累加器
累加器
提示
如何使用数据分片、哈希优化、去伪共享提高累加器性能?
前面几节中,我们讲到锁、自旋+CAS、原子类。对于如下代码,如果我们希望将其改造成线程安全的,那么该如何来做呢?
public class Counter {
private long sum;
public long get() {
return sum;
}
public void add(long value) {
sum += value;
}
}
为了让以上代码线程安全,我们只需要对add()函数进行处理。对于add()函数,第一种线程安全的实现方式是:对add()函数加锁,但是加锁会影响程序本身的性能。第二种线程安全的实现方式是:使用自旋+CAS的方式,这样可以避免加锁,在低并发的情况下,这种实现方式的性能远优于加锁,但是,从零实现自旋+CAS,需要用到Unsafe类,风险比较大且编程复杂。第三种线程安全的实现方式是:直接使用封装了自旋+CAS的原子类,相对于第二种实现方式,编程实现简单了许多。这三种实现方式对应的代码如下所示。
// 线程安全实现方式一:加锁
public void add_lock(long value) {
synchronized (this) {
sum += value;
}
}
// 线程安全实现方式二:自旋+CAS
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long sumOffset;
static {
try {
sumOffset = unsafe.objectFieldOffset
(Counter.class.getDeclaredField("sum"));
} catch (Exception ex) { throw new Error(ex); }
}
public void add_cas(long value) {
boolean succeeded = false;
while (!succeeded) {
long oldValue = sum;
succeeded = unsafe.compareAndSwapLong(
this, sumOffset, oldValue, oldValue+value);
}
}
// 线程安全实现方式三:原子类
private AtomicLong atomicSum = new AtomicLong(); //替代sum成员变量
public void add_atomic(int value) {
atomicSum.addAndGet(value);
}
实际上,针对累加这种特殊的业务场景,JUC提供了专门的LongAdder累加器,它比AtomicLong原子类性能更高。在高并发的情况下,多线程同时执行add()函数,AtomicLong会因为大量线程不断自旋而性能下降,LongAdder却可以持续保持高性能。那么,如此高性能,LongAdder是如何做到的呢?本节,我们就来讲一讲LongAdder累加器的用法及其实现原理。
一、基本用法
LongAdder在JDK8中引入,功能非常专精尖,用来实现线程安全的高性能累加操作。LongAdder中包含的主要函数有两个:add()函数和sum()函数。add()函数用来累加,sum()函数用来返回累加之后的总和。
