死锁、活锁、饥饿
死锁、活锁、饥饿
提示
死锁、活锁、饥饿:如何设计策略实现Java多线程死锁检测和撤销?
在前面的几节中,我们讲解了各种锁,比如,synchronized或Lock悲观锁,自旋+CAS乐观锁。锁的使用可以解决多线程安全问题,但同时也会带来性能问题(加锁、解锁耗时)。实际上,除了性能问题之外,锁的使用还会导致其他问题,比如死锁、活锁、饥饿。本节,我们就来讲讲,锁的使用导致的死锁、活锁、饥饿问题。
一、死锁
我们把死锁、活锁、饥饿这三个问题,统称为活跃性问题。实际上,活跃性问题是一个常见的问题,多线程、多进程、多机(分布式系统)请求共享资源(不一定是锁),都有可能出现活跃性问题。不过,在本专栏中,我们只关注多线程请求锁时的活跃性问题。
我们先来看下活跃性问题中的死锁问题。死锁指的是,多个线程互相等待对方持有的资源,而导致线程无法继续执行的问题。我们举例来解释一下,示例代码如下所示。如果线程t1执行Demo对象中的f()函数,线程t2执行同一个Demo对象中的g()函数,两个线程就有可能会发生死锁。线程t1持有lock1锁,同时请求lock2锁,线程t2持有lock2锁,同时请求lock1锁。两个线程将会一直阻塞等待对方持有的锁,无法继续执行。
public class Demo {
private Object lock1 = new Object();
private Object lock2 = new Object();
public void f() {
synchronized (lock1) {
synchronized (lock2) {
//...业务逻辑...
}
}
}
public void g() {
synchronized (lock2) {
synchronized (lock1) {
//...业务逻辑...
}
}
}
}
对于上面这个例子,线程持有锁以及等待锁的情况非常清晰,我们一眼就能看出代码是否存在死锁,但是,很多情况下,死锁的检测并非如此简单。当多个线程竞争多个锁时,如果线程持有锁以及等待锁的情况非常复杂,那么,计算机就需要一定的算法来检测死锁。
死锁检测算法有很多,这里我们介绍一种比较简单的。我们将线程竞争锁的场景,抽象为有向图这种数据结构。线程抽象为图中的顶点,如果线程A等待线程B持有的锁,那么,我们就在线程A和线程B对应的节点之间添加一条有向边。在有向图构建好之后,我们只需要使用DFS算法,检测有向图中是否存在环即可。如果有向图中存在环,那么,这就说明多个线程之间存在锁的循环等待,即存在死锁。相反,如果有向图中不存在环,那么就说明不存在死锁。示例如下图所示,以下情况存在死锁。
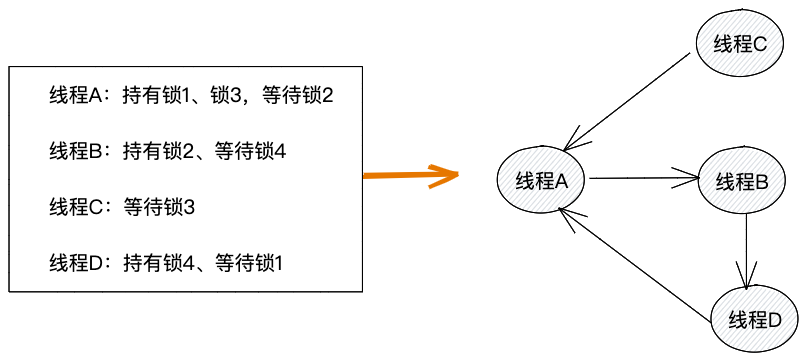
我们知道,大部分数据库都实现了死锁检测和解决。当数据库检测到死锁时,会终止循环等待锁的线程中的其中一个线程,让其释放所持有的锁,这样循环等待就被打破,其他线程便可以获取到锁,顺利往下执行。不过,死锁检测本身并不属于Java语言层面的工作,甚至JUC也并没有提供相应的解决方案。如果我们希望程序能自动进行死锁检测和解决,那么,需要我们自己来编写相应的代码。
尽管在语言层面无法实现死锁的自动检测和解决,但是,当发生死锁时,我们仍然可以通过类似jstack这类工具,将线程的运行状态等重要信息打印出来,以便分析死锁发生的原因,并对代码做及时的调整。关于如何使用jstack等工具分析死锁,我们在后面的章节中详细讲解。实际上,尽量避免编写引发死锁的代码,才是解决死锁问题的最根本方法。那么,如何避免死锁呢?常用的方法有以下两个。
1)避免死锁方式一:统一线程请求锁的顺序
实际上,上述示例代码发生死锁的原因,是两个线程采用不同的加锁顺序。如果两个线程采用相同的加锁顺序,那么,就可以避免发生死锁。如下代码所示,两个线程分别同时执行f()函数和g()函数,只有一个线程成功获取lock1锁,获取lock1锁的线程,进而又会成功获取lock2锁,因此,不会发生死锁。
public class Demo {
private Object lock1 = new Object();
private Object lock2 = new Object();
public void f() {
synchronized (lock1) {
synchronized (lock2) {
//...业务逻辑...
