原子类
原子类
提示
原子类:请举例说明CAS的ABA问题是如何产生的以及如何解决?
上一节,我们讲到多线程开发中的基础中的基础:CAS。自旋+CAS可以替代锁用于资源竞争不激烈的场景。不过,相对于锁来说,自旋+CAS的代码实现比较复杂。我们需要先创建Unsafe对象,然后获取待更新变量的偏移位置,最后调用Unsafe对象的CAS方法来更新变量。为了方便开发,JUC提供了各种原子类,封装了对各种类型数据的自旋+CAS操作。这样我们拿来直接使用即可。本节,我们就来讲解一下这些原子类,同时,借此加深对自旋+CAS的理解。
一、原子类概述
原子类主要依赖自旋+CAS来实现。原子类中的每个操作都是原子操作。在多线程环境下,执行原子类中的操作不会出现线程安全问题。根据处理的数据类型,原子类可以粗略地分为4类:基本类型原子类、引用类型原子类、数组类型原子类、对象属性原子类。每类原子类包含的具体类如下图所示。
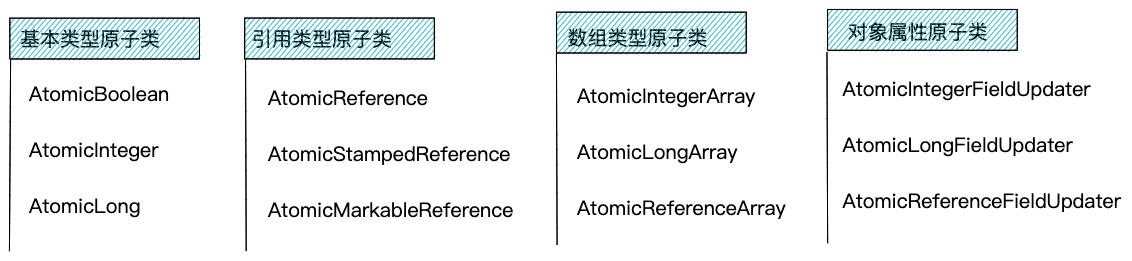
对于以上四种原子类,我们重点讲解比较常用的基本类型原子类和引用类型原子类,对于数组类型原子类和对象属性原子类,我们只做简单介绍。
二、基本类型原子类
JUC提供了3个基本类型原子类,它们分别是:AtomicBoolean、AtomicInteger、AtomicLong。因为浮点数无法精确表示和比较大小,所以,JUC并没有提供浮点类型的原子类。除此之外,对于char基本类型,我们需要将其转化为为int类型,进而使用AtomicInteger来进行原子操作。
AtomicBoolean、AtomicInteger、AtomicLong这3个基本类型原子类的使用方法和实现原理非常相似,我们拿AtomicInteger举例讲解。AtomicInteger类的部分源码如下所示。AtomicInteger类中包含的核心的原子操作暂时未给出,待会一一讲解。
public class AtomicInteger {
private volatile int value;
// 创建Unsafe对象,获取value变量在AtomicInteger对象中的偏移位置
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// 构造函数
public AtomicInteger(int initialValue) { value = initialValue; }
public AtomicInteger() {} //默认value值为0
// 基本的getter、setter方法
public final int get() { return value; }
public final void set(int newValue) { value = newValue; }
//...省略核心原子操作....