我们使用LongAdder对Counter类进行改造,以保证其线程安全,改造之后的代码如下所示。这里需要注意的是,在高并发的情况下,sum()函数并不能返回精确的累加值,这也是其为了实现高性能所付出的代价。也正因如此,LongAdder一般仅限用于对累加值的精确性要求不高的场合,比如应用于数据统计中。至于sum()函数为什么不能返回精确值,我们稍后讲解。
public class CounterLongAdder {
private LongAdder ladder = new LongAdder();
public void add(long value) {
ladder.add(value);
}
public long get() {
return ladder.sum();
}
}
LongAdder的使用方法非常简单,但其底层实现原理却比较复杂。为了实现高性能累加,LongAdder的底层实现原理涉及数据分片、哈希优化、去伪共享、非精确求和等各种优化手段。接下来,我们就一一讲解一下它们。
二、数据分片
在高并发的情况下,AtomicLong性能不高的主要原因是,多线程同时CAS更新一个变量(累加变量)。相比于AtomicLong,在高并发的情况下,LongAdder的累加操作依然可以保持高性能,这主要归功于数据分片。如下图所示,LongAdder将一个累加变量分解为多个累加变量,多线程同时执行累加操作时,不同的线程对不同的累加变量进行操作,线程之间互不影响,这样就避免了一个线程需要等待另一个线程操作完成之后再操作。当调用LongAdder上的sum()函数时,LongAdder将多个累加值相加,便可以得到最终的累加值。
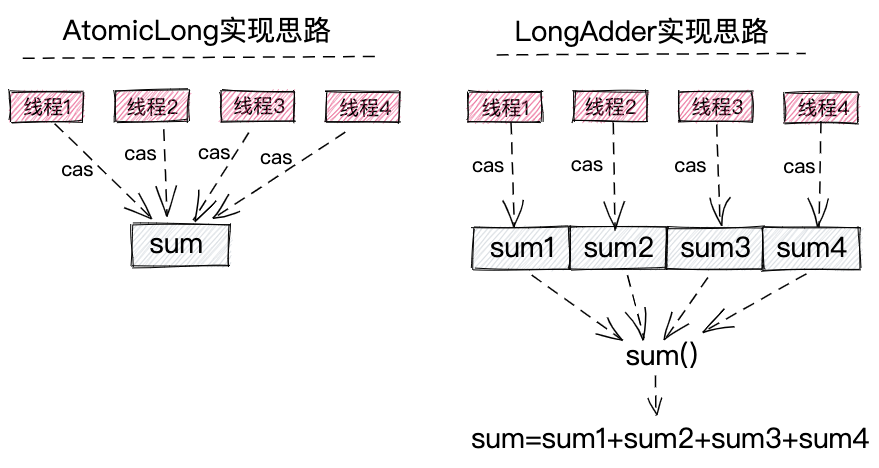
当然,以上只是基本的实现原理,在具体的代码实现中,LongAdder还包含很多细节优化。我们结合LongAdder的源码,来看下累加操作的主要处理流程。LongAdder中的部分源码如下所示。以下源码包含LongAdder类中的核心的成员变量和函数。
public class LongAdder extends Striped64 {
public LongAdder() {}
public void add(long x) { ... }
public long sum() { ... }
}
abstract class Striped64 extends Number {
static final int NCPU = Runtime.getRuntime().availableProcessors();
transient volatile Cell[] cells;
transient volatile long base;
transient volatile int cellsBusy;
//LongAdder中add()函数的实现依赖于Striped64中的longAccumulate()函数
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) { ... }
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 以下是实现value的CAS函数
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
valueOffset = UNSAFE.objectFieldOffset(