}
}
}
public void g() {
synchronized (lock1) {
synchronized (lock2) {
//...业务逻辑...
}
}
}
}
以上加锁顺序的调整比较简单,但有些情况会稍微复杂,如下代码所示,如果多线程执行transfer()函数,那么,是否会存在死锁问题呢?
public class Transaction {
public static void transfer(Account from, Account to, double transAmount) {
synchronized (from) {
synchronized (to) {
from.amount -= transAmount;
to.amount += transAmount;
}
}
}
}
我们先对上述代码的加锁方式做些解释。"+="、“-=”操作跟自增、自减操作类似,都是非原子操作,并发执行会存在线程安全问题。为了解决线程安全问题,最简单的方法是给transfer()函数添加类锁,但类锁粒度太大,会导致所有的转账业务均无法并发执行,严重影响转账业务的执行效率。实际上,如下示例所示,尽管同一组账户(A<->B与A<->B)之间不可以同时转账,但是,两组不同的账户(A<->B与C<->D)之间是可以同时转账的。因此,我们只需要使用细粒度的对象锁,只对转账的双方账户加锁,避免多个线程同时对同一组账户转账,这样就可以保证transfer()函数的线程安全性。
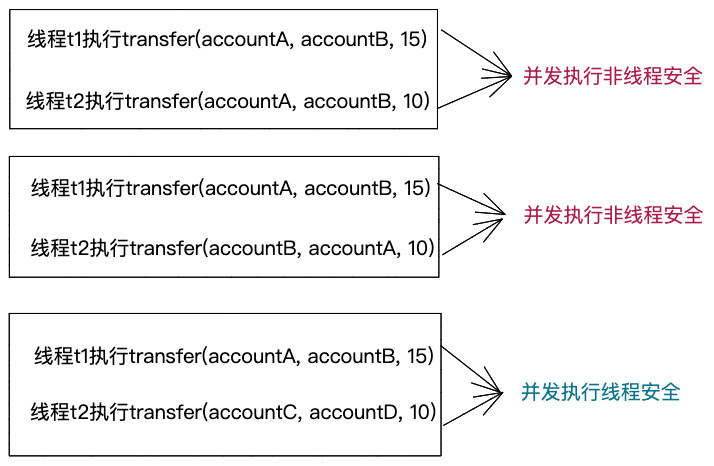
对transfer()函数的加锁方式有了清晰了解之后,我们再来看多线程并发执行transfer()函数的死锁问题。两个线程执行并发执行transfer()函数时,看似加锁顺序是一致的:先对from加锁,再对to加锁,但是,问题在于from和to并不是确定的。假设有两个Account对象,分别为accoutA和accountB。一个线程执行transfer(accountA, accountB, 15),对应的加锁顺序为:先对accountA加锁,再对accountB加锁。另一个线程执行transfer(accountB, accoutA, 25),对应的加锁顺序为:先对accountB加锁,再对accountA加锁。显然,两个线程的加锁顺序正好相反,并发执行就有可能发生死锁。
为了解决上述问题,我们需要重新定义加锁的顺序。因为Account中包含一些可比较大小的不变成员变量,比如id,我们可以基于id来定义加锁的顺序。如下代码所示。假设accountA的id小于accountB的id,执行transfer()函数,不管是从accountA到accountB转账,还是从accountB到accountA转账,transfer()函数总是先对accountA加锁,再对accountB加锁,从而避免了死锁。
public class Transaction {