}
接下来,我们重点讲解一下AtomicInteger提供的4类核心原子操作:CAS、增加、自增、自减。
1)CAS函数
AtomicInteger中的compareAndSet()是标准的CAS函数。如下代码所示,如果value值等于入参expect值,那么就将value值更新为入参update值,并返回true。compareAndSet()函数底层调用Unsafe类的CAS方法compareAndSwapInt()来实现,此方法在上一节中已经详细讲解,这里就不再赘述了。
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
2)增加函数
增加函数有两个。从命名上,我们也可以大概猜出两者的不同之处。其中,getAndAdd()函数先获取value值,再更新value,函数返回更新前的旧值,addAndGet()函数先更新value,再获取value值,函数返回更新之后的新值。
public final int getAndAdd(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta);
}
public final int addAndGet(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}
两个函数的代码实现非常相似,addAndGet()函数只不过是在getAndAdd()返回值的基础之上,加了一个delta再返回而已。因此,我们重点看下getAndAdd()函数。getAndAdd()函数调用Unsafe类的getAndAddInt()方法来实现。getAndAddInt()方法的代码实现如下所示。
public final int getAndAddInt(Object o, long offset, int delta) {
int oldValue;
do { // 自旋+CAS
oldValue = this.getIntVolatile(o, offset); //调用Unsafe类的native方法
} while(!this.compareAndSwapInt(o, offset, oldValue, oldValue+delta));
return oldValue;
}
getAndAddInt()并非native方法,而是直接由Java代码实现,其底层调用Unsafe类的CAS方法compareAndSwapInt()来实现。在多线程竞争执行时,CAS有可能执行失败,因此,getAndAddInt()采用自旋重复执行CAS,直到成功为止。这样就可以保证getAndAddInt()总是可以将value值增加delta。
3)自增函数
自增函数也有两个。用法跟增加函数类似,getAndIncrement()函数返回自增之前的旧值,incrementAndGet()函数返回自增之后的新值。底层实现原理也跟增加函数类似,只需要将增加函数中的delta设置为1即可。
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
4)自减函数
自减函数也有两个。用法跟自增函数类似,getAndDecrement()函数返回自减之前的旧值,decrementAndGet()函数返回自减之后的新值。底层实现原理跟增加函数类似,只需要将增加函数中的delta设置为-1即可。
public final int getAndDecrement() {
return unsafe.getAndAddInt(this, valueOffset, -1);
}
public final int decrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, -1) - 1;
}
从功能上,AtomicInteger提供的增加函数,完全可以替代自增函数和自减函数。AtomicInteger类提供冗余的自增函数和自减函数,完全是为了方便程序员使用。
三、引用类型原子类
基本类型原子类提供了操作基本类型数据的原子函数,同理,引用类型原子类提供了操作引用类型数据的原子函数。JUC提供了3个引用类型原子类,它们分别是:AtomicReference、AtomicStampedReference、AtomicMarkableReference。接下来,我们一一详细讲解这3个引用类型原子类的用法和实现原理。
1)AtomicReference