Cell.class.getDeclaredField("value"));
} catch (Exception e) { throw new Error(e);}
}
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
}
}
从以上代码,我们可以看出,LongAdder中不包含任何成员变量,成员变量完全继承自Striped64。我们先简单介绍一下这几个成员变量。如下所示。
1)cells
cells数组保存多个累加变量。Cell本身的定义非常简单,只包含一个成员变量value,以及一个操作value的cas()函数。为了节省空间,cells数组支持动态扩容,并且,最开始初始化为null,只有第一次出现线程竞争执行add()函数时,cells数组才会被创建。
2)NCPU
NCPU表示JVM最大可用CPU核数。cells数组的长度必须是2的幂次方,每次扩容都会增加为原来数组长度的2倍。当cells数组长度为大于等于NCPU的最小2的幂次方时(比如,如果NCPU为6,那么cells数组最大长度为8),cells数组就不再扩容了。cells数组的长度之所以要求是2的幂次方,跟HashMap中数组的长度是2的幂次方的原因相同,都是为了快速求模(求模的使用场景待会会讲到)。建议你回过头去看下第13节。之所以cells数组的长度大于等于NCPU之后就不再扩容,是因为同时执行累加操作的线程数不可能大于CPU的核数。当cells数组的长度大于等于NCPU时,cells数组中的累加变量个数,便可以满足最大NCPU个线程同时互不干涉地执行累加操作。
3)base
base是一个比较特殊的累加变量。当线程执行add()函数时,首先尝试CAS更新base(将新增值累加到base上),如果成功,则直接返回,如果失败,再执行分片累加的逻辑(将新增值累加到cells数组中)。在低并发的情况下,使用base可以有效避免执行复杂的分片累加逻辑。
4)cellBusy
cellBusy用来实现锁,类似ReetrantLock中的state字段,cellBusy初始化为0,多个线程通过CAS竞争更新cellBusy,谁先将cellBusy设置为1,谁就持有了这把锁。这把锁用来避免多个线程同时创建cells数组(Cell[] cells = new Cell[n];)、创建cells数组中的Cell对象(cells[i] = new Cell()😉、以及对cells数组进行动态扩容,保证这三个操作的线程安全性。
对核心成员变量有了简单了解之后,我们再来看下LongAdder的累加过程,对应的源码如下所示。为了展示基本实现原理,避免过多的实现细节的干扰,我对代码进行了稍许调整。
// 位于LongAdder.java
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if (!casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
上述代码非常简洁,可读性有点差。我们对上述代码逻辑做了梳理,如下图所示。其中,getProbe()为哈希函数(此哈希函数的实现原理稍后讲解),返回当前线程对应的哈希值。因为cells数组长度n为2的幂次方,所以,getProbe()&m(m等于n-1)就相当于getProbe()%n(关于这一点,请参看第13节HashMap底层原理的讲解),因为位运算比取模运算效率要高,因此,getProb()&m要比getProbe()%n的执行效率高。getProbe()&m得到的是当前线程应该更新的累加变量在cells数组中的下标。也就是说,如果getProbe()&m等于k,那么,当前线程会通过CAS将新增值x累加到cells[k]的value变量上。