public static void transfer(Account from, Account to, double transAmount) {
Account lockFirst = from;
Account lockSecond = to;
if (from.id > to.id) {
lockFirst = to;
lockSecond = from;
}
synchronized (lockFirst) {
synchronized (lockSecond) {
from.amount -= transAmount;
to.amount += transAmount;
}
}
}
}
2)避免死锁方式二:避免线程持有锁并等待锁
从死锁的定义,我们可以发现,线程持有一个锁的同时等待另一个锁,是产生死锁的重要原因。如果我们避免线程持有一个锁的同时等待另一个锁,便可以有效的解决死锁问题。具体的做法是:如果一个线程请求一个锁时,这个锁已经被其他线程持有,那么这个线程不再阻塞等待这个锁,而是释放掉所持有的所有锁,让其他线程先执行。上述解决思路对应的代码实现如下所示。需要注意的时,synchronized无法像Lock那样支持非阻塞的加锁方式,因此,这种死锁的避免方式只能使用Lock来实现。
public class Demo {
private Lock lock1 = new ReentrantLock();
private Lock lock2 = new ReentrantLock();
public void f() {
for(;;) {
lock1.lock();
try {
boolean locked = lock2.tryLock();
if (locked) { //两个锁都获取了
try {
//...业务逻辑...
return;
} finally {
lock2.unlock();
}
} // else 没有获取lock2锁,执行finally,释放lock1锁
} finally {
lock1.unlock();
}
}
}
public void g() {
for(;;) {
lock2.lock();
try {
boolean locked = lock1.tryLock();
if (locked) { //两个锁都获取了
try {
//...业务逻辑...
return;
} finally {
lock1.unlock();
}
} // else 没有获取lock1锁,执行finally,释放lock2锁
} finally {
lock2.unlock();
}
}
}
}
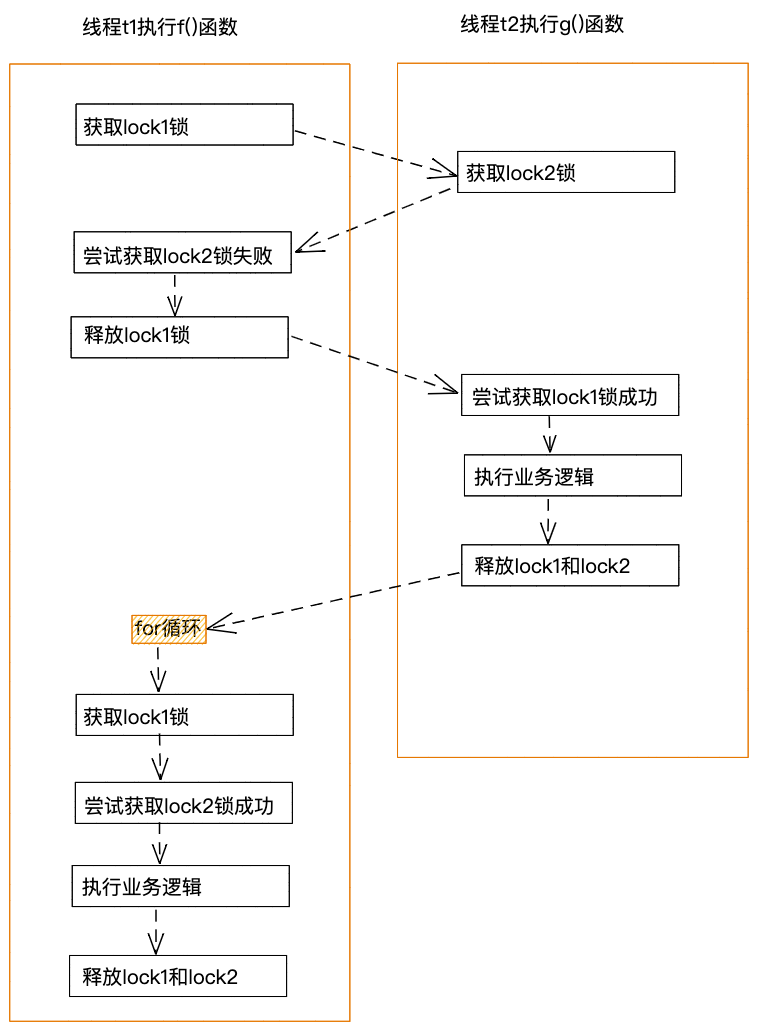
如下图所示,假设两个线程t1和t2分别同时执行f()函数和g()函数,线程t1获取到lock1锁,线程t2获取到lock2锁,线程t1尝试获取lock2锁失败,则会将已经持有的lock1锁释放。此时线程t2尝试获取lock1锁成功。线程t2同时获取到lock2锁和lock1锁,便可以顺利执行业务逻辑。在业务逻辑完之后,线程t2将lock2锁和lock1锁释放,此时,线程1便可成功获取lock1锁和lock2锁,然后执行相应的业务逻辑。
