异常(上)
异常(上)
在项目开发中如何正确的定义、处理、记录异常
异常是Java语言提供的一种出错处理机制。在Java编程中,我们时刻都离不开异常,在编写正常逻辑代码的同时,总是需要编写处理各种异常情况的逻辑代码。尽管异常语法比较简单,但用好并不容易。不合理的使用异常会导致诸多问题,比如程序变慢,异常信息丢失。所以,本节,我们就重点讲下如何合理的使用异常。下一节,我们会深入到异常的内部原理,讲解异常捕获太多导致程序变慢的核心原因。
一、异常使用
C语言中没有异常这样的语法机制,因此,返回错误码便是最常用的出错处理方式。而在Java、Python等比较新的编程语言中,都引入了异常语法。大部分情况下,我们都是使用异常来处理函数出错的情况,极少会用到错误码。异常相对于错误码,有诸多方面的优势,比如可以携带更多的错误信息(exception中可以有message、stack trace等信息)等。除此之外,异常可以将正常业务代码和异常处理代码分离,这样,代码的可读性就会更好。
我们先简单介绍一下如何使用异常。
异常关键词有这样几个:throw、throws、try、catch、finally。throw用来抛出异常,throws用来在方法定义中声明方法可能抛出的异常。try用来标记需要监控异常的代码,catch用来捕获代码抛出的异常并进行处理,finally用来兜底,只要try标记的代码块被执行,不管有没有抛出异常,finally中的代码都会被执行。finally代码块一般用来做清理工作,比如关闭打开的文件等。异常使用的示例代码如下所示。
public byte[] readData(String filePath) throws DataReadException {
InputStream in = null;
try {
in = new FileInputStream(filePath);
byte[] data = new byte[in.available()];
in.read(data);
return data;
} catch (FileNotFoundException e) {
// DataReadException是自定义异常,待会会讲解
throw new DataReadException("File not found: " + filePath, e);
} catch (IOException e) {
throw new DataReadException("Failed to read: " + filePath, e);
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
//使用日志框架记录日志
}
}
}
}
如上代码所示,try代码块之后,可以有多个catch代码块,用来捕获try代码块在执行时抛出的不同异常。需要注意的是,异常的捕获顺序应该是先捕获子类异常,再捕获父类异常,否则,捕获子类异常的代码块将不会执行。如上代码所示,IOException是FileNotFoundException的父类,如果先捕获IOException异常,再捕获FileNotFoundException异常,那么代码抛出的FileNotFoundException异常会被当做IOException异常被捕获。
除了以上基本用法之外,JDK7还为异常引入了一些新的特性。如下示例代码所示,catch可以一次性捕获多个异常。除此之外,对于实现了java.lang.AutoClosable接口的资源类,我们可以使用try-with-resources语句来创建资源类对象,try代码块执行完成之后,对应的资源会自动被关闭,不再需要调用finally语句来显式地关闭资源,避免了程序员忘记关闭资源而造成的资源泄露。这两个新特性的示例代码如下所示。
public void readData(String filePath) throws DataReadException {
try (InputStream in = new FileInputStream(filePath)) {
Thread.sleep(10);
...
} catch (FileNotFoundException | InterruptedException e) {
...
} catch (IOException e) {
throw new DataReadException("Failed to read: " + filePath, e);
}
}
二、异常体系
Java中定义了很多现成的异常(叫做内建异常),这些异常又分属不同类别,不同类别的异常具有不同的特点。整个Java的异常体系(类图)如下图所示。
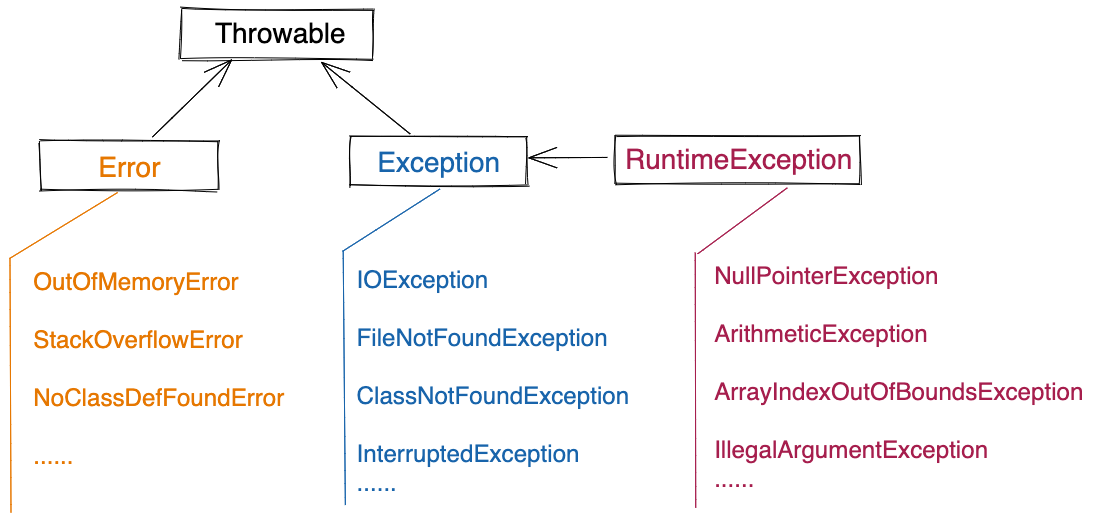
Throwable是所有异常的父类。Throwable包含两个子类:Error和Exception。Exception又派生了一个子类RuntimeException。所有内建Java异常可以分为3类:继承自Error的异常、继承自Exception的异常、继承自RuntimeException的异常。
其中,继承自的Error的异常,是一种比较特殊的异常,用来表示程序无法处理的严重错误,这些错误有可能导致线程或JVM终止,比如OutOfMemoryError、StackOverflowError、NoClassDefFoundError等。