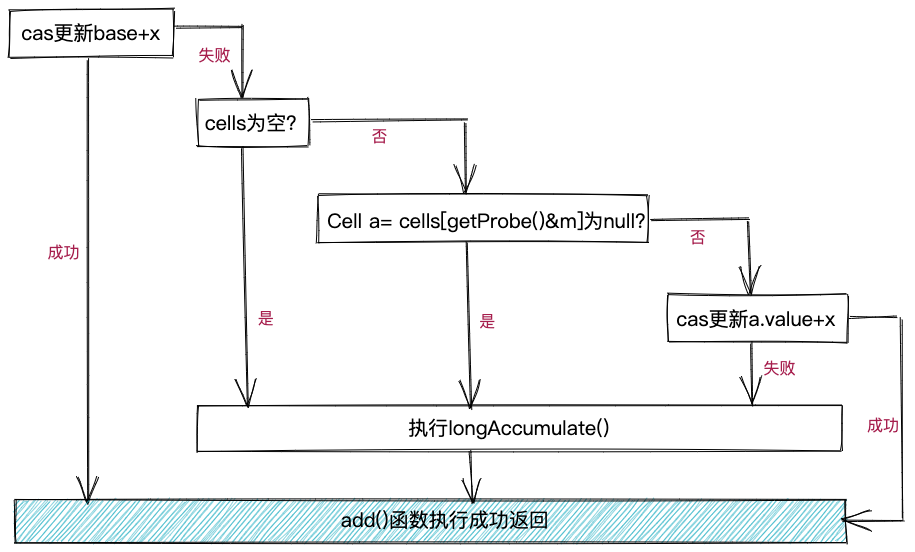
从以上代码逻辑,我们可以发现,只有当线程执行cas成功更新base,或者执行cas成功更新cells数组中的累加变量时,add()函数才会直接返回。否则,线程会进入Striped64类中的longAccumulate()函数继续执行。进入longAccumulate()函数主要对应三种情况:cells为空;线程要更新的cells中的Cell对象为null;cas更新cells中的Cell对象的value值失败。longAccumulate()函数的代码比较长,涉及比较多的实现细节,这里我们简单介绍一下它的核心逻辑,具体如下图所示,其中主要包含4部分逻辑:创建cells数组、创建cells数组中的Cell对象、cells数组扩容、cas执行cells数组上的累加操作。
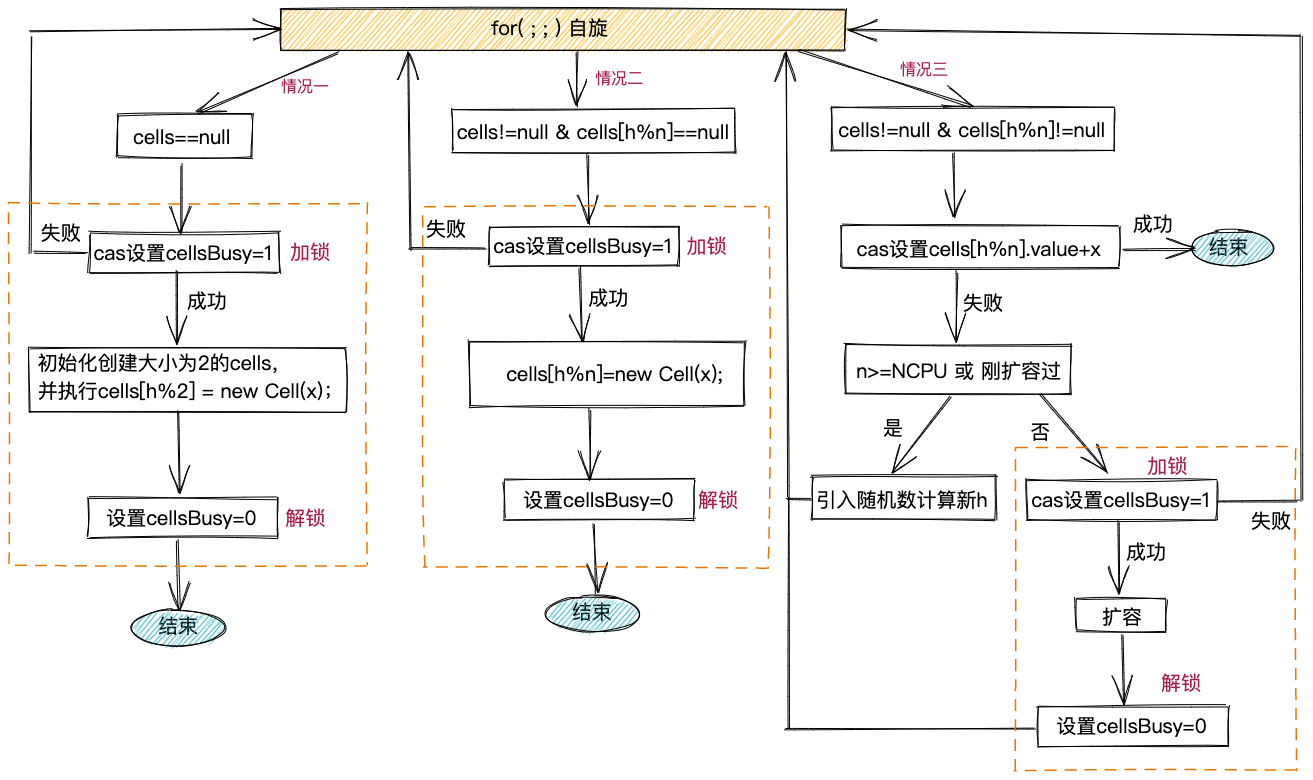
三、哈希优化
从上述代码逻辑中,我们可以发现,代码的执行过程,会频繁用到哈希函数(上图中出现h的地方)。因此,哈希函数的执行效率严重影响LongAdder的执行效率。因此,LongAdder对哈希函数进行了一些性能优化。
当线程通过cas将新增值累加base失败时,线程会通过cas将新增值累加cells数组中,那么,到底累加到cells数组中哪个Cell对象上呢?前面提到,对应Cell对象的下标通过getProbe()%n公式来计算得到。其中,n表示cells数组的长度,getProbe()是哈希函数。因为n为2的幂次方,因此getProbe()%n可以转化为getProbe()&(n-1),以提高计算速度。
除此之外,哈希函数计算得到的哈希值,会保存在线程对应的Thread对象的成员变量中,之后便可以一直重复使用,除非发生冲突,两个线程同时执行cas更新同一个Cell对象,执行cas失败的线程会重新生成新的哈希值,并同步更新到对应的Thread对象中。
//直接获取当前线程对应的Thread对象的PROBE成员变量值
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
//基于老的哈希值probe重新计算新的哈希值,并存储到当前线程对应的Thread对象的PROBE成员变量中
static final int advanceProbe(int probe) {
probe ^= probe << 13; // xorshift
probe ^= probe >>> 17;
probe ^= probe << 5;
UNSAFE.putInt(Thread.currentThread(), PROBE, probe);
return probe;
}
四、去伪共享
细心的读者可能已经发现,Cell类定义的前面添加了@Contended注解。注解看起来虽小,但其隐藏了一个很重要的优化,那就是去伪共享。去伪共享是提高多线程并发执行效率的重要手段,不仅在LongAdder中用到,在Disruptor高性能消息队列中也有用到。在解释去伪共享之前,我们先来解释一下什么是伪共享。