二、活锁
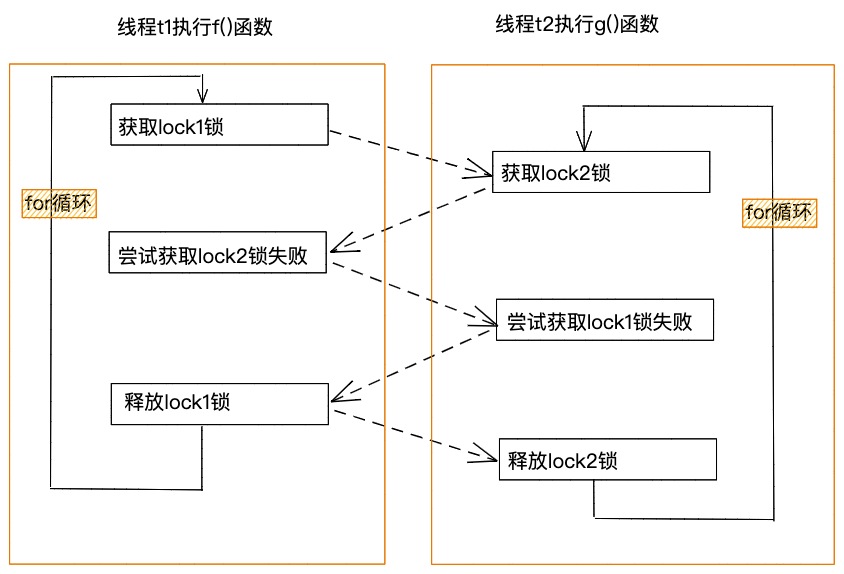
实际上,避免死锁的方式二(避免持有锁并等待锁)是存在问题的。如下图所示,在极端情况下,两个线程循环反复执行以下逻辑:线程t1获取lock1锁,线程t2获取到lock2锁。线程t1尝试获取lock2锁失败之后,释放掉lock1锁。与此同时,线程t2尝试获取lock1锁失败之后,释放掉lock2锁。然后,线程t1和t2再重复执行上述逻辑。这就导致线程t1和t2一直循环加锁、尝试加锁、释放锁。我们把这种情况叫做活锁。
死锁和活锁的区别有两点。第一点,处于死锁状态的两个线程均处于阻塞状态,不消耗CPU资源。相反,处于活锁状态的两个线程,仍然在不停的执行加锁、尝试加锁、释放锁等代码逻辑,消耗CPU资源。比起死锁,活锁的性能损耗更大。第二点,死锁发生的概率很低。在高并发情况下,两个线程频繁竞争执行临界区,才有可能发生死锁。不过,相对于死锁,活锁发生的概率更低。发生活锁,除了具备死锁发生的条件之外,还需要两个线程的执行过程非常同步,才能保证for循环一直不退出。
对于死锁和活锁的区别,我们举一个生活中例子,再形象地解释一下。在一个比较窄但允许两人同行的马路上,两个人相对而行,如果两个人相撞,那么,死锁的处理思路是:两个人僵持不动,谁都无法往前走。活锁的处理思路是:两个人都很客气的让路给对方,但是,两人同时移动到另一侧,又继续相撞,再移动回来又相撞,一直这样持续下去,那么就会发生活锁。从这个例子上,我们可以看出,活锁发生的概率是非常非常低的,两人的移动必须一直保持完全同步才可以,不然,很快就可以解锁。
尽管活锁出现的概率比较低,但一旦出现活锁,便会导致比较严重的问题:线程持续做无用功,业务代码无法执行,白白浪费CPU资源。因此,我们需要想办法解决活锁问题。实际上,解决的办法也很简单,我们只需要让线程在执行的过程中,暂停随机的一小段时间,打破两个线程的持续同步即可。对于代码实现方法来说,我们既可以在tryLock()之后添加sleep()语句,也可以将tryLock()函数改为带超时时间的tryLock()函数。示例代码如下所示。我们只给出了f()函数修改之后的代码,对于g()函数,修改方法类似,留给你自己实现。
public void f() {
Random r = new Random();
for(;;) {
lock1.lock();
try {
boolean locked = false;
try {
locked = lock2.tryLock(r.nextLong()%10, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
// log error and return
}
if (locked) { //两个锁都获取了
try {
//...业务逻辑...