AtomicReference类的部分源码如下所示。基本类型原子类主要依赖Unsafe类中的compareAndSwapInt()和compareAndSwapLong()这两个CAS方法来实现。引用类型原子类主要依赖Unsafe类中的compareAndSwapObject()这个CAS方法来实现。AtomicReference的实现方式跟AtomicInteger类似,这里就不再赘述了。
public class AtomicReference<V> {
private volatile V value;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicReference.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
public AtomicReference(V initialValue) { value = initialValue; }
public AtomicReference() {}
public final V get() { return value; }
public final void set(V newValue) { value = newValue; }
public final boolean compareAndSet(V expect, V update) {
return unsafe.compareAndSwapObject(this, valueOffset, expect, update);
}
}
AtomicReference类的使用方式,如下示例代码所示。
public class DemoLock {
private AtomicReference<Thread> owner = null;
public boolean tryAcquire() {
return owner.compareAndSet(null, Thread.currentThread());
}
}
2)AtomicStampedReference
相对于AtomicReference,AtomicStampedReference增加了版本戳,主要是用来解决CAS的ABA问题。什么是CAS的ABA问题呢?我们举例解释一下。如下代码所示,addAtHead()函数往链表头部添加节点,removeAtHead()函数从链表头部移除节点。你觉得下面的代码是否是线程安全的呢?
public class Node {
private char val;
private Node next;
public Node(int val, Node next) {
this.val = val;
this.next = next;
}
}
public class LinkedList {
private Node head = null;
public void addAtHead(Node newNode) {
newNode.next = head;
head = newNode;
}
public void removeAtHead() {
if (head != null) {
head = head.next;
// 上述语句相当于以下两个语句:
// Node tmp = head.next;
// head = tmp;
}
}
}
实际上,LinkedList是非线程安全的,我们分3种情况来分析一下。
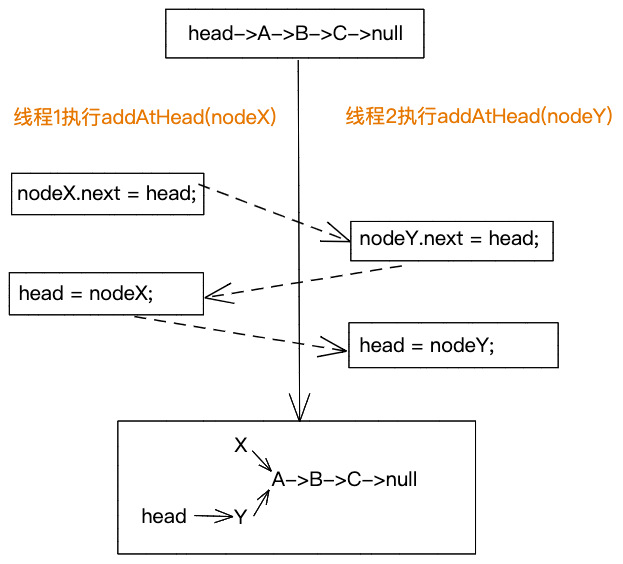
1)两个线程竞争交叉执行addAtHead()函数,有可能会导致节点无法正常添加,如下图所示。
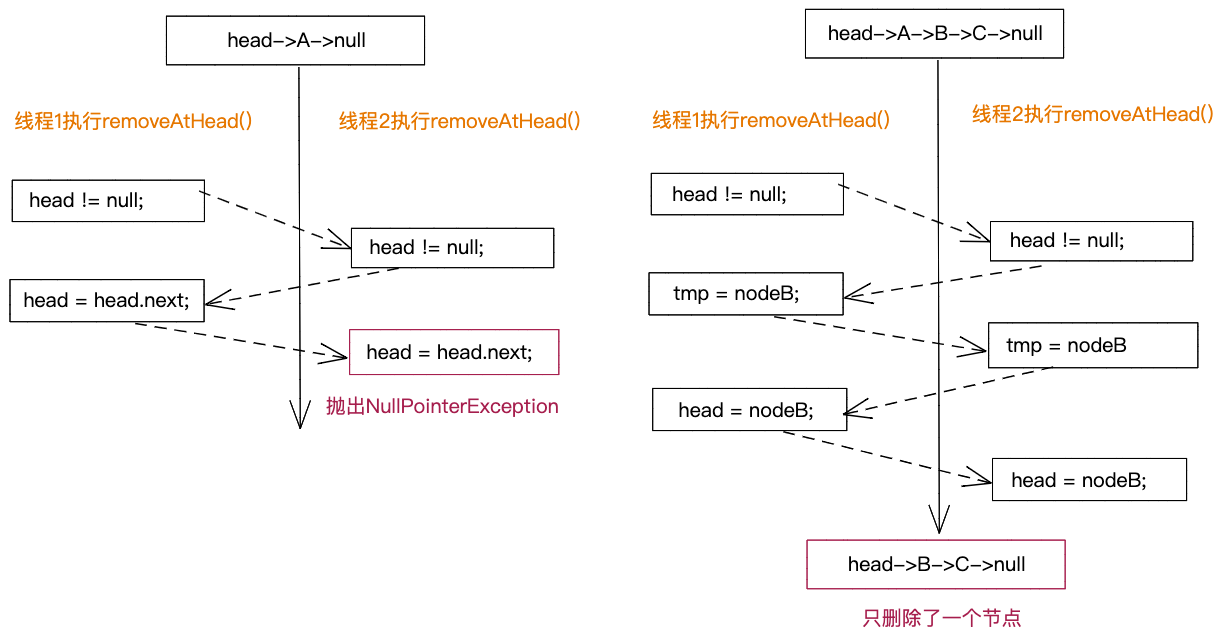
2)两个线程竞争交叉执行removeAtHead()函数,有可能会导致NullPointerException异常,或者节点无法正常移除,如下图所示。
3)两个线程竞争交叉执行addAtHead()函数和removeAtHead()函数,有可能导致节点无法正常移除,或者节点无法正常添加,如下图所示。
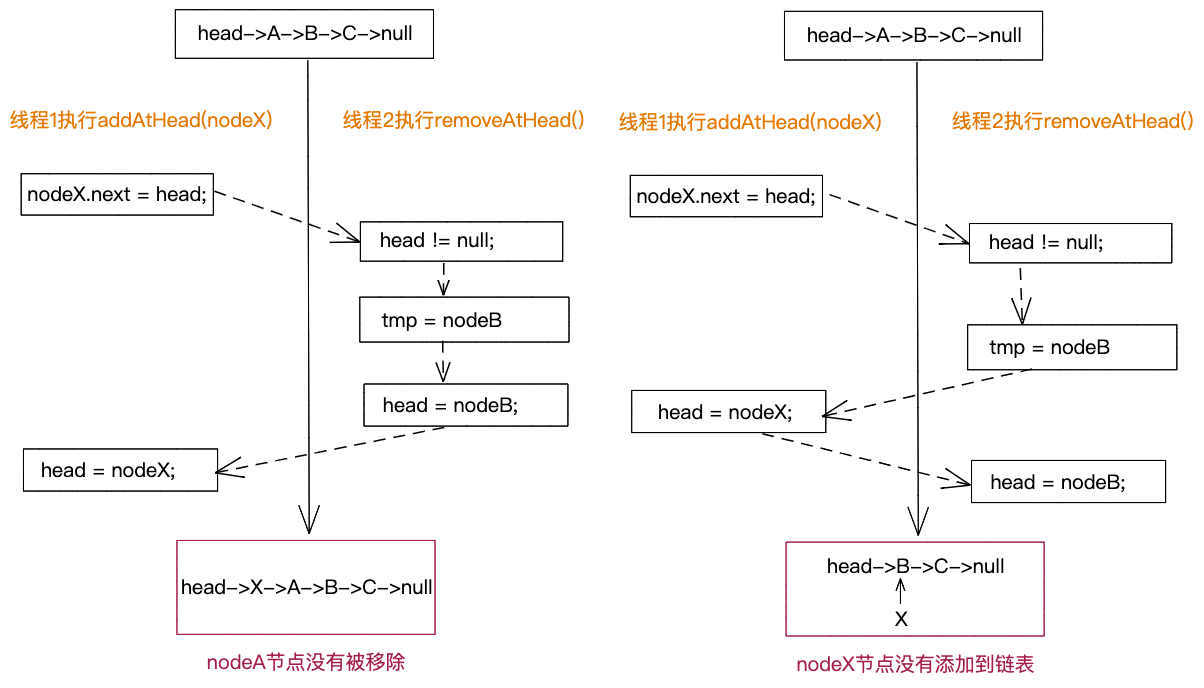
实际上,不管是addAtHead(),还是removeAtHead(),线程不安全的本质原因是:在更新head时,head有可能已经被其他线程更改。为了解决LinkedList的线程安全问题,我们既可以基于synchronized或Lock锁来解决,也可以基于自旋+CAS来解决。基于锁的解决方案比较简单,这里就留给你自己思考。我们重点来看下基于自旋+CAS的解决方案。代码实现如下所示。在更新head时,我们通过CAS确保head没有被其他线程更新过。