前面我们提到,CPU读写缓存的最小单元是缓存行。不同CPU上的缓存行大小不同,可以为32字节、64字节或128字节等,常见的大小为64字节。参照第9节中对象大小的计算公式,Cell对象头占12字节,value成员变量为long类型,占8字节。对象头与value成员变量之间有4字节对齐填充,因此,一个Cell对象占24字节。假设一个缓存行大小为64字节,那么,两个Cell对象就有可能存储在同一个缓存行中。如下图所示。
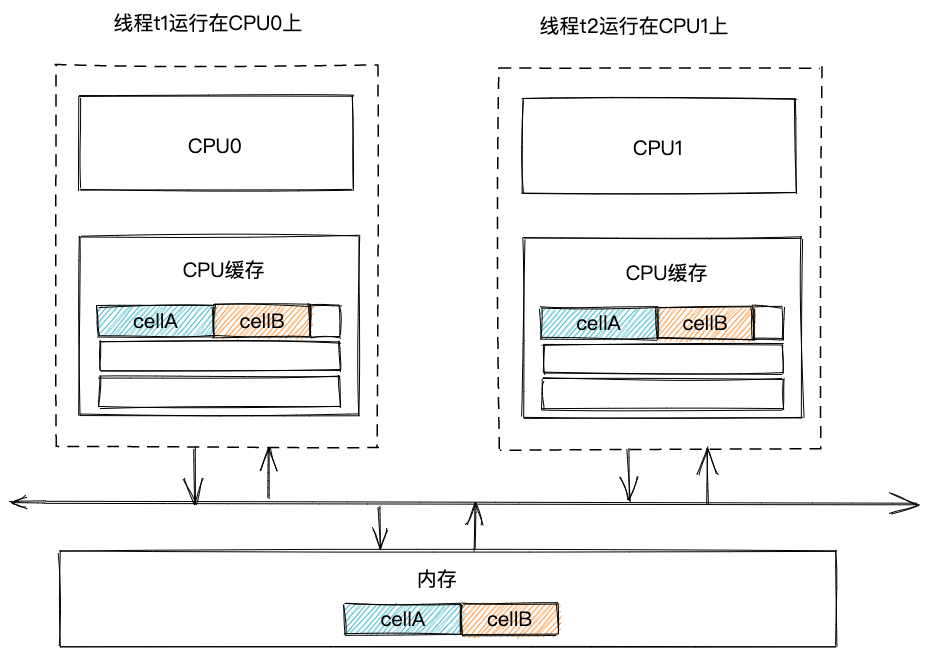
因为数据是以缓存行为单位来读写的,所以,当线程t1从内存中读取cellA到缓存中时,会顺带着读取cellB,同理,当线程t2从内存中读取cellB到缓存中时,会顺带着读取cellA。当线程t1更新cellA的值时,按理来说,并不会影响线程t2对cellB的缓存,但是,缓存中的数据是按照缓存行来读写的,因此,线程t1会将整个缓存行设置为无效,这就会导致线程t2对cellB的缓存也会失效,需要重新从内存中读取。同理,线程t2更新cellB值时,也会导致线程t1对cellA的缓存失效。两个线程互相影响,导致缓存频繁失效。
以上问题就叫做伪共享(false sharing)问题。为了解决伪共享问题,我们可以使用@Contended注解。这个注解既可以标记在类上,也可以标记在变量上。标记在类上会强制这个类的对象独占一个缓存行,不够一个缓存行的会做对齐填充。标记在变量上会强制这个变量独占一个缓存行。Cell类使用@Contended标记,两个Cell对象便不会存储在同一个缓存行中,因此,也就不会出现伪共享的问题了。缓存不再频繁失效,执行效率变高。
五、非准确求和
前面我们提到,LongAdder中的sum()函数会累加base和cells中的Cell对象的value值,从而得到最终的累加值。但是,这个值是不准确的,或者说不一致的。这是为什么呢?我们先来看下sum()函数的源码,如下所示。
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
从代码中,我们可以发现,LongAdder在执行sum()函数时,并没有加锁,也就是说,在执行sum()函数的同时,其他线程可以同时执行add()函数。这就会导致出现这样的情况:前面添加的值没有算到累加值中,反倒是后面添加的值算到了累加值中。如下图所示 。
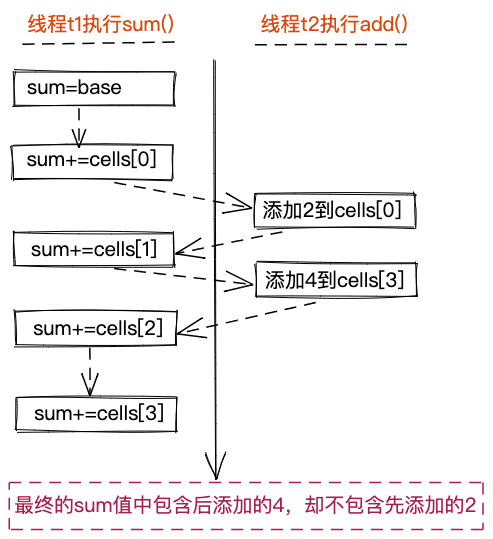
实际上,除了LongAdder之外,JUC还提供了另外三个功能类似的类:LongAccumulator、DoubleAdder、DoubleAccumulator,其中,DoubleAdder和DoubleAccumulator跟LongAdder和LongAccumulator的区别,仅仅只是处理的数据类型不同而已。因此,我们重点看下LongAccumulator。
从前面的讲解,我们可以发现,LongAdder只能实现累加操作,而LongAccumulator却可以实现更加丰富的统计操作,比如求最大值。LongAccumulator类的部分源码如下所示。
@FunctionalInterface
public interface LongBinaryOperator {
long applyAsLong(long left, long right);
}