return;
} finally {
lock2.unlock();
}
} // else 没有获取lock2锁,执行finally,释放lock1锁
} finally {
lock1.unlock();
}
}
}
三、饥饿
死锁和活锁是两个或两个以上线程的整体状态,饥饿则是一个线程的状态。死锁和活锁都会导致线程处于饥饿状态,迟迟获取不到锁。不过,导致线程饥饿的情况还有很多。在前面的章节中,我们也介绍过一些发生线程饥饿的情况。比如,对于非公平锁,因为新来的线程不需要排队,就可以插队直接竞争锁,所以,如果一直都有新来的线程竞争锁,那么,排队的线程就有可能一直没有机会获取到锁,就会出现饥饿现象。实际上,自旋+CAS也算是非公平锁,源源不断的线程执行自旋+CAS,有可能会导致有些线程一直无法成功执行CAS而持续自旋,从而出现饥饿的现象。除此之外,对于读写锁,如果等待队列的队首线程在等待写锁,即便其他线程持有读锁,新来请求读锁的线程也会直接排队,而非直接获取读锁,这样做就是为了避免等待写锁的线程迟迟获取不到写锁而饥饿。
实际上,死锁、活锁、饥饿这些活跃性问题,大部分情况下都发生在高并发的极端情况下,比如流量突增。这也是活跃性问题很难测试、很难发现、很难重现的主要原因。活跃性问题一旦发生,就会导致非常严重的结果。比如,Tomcat等Web服务器采用线程池来多线程执行用户请求,当多个线程发生死锁、活锁、饥饿等活跃性问题时,这些线程处理的请求将会超时,并且这些线程迟迟无法响应其他请求,当发生活跃性问题的线程越来越多时,线程池中的可用线程就越来越少,大量用户请求需要排队等待线程执行,最终导致请求大量超时。
不过,话又说回来,在平时的业务开发中,我们很少会编写多线程代码,也很少会用到线程级的锁。比如,对于前面讲到的transfer()函数,在真实的业务开发中,数据一般存储在数据库中,transfer()函数直接操作数据库中的account表中的记录,实现两个账户中金额的加减。当transfer()函数操作account表时,其他进程也有可能正在操作Account表中相同的记录。而单单使用线程级的锁,并不能解决进程间的互斥问题。针对这种情况,我们一般会使用数据库锁(可以看做是进程级的锁)来解决。当执行转账业务时,transfer()函数使用数据库锁,先后锁定Account表中的转账所涉及的两行记录,以免其他进程或线程操作这两行记录。
实际上,相比线程级的锁,进程级的锁更容易引发死锁。这是因为,两个进程对应的程序有可能是两个不同的程序员开发的,甚至有可能是两个不同的团队开发的。一个团队并不不知道另一个团队所开发的程序,到底都用了哪些锁,以及如何使用的这些锁,因此,协调好统一的加锁顺序是比较困难的。这也是我在过往的开发中经常遇到的死锁的情况。
四、思考题
哲学家进餐问题是死锁问题的经典例子。n个哲学家围坐在餐桌旁,n只筷子分别摆放在任意两个哲学家中间。哲学家每次都先从左边拿筷子,再从右边拿筷子,两个筷子都拿到之后才可以进餐,进完餐之后放下两个筷子。请编程模拟以上哲学家的进餐过程,并且指出死锁的原因以及相应的解决方案。