public class LinkedListThreadSafe {
private AtomicReference<Node> head = new AtomicReference<>(null);
public void addAtHead(Node newNode) {
boolean succeeded = false;;
while (!succeeded) {
Node oldHead = head.get();
newNode.next = oldHead;
succeeded = head.compareAndSet(oldHead, newNode);
}
}
public void removeAtHead() {
boolean succeeded = false;;
while (!succeeded) {
Node oldHead = head.get();
if (oldHead == null) return;
Node nextNode = oldHead.next;
succeeded = head.compareAndSet(oldHead, nextNode);
}
}
}
不过,以上代码实现仍然存在问题。如下图所示。线程1执行了一次removeAtHead()函数,线程2执行了两次removeAtHead()函数和一次addAtHead()函数,因此,链表中的节点个数最终应该是1,但实际的运行结果却是2。这是为什么呢?
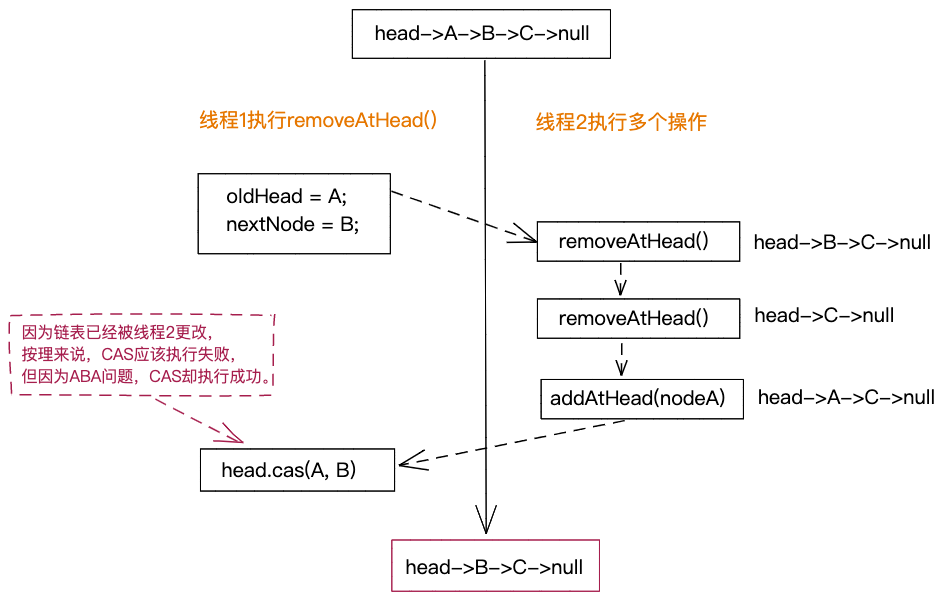
实际上,引起执行结果出错的原因,就是CAS的ABA问题。线程1执行removeAtHead()函数,设置oldHead=A、nextNode=B,在执行CAS之前,线程2将head从A变为B、C,最后又变为A。尽管线程2执行完之后,head仍为A,但链表的整体结构发生了变化。随后,当线程1执行CAS时,检查当前的head跟oldHead相等,仍然是A,错以为期间没有其他线程执行addAtHead()和removeAtHead()函数,于是,成功执行CAS。
为了解决以上ABA问题,我们使用AtomicStampedReference对LinkedList进行改造,如下代码所示。
public class LinkedList {
private AtomicStampedReference<Node> head
= new AtomicStampedReference<>(null, 0); // stamp初始值为0
public void addAtHead(Node newNode) {
boolean succeeded = false;;
while (!succeeded) {
int oldStamp = head.getStamp();
Node oldHead = head.getReference();
newNode.next = oldHead;
succeeded = head.compareAndSet(oldHead, newNode, oldStamp, oldStamp+1);
}
}
public void removeAtHead() {
boolean succeeded = false;;
while (!succeeded) {
int oldStamp = head.getStamp();
Node oldHead = head.getReference();
if (oldHead == null) return;
Node nextNode = oldHead.next;
succeeded = head.compareAndSet(oldHead, nextNode, oldStamp, oldStamp+1);
}
}
}
AtomicStampedReference的部分源码如下所示。相对于AtomicReference,AtomicStampedReference增加了一个int类型stamp版本戳,它将stamp和引用对象reference(例如head)封装成一个新的Pair对象,在Pair对象上执行CAS。即便引用对象存在ABA问题,但是stamp总是在增加,stamp不会存在ABA问题,因此,两者组合而成的Pair对象,也不就不存在ABA问题了。