继承自Exception的异常叫做受检异常(Checked Exception)或编译时异常(Compile Exception),比如IOException、FileNotFoundException、InterruptedException等。在编写代码的时候,我们需要主动去捕获或者在函数定义中声明此类异常,否则编译就会报错。
继承自RuntimeException的异常叫做非受检异常(Unchecked Exception)或者运行时异常(Runtime Exception),比如NullPointerException、ArithmeticException、ArrayIndexOutOfBoundsException等。跟编译时异常相反,在编写代码的时候,我们可以不主动去捕获和在函数定义中声明此类异常。编译器在编译代码时,并不会检查代码是否有对运行时异常做了处理。
三、自定义异常
在平时的开发中,我们尽量使用Java已经提供的内建异常,在不满足业务需求的情况下,比如,对于用户不存在这一异常情况,没有对应的内建异常,我们就需要自定义异常。如下代码所示,我们定义了UserNotExistingException异常,用来更加准确地描述异常发生的情况。
public class UserNotExistingException extends Exception {
public UserNotExistingException() {
super();
}
public UserNotExistingException(String msg, Throwable cause) {
super(msg, cause);
}
public UserNotExistingException(String msg) {
super(msg);
}
public UserNotExistingException(Throwable cause) {
super(cause);
}
}
自定义异常跟大多数内建异常一样,要么作为受检异常继承自Exception,要么作为非受检异常继承自RuntimeException。那么,在定义某个异常时,我们应该选择让其继承自Exception呢?还是应该选择让其继承自RuntimeException呢?
对于代码bug(比如数组越界)以及不可恢复异常(比如数据库连接失败),即便我们捕获了,也做不了太多事情,所以,我们倾向于使用非受检异常。对于可恢复异常、业务异常、预期可能发生的异常,比如提现金额大于余额的异常,我们更倾向于使用受检异常,明确告知调用者需要捕获处理。
不过,现在我们几乎都是依赖框架来编程,业务逻辑运行在框架中,对于程序员自定义的异常,不管是受检异常还是非受检异常,大部分情况下,都会被框架兜底捕获并处理,并不会直接导致程序的终止。从这个角度上来讲,在编写业务代码时自定义的异常,定义成受检异常和非受检异常均可。
实际上,Java支持的受检异常一直被人诟病。有些人主张所有的异常情况都应该使用非受检异常。支持这种观点的理由主要有以下三个。
1)受检异常需要显式地在函数定义中声明。如果函数的代码逻辑有可能抛出很多受检异常,那么函数定义会非常冗长,这就会影响代码的可读性,而且函数使用起来也不方便。示例函数如下所示。
public long buy() throws UserNotFoundException,
UserHasNoEnoughMoneyException,
DuplicatedBuyException,
NoEnoughNotesException,
UserHasNoPermissionToBuyException;
2)编译器强制程序必须显示地捕获所有的受检异常,代码实现会比较繁琐。当使用如上示例函数时,我们需要显示的捕获各个异常或者在函数定义中重复声明。而非受检异常正好相反,我们不需要在定义中显示声明,并且是否需要捕获处理,也可以自由决定。
3)受检异常的使用违反开闭原则。如果我们给某个函数新增一个受检异常,这个函数所在的函数调用链上的所有位于其之上的函数,都需要做相应的代码修改,直到调用链中的某个函数,将这个新增的异常,捕获处理不再抛出为止。相反,新增非受检异常可以不改动调用链上的代码。我们可以灵活地选择在某个函数中集中处理,比如在Spring中的AOP切面中集中处理异常。
不过,非受检异常也有弊端,它的优点其实也正是它的缺点。从刚刚的表述中,我们可以看出,非受检异常使用起来更加灵活,怎么处理异常的主动权交给了程序员。过于灵活会带来不可控,非受检异常不需要显式地在函数定义中声明,那么在使用函数时,我们就需要查看函数的实现逻辑,才能知道函数具体会抛出哪些异常。因为非受检异常不需要强制捕获处理,那么一些本应该捕获处理的异常就有可能被程序员遗漏。
对于应该用受检异常还是非受检异常,争论有很多,但并没有一个非常强有力的理由能够说明一个就一定比另一个更好。所以,我们只需要根据团队的开发习惯,在同一个项目中,制定统一的异常处理规范即可。
四、异常处理
当某段程序抛出异常时,我们应该如何处理抛出的异常呢?一般来讲,我们有3种处理方法。
1)捕获后记录日志
public void f() throws LowLevelException { ... }
public void g() {
try {
f();
} catch(LowLevelException e) {
log.warn("...", e); //使用日志框架记录日志
}
}
2)原封不动再抛出
public void f() throws LowLevelException { ... }