public class LongAccumulator extends Striped64 {
private final LongBinaryOperator function;
private final long identity;
public LongAccumulator(LongBinaryOperator accumulatorFunction,
long identity) {
this.function = accumulatorFunction;
base = this.identity = identity;
}
public void accumulate(long x) { //相当于LongAdder中的add()
Cell[] as; long b, v, r; int m; Cell a;
if ((as = cells) != null ||
(r = function.applyAsLong(b = base, x)) != b && !casBase(b, r)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended =
(r = function.applyAsLong(v = a.value, x)) == v ||
a.cas(v, r)))
longAccumulate(x, function, uncontended);
}
}
public long get() { //相当于LongAdder中的sum()
Cell[] as = cells; Cell a;
long result = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
result = function.applyAsLong(result, a.value);
}
}
return result;
}
}
从代码实现,我们可以发现,LongAccumulator的代码实现,跟LongAdder的代码实现非常相似,主要区别在于,LongAccumulator支持不同的统计操作。如下示例代码所示,我们通过定义实现了LongBinaryOperator接口的类LongMax,然后通过构造函数传入LongAccumulator对象,便可以支持取最大值的操作。
public class Demo {
public static class LongMax implements LongBinaryOperator {
@Override
public long applyAsLong(long left, long right) {
return Math.max(left, right);
}
}
public static void main(String[] args) {
LongAccumulator lacc = new LongAccumulator(new LongMax(), Long.MIN_VALUE);
lacc.accumulate(10);
lacc.accumulate(-18);
lacc.accumulate(24);
System.out.println(lacc.get()); //输出24
}
}
六、思考题
如果我们希望LongAdder的sum()函数能给出准确、一致的累加和,该如何对LongAdder的代码进行改造?改造之后的代码对性能又有什么影响?