为0),将偏向锁移交给另一个是线程使用?之所以没有这么做,是因为STW不仅仅会暂停持有偏向锁的线程,还会暂停所有的其他线程,偏向锁升级代价非常大,耗时超过远超节省下来的时间,还不如最开始就直接使用重量级锁。偏向锁发挥优势的场景是只有一个线程用到这个偏向锁,一旦多个线程用到这个偏向锁,那么偏向锁就毫无优势了。如果一个线程释放了偏向锁,另一个线程继续使用偏向锁,就有可能带来更多的STW操作。
这里我们再补充讲一个知识点。
实际上,synchronized使用的锁只能升级不能降级,也就是,只能从偏向锁,升级为轻量级锁或无锁,再升级为重量级锁。在这个升级链路中,一旦升级为更加严格的锁,就不能再被降级。比如,一旦升级为重量级锁之后,就不能再降级为轻量级锁。除此之外,不像偏向锁,轻量级锁是会主动解锁的,解锁之后的状态就是无锁状态。四种锁状态的转化如下图所示。
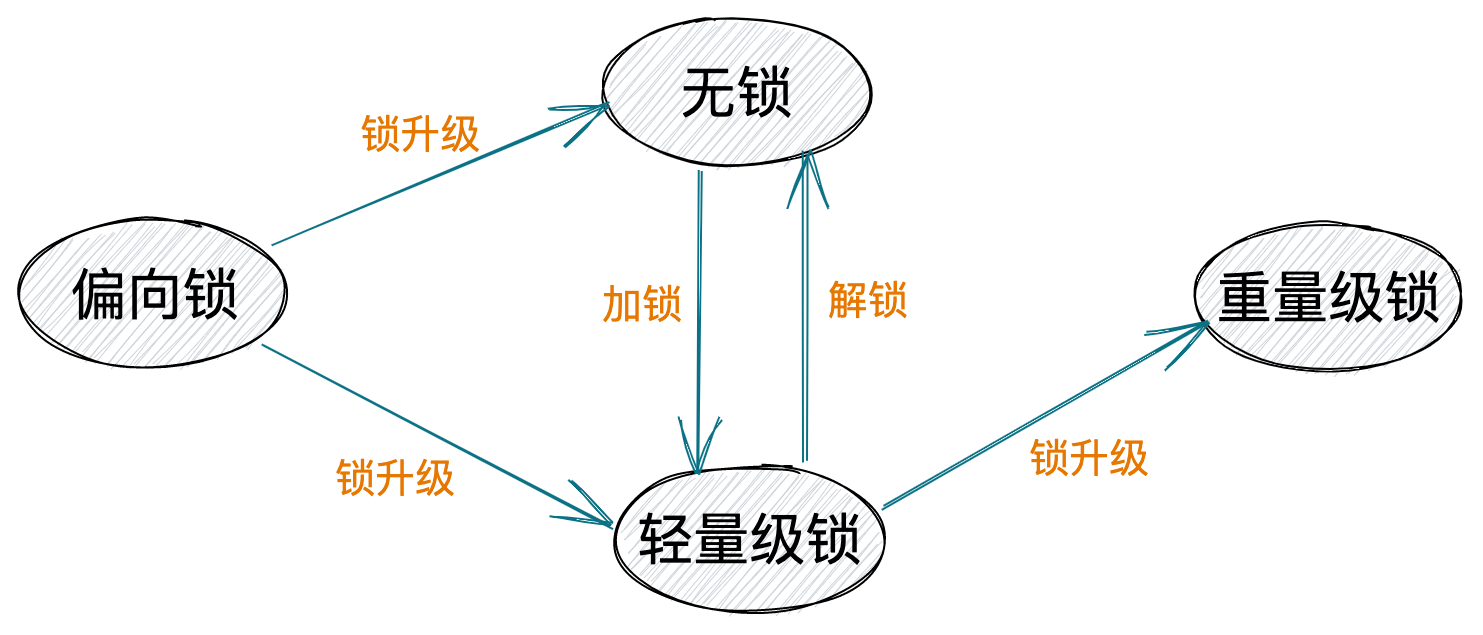
二、轻量级锁
当一个线程去竞争锁时,它会先检查Mark Word的的锁标志位,如果锁标志位是01并且相邻偏向位为0(无锁状态)或锁标志位是00(轻量级锁状态),那么,这就说明锁已经升级到了轻量级锁。我们先来看Mark Word处于无锁状态这种情况。
1)Mark Word处于无锁状态
如果Mark Word处于无锁状态,这时,线程会先在自己栈中创建一个Lock Record结构,并将Mark Word(也就是8个字节,跟一个long、double、引用地址大小一样)拷贝到Lock Record结构中的Displaced Mark Word中。Lock Record的作用主要是为了轻量级锁解锁时快速恢复为无锁状态。实际上,Lock Record就是一个存储Mark Word副本的内存单元,它既可以当成对象存储在堆上,也可以当成局部变量存储在栈上。虚拟机选择了后者,这是因为相比堆,栈上数据的创建和销毁更加快速。
做完拷贝Mark Word到Displaced Mark Word的工作之后,线程会通过CAS操作去竞争轻量级锁。这里的CAS操作指的是,先检查Mark Word的低3位二进制是否为001(无锁状态),如果是的话,再将Mark Word中的Lock Record指针,设置为指向自己的Lock Record。以上CAS操作同样需要使用硬件层面提供的CPU指令来完成,以保证原子性和线程安全性。
2)Mark Word处于轻量级锁状态
以上是理想情况,也就是轻量级锁期望的应用场景:两个线程交叉使用锁,但不会竞争锁,每个线程在请求轻量级锁时,总是能成功。但是,如果一个线程在请求轻量级锁时,另一个线程已经持有了这个轻量级锁,也就是锁标志位是00这种情况,这个时候该怎么办呢?