//如果LowLevelException是非受检异常,则不需要在函数g()定义中声明
public void g() throws LowLevelException {
f();
}
3)包装成新异常抛出
public void f() throws LowLevelException { ... }
public void g() {
try {
f();
} catch(LowLevelException e) {
throw new HighLevelException("...", e);
}
}
以上我们介绍了3种处理异常的方法,那么,当代码抛出异常时,我们应该选择哪一种来处理方法呢?很多程序员对处理方式的选择比较随意,也没有一个原则。实际上,选择哪种处理方法,其实有一个简单的原则可以参考,那就是:函数只抛出跟函数所涉及业务相关的异常。
在函数内部,如果某块代码的异常行为,并不会导致调用此函数的上层代码出现异常行为,也就是说,上层代码并不关心被调用函数内部的这个异常,我们就可以在函数内部将这个异常“消化掉”:将其捕获并打印日志记录。相反,如果函数内部的异常行为会导致调用此函数的上层代码出现异常行为,那么,我们就必须让上层代码感知到此异常的存在。如果此异常跟函数的业务相关,上层代码在调用此函数时,知道如何处理此异常,那么直接将其抛出就可。如果此异常跟函数的业务无关,上层代码无法理解这个异常的含义,不知道如何处理,那么需要将其包裹成新的跟函数业务相关的异常重新抛出。
我们再来看本节开头的示例代码,对此我稍微做了修改,如下所示。
public byte[] readData(String filePath) throws DataReadException,FileNotFoundException {
InputStream in = null;
try {
Thread.sleep(10);
in = new FileInputStream(filePath);
byte[] data = new byte[in.available()];
in.read(data);
return data;
} catch (InterruptedException e) {
throw new DataReadException("Interrupted when reading: " + filePath, e);
} catch (IOException e) {
throw new DataReadException("Failed to read: " + filePath, e);
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e) {
//使用日志框架记录日志
}
}
}
}
参照刚刚给出的3种异常处理方式,以及选择的原则,我们来分析一下上面的代码。
1)调用readData()函数的上层代码并不关心文件关闭失败(对应in.close()语句)导致的IOException异常,因此,我们直接将其捕获并打印日志。
2)对于文件读取失败而抛出的IOException异常,因为IOException异常比较底层,如果原封不动抛出,那么上层代码可能并不知道如何处理,所以,我们将其重新包裹成自定义的DataReadException异常再抛出。
3)同理,对于因sleep()函数被中断而抛出的InterruptedException异常,上层代码也无法理解,因此,我们同样将其包裹为DataReadException异常再抛出。
4)对于文件打开失败而抛出的FileNotFoundException异常,因为跟readData()函数业务相关,毕竟readData()函数中的参数就是文件的路径,所以,我们可以直接将其抛出。当然,如果我们想要减少readData()函数受检异常的个数,那么也可以将FileNotFoundException异常统一包裹为DataReadException异常再抛出。
五、异常调用链
异常最终的宿命终究是被捕获并打印异常信息,以便程序员debug问题,比如将其打印到日志或命令行中。为了给程序员展示充足的异常信息,我们一般需要将异常调用链完整打印出来。
异常调用链记录了异常引起的整个过程,当前被捕获的异常是由哪个异常引起的,跟函数调用一样,一直追溯到引起整个异常调用链的最原始的异常为止。除此之外,异常调用链还会记录每个异常的生命周期内所经历的所有函数。异常的生命周期指的是,异常从创建到被捕获并不再继续抛出的这一过程。
我们举个例子来看下,如下代码所示。
public class Demo17_1 {
public static class LowLevelException extends Exception {
public LowLevelException() { super(); }
public LowLevelException(String msg, Throwable cause) { super(msg, cause); }
public LowLevelException(String msg) { super(msg); }
public LowLevelException(Throwable cause) { super(cause); }
}
public static class MidLevelException extends Exception {
//...与LowLevelException实现类似,省略代码实现...