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
public AtomicStampedReference(V initialRef, int initialStamp) {
pair = Pair.of(initialRef, initialStamp);
}
public boolean compareAndSet(V expectedReference, V newReference,
int expectedStamp, int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
casPair(current, Pair.of(newReference, newStamp)));
}
private boolean casPair(Pair<V> cmp, Pair<V> val) {
return unsafe.compareAndSwapObject(this, pairOffset, cmp, val);
}
}
3)AtomicMarkableReference
AtomicMarkableReference跟AtomicStampedReference的作用相同,也是用来解决AtomicReference存在的ABA问题。区别在于,AtomicStampedReference使用int类型的stamp版本戳是否改变,来判断reference是否有被更改过,AtomicMarkableReference使用boolean类型的mark是否改变(true变成false或false变成true),来判断reference是否有被更改过。AtomicMarkableReference的用法和实现原理跟AtomicStampedReference非常相似,这里就不再赘述了。
四、数组类型原子类
JUC提供了3个数组类型原子类,它们分别是:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray。这3个类的使用方式和实现原理非常类似,我们拿AtomicIntegerArray举例讲解。
实际上,AtomicIntegerArray中的原子操作,跟AtomicInteger中的原子操作一一对应,只是在操作中多了一个下标而已。我们拿CAS操作来举例。两个类中的CAS函数对比如下所示。AtomicIntegerArray中的CAS函数,也是用来Unsafe中的compareAndSwapInt()来实现的,只不过计算元素的偏移位置比较复杂而已。
// AtomicInteger
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
// AtomicIntegerArray
public final boolean compareAndSet(int i, int expect, int update) {
return unsafe.compareAndSwapInt(array, checkedByteOffset(i), expect, update);
}
五、对象属性原子类
JUC提供了3个对象属性原子类,它们分别是:AtomicIntegerFiledUpdater、AtomicLongFieldUpdater、AtomicReferenceFiledUpdater。如果某个类中的属性没有提供合适的原子操作,那么我们可以使用对象属性原子类来对其进行原子操作。不过,允许这样做的前提是:属性必须是public的。
因为对象属性原子类很少用到,所以,我们仅仅举例简单介绍一下,不做深入分析。
public class Updater {
private static AtomicIntegerFieldUpdater<Node> updater =
AtomicIntegerFieldUpdater.newUpdater(Node.class, "val");
public static void incrementVal(Node node) {
updater.incrementAndGet(node);
}
}
六、课后思考题
对于AtomicInteger类中的getAndAdd()函数,如果我们不使用CAS来实现,那么,如下代码实现方式,是否是线程安全的?为什么呢?
public final int getAndAdd(int delta) {
int oldValue = value;
value += delta;
return oldValue;
}