原子类
原子类
提示
Java代码的执行效率真的比C++等编译型语言低吗?
从本节开始,我们进入专栏的JVM模块。JVM模块分四部分讲解,它们分别是:编译执行、内存模型、垃圾回收、JVM实战。
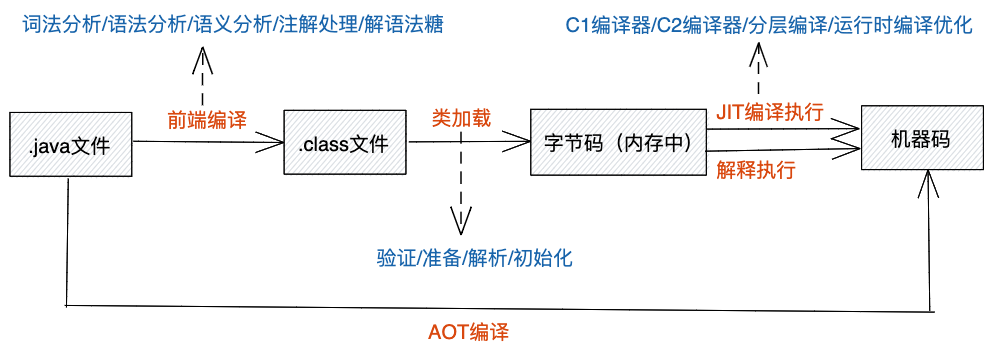
在专栏的第一节中,我们讲到,高级语言可以粗略的分为三类:编译型语言、解释型语言、混合型语言,其中,Java属于混合型语言。混合型语言也叫做半解释型语言,它融合了编译型语言和解释型语言的特点,既兼顾了可移植性,又兼顾了执行效率。本节,我们就先粗略介绍一下Java的编译执行的整个过程,其中就包括前端编译、类加载、解释执行、JIT编译执行、AOT编译这5部分内容。在后面的几节中,我们对其中较复杂的类加载、JIT编译再进行详细讲解。
我们经常听说,Java语言的执行效率没有C/C++语言高,为什么这么说呢?这样的说法是否是事实呢?带着这些问题,我们开始今天的学习。
一、前端编译
前端编译指的是将.java文件编译成.class文件(字节码)的过程,由javac编译器来完成。之所以叫前端编译,主要是为了跟JIT编译作区分。实际上,前端编译的过程跟编译型语言中编译的过程类似,它们都需要经过词法分析、语法分析、语义分析等经典的编译过程。两者的区别在于,Java前端编译的结果为字节码,编译型语言中的编译结果为机器码。除此之外,Java前端编译还做了一些特殊的工作:注解处理和解语法糖。接下来,我们重点看下注解处理和解语法糖,对于词法分析、语法分析、语义分析,它们属于编译原理中所讲的内容,这里我们就不再展开深入讲解,你可以查看编译原理书籍来了解。
1)注解处理
从JDK6开始,javac编译器开始支持JSR269(Pluggable Annotation Processing API)规范。我们只需要按照这个规范来开发注解插件(插件包含定义注解、使用注解、以及对应的注解处理器三部分内容),那么,javac编译器在执行前端编译时,就会调用注解插件执行相应的注解处理器代码。
我们在开发中经常用到的Lombook插件,便是按照JSR269规范开发的注解插件。在编译代码时,javac编译器会调用Lombook插件的注解处理器,注解处理器根据@getter、@setter等注解,为类、成员变量生成getter、setter等方法。Lombook插件中定义的注解大部分都是SOURCE级别的,也就是只存在于源码中。当代码编译成字节码之后,这些注解便没有存在的意义了。毕竟JVM并不关心getter、setter方法来自于程序员手敲,还是Lombook注解。
2)解语法糖
Java作为一种高级语言,从一开始就特别重视开发效率(易用),而非一味追求执行效率(性能)。这跟C/C++语言正好相反,这也是两类语言使用场景的重要区别依据。Java更适合做业务系统开发,C/C++语言更适合偏底层的系统级开发。
Java为了提高开发效率,提供了很多语法糖。所谓语法糖,指的是对已经存在的基本语法的二次封装,目的是提高易用性,比如泛型、自动装箱拆箱、for-each遍历、内部类等等都是语法糖。在执行前端编译时,编译器会将语法糖解封装为基本语法。也就是说,字节码并不包含语法糖,JVM也不会感知到语法糖。语法糖仅存在于源码中。
接下来,我们依次来看下这些语法糖。
对于泛型来说,泛型只存在于源码中,在编译时会进行类型擦除,也就是说,List<Integer>和List<String>在字节码中都是List,里面存储的是Object类型的数据,字节码中并不存在使用两个尖括号指定类型的语法。泛型中的类型仅仅是编译器做类型检查所用。这也是Java中的泛型被称为伪泛型的原因。
自动装箱和拆箱是为了方便基本类型和包装类互相转换。如下所示,字面量12是int基本类型的,当赋值给包装类Integer对