}
public static class HighLevelException extends RuntimeException {
//...与LowLevelException实现类似,省略代码实现...
}
public static void fa() throws LowLevelException {
throw new LowLevelException("LowLevelException-msg");
}
public static void fb() throws LowLevelException {
fa();
}
public static void fc() throws MidLevelException {
try {
fb();
} catch (LowLevelException e) {
throw new MidLevelException("MidLevelException-msg", e);
}
}
public static void fd() {
try {
fc();
} catch (MidLevelException e) {
throw new HighLevelException("HighLevelException-msg", e);
}
}
public static void fe() {
fd();
}
public static void main(String[] args) {
try {
fe();
} catch(HighLevelException e) {
e.printStackTrace();
}
}
}
我们分析一下上述代码。
1)LowLevelException异常为调用链中的第一个异常,在fa()函数中抛出,fb()未捕获直接将其抛出,fc()将其捕获并且重新包装成MidLevelException异常抛出,所以,LowLevelException异常的生命周期经历了3个函数:fa()、fb()、fc()。
2)MidLevelException异常在fc()函数中创建,在fd()函数中被捕获,然后重新包装成HighLevelException异常抛出,所以,MidLevelException()异常的生命周期经历了2个函数:fc()和fd()。
3)HighLevelException异常为运行时异常,在fd()函数中创建,fe()函数没有将其捕获,默认原样抛出,最终被main()函数捕获并输出异常调用链信息,至此异常调用链结束。所以,HighLevelException异常的生命周期经历了3个函数:fd()、fe()、main()。
HighLevelException异常由MidLevelException异常引起,MidLevelException异常又由LowLevelException异常引起,因此,上述代码打印出来的异常调用链,如下所示。
demo.Demo17_1$HighLevelException: HighLevelException-msg
at demo.Demo17_1.fd(Demo17_1.java:53)
at demo.Demo17_1.fe(Demo17_1.java:58)
at demo.Demo17_1.main(Demo17_1.java:27)
Caused by: demo.Demo17_1$MidLevelException: MidLevelException-msg
at demo.Demo17_1.fc(Demo17_1.java:45)
at demo.Demo17_1.fd(Demo17_1.java:51)
... 2 more
Caused by: demo.Demo17_1$LowLevelException: LowLevelException-msg
at demo.Demo17_1.fa(Demo17_1.java:34)
at demo.Demo17_1.fb(Demo17_1.java:38)
at demo.Demo17_1.fc(Demo17_1.java:43)
... 3 more
异常调用链可以完整的描述异常发生的整个过程。但需要特别注意的是,捕获异常并包裹成新的异常抛出时,我们一定要将先前的异常通过cause参数传递进新的异常,否则,异常调用链将会断开。比如,对于上述示例代码,在创建MidLevelException异常时,如果我们没有将LowLevelException异常通过cause参数传递给MidLevelException,那么,通过MidLevelException异常将无法再追踪到LowLevelException异常。最终打印出来的异常调用链将只包含HighLevelException异常信息和MidLevelException异常信息。
//错误做法
try {
...
} catch (CausedByException e) {
throw new NewException("msg..."); // e丢失
}
//正确的做法
try {
...
} catch (CausedByException e) {
throw new NewException("msg...", e);
}
在平时的开发中,我们还需要特别注意,对于异常的处理,要么记录,要么抛出,但两者不能同时执行。错误的做法如下所示。在异常调用链中,我们只需要在最后一个异常生命周期结束时,打印异常调用链即可,没必要像如下所示,重复打印部分异常调用链。既然我们已经抛出了异常,异常就理应由上层函数来负责处理(比如打印)。
//错误的做法
try {
...
} catch (CausedByException e) {
logger.error("...", e);
throw new NewException("msg...", e);
}
六、课后思考题
在本节打印的异常调用栈信息中,“...2 more”和“...3 more”具体指的是什么内容?