按理来说,这已经不符合轻量级锁的使用场景了,应该升级为重量级锁。但是,线程抱有侥幸心理,觉得持有轻量级锁的线程会很快释放锁。毕竟升级为重量级锁是件很麻烦的事情,又要创建ObjectMonitor,又要排队,而且,调用操作系统的系统调用阻塞和唤醒内核线程,还会导致用户态和内核态的切换,比较耗时。因此,线程就采用自旋的方式,如下示例代码所示,循环执行CAS操作,如果执行了很多次(比如10次,这个值可以通过JVM参数设置),仍然没有等到另一个线程释放轻量级锁,那么它就只能将轻量级锁升级为重量级锁了。
int count = 0;
while (count < 10) {
..do CAS to get lightweight lock..
}
那么,自旋多少次才合适呢?如果自旋次数太少,有可能刚升级为重量级锁,另一个线程就释放了轻量级锁,这样就很可惜。如果自旋次数太多,就会浪费CPU资源做很多无用功。针这个问题,Java发明了一种特殊的自旋:自适应自旋。如果上次自旋之后成功等到了另一个线程释放轻量级锁,那么下次自旋的次数就增加,如果上次自旋没有等到等到另一个线程释放轻量级锁,那么下次自旋的次数就减少。你可能会说,如果自旋没成功等到轻量级锁,那么就会升级为重量级锁,就没有下次自旋这一说了。实际上,这里说的自旋不是针对一个轻量级锁,而是针对所有在用的轻量级锁。
线程自旋等待轻量级锁失败,只能将轻量级锁升级为重量级锁了。跟偏向锁的升级不同,轻量级锁的升级不需要STW,因为所有的操作都可以使用硬件提供的原子CAS指令来完成。在升级的过程中,持有轻量级锁的线程继续干他该干的事情,请求轻量级锁的线程负责升级任务:创建Monitor锁,将自己放到Monitor锁的_cxq中,然后调用操作系统提供系统调用阻塞自己。实际上,这就是上一节中讲到的没有获取到重量级锁的线程要做的事情。
上面讲解了轻量级锁获取和升级的过程,我们再来讲下轻量级锁的解锁过程。持有轻量级锁的线程,在释放轻量级锁时,会先检查锁标记位,此时会有两种情况:1)如果锁标记位为00,说明轻量级锁没有被升级,那么,线程只需要使用CAS操作来解锁即可。这里的CAS操作指的是:先检查锁标记位是否是00,如果是,再将Displaced Mark Word(之前的无锁状态)赋值给Mark Word。
2)如果锁标志位为10,说明轻量级锁已经升级为重量级锁,那么,解锁的过程就变为:持有轻量级锁的线程去唤醒等待重量级锁的线程。实际上,这就是上一节中讲到的重量级锁的解锁过程。
三、锁消除
搞定了偏向锁和轻量级锁,synchronized的另外两个优化(锁消除和锁粗化)相比而言就简单多了。虚拟机在执行JIT编译时,会根据对代码的分析(逃逸分析,这个在JVM模块中再讲),去掉某些没有必要的锁。如下示例代码所示。为了保证多线程操作的安全性,StringBuffer中的append()函数在设计实现时加了锁。但是,在下面的代码中,strBuffer是局部变量,不会被多线程共享,更不会在多线程环境下调用它的append()函数。因此,append()函数的锁可以被优化消除。
public class Demo {
public String concat(String s1, String s2) {
StringBuffer strBuffer = new StringBuffer();
strBuffer.append(s1);
strBuffer.append(s2);
return strBuffer.toString();
}
}
四、锁粗化
上一节中,当讲到synchronized作用于代码块时,我们提到,缩小加锁范围能够提高程序的并发程度,提高多线程环境下的程序的执行效率。但是,在有些情况下,虚拟机在执行JIT编译时,会扩大加锁范围,将对多个小范围代码的加锁,合并一个对大范围代码的加锁,这样的做法叫做锁粗化。如下所示代码所示,执行10000次append()函数,会加锁解锁10000次。通过锁粗化,编译器将append()函数的锁去掉,移到for循环外面,这样就只需要加锁解锁1次即可。
public class Demo35_4 {
private StringBuffer strBuffer;
public void reproduce(String s) {
for (int i = 0; i < 10000; ++i) {
strBuffer.append(s);
}
}
}
思考题
我们发现,Java实现的synchronized锁,大部分逻辑(竞争锁、排队、解锁等)都是自己实现的,只有阻塞内核线程这部分逻辑,是调用的操作系统提供的系统调用。实际上,大部分操作系统都提供了锁,比如Linux中pthread_mutex_lock,已经实现了竞争锁、排队、解锁等等一系列工作,那么,Java为什么不直接使用操作系统提供的现成的锁来实现synchronized呢?
当Mark Word处于偏向锁状态时,Mark Word就无法记录hashCode值了。当Mark Word处于轻量级锁、重量级锁状态时,hashCode、cms_free、GC age统统无法记录,如果虚拟机或者程序中需要用到这些信息,那么该怎么办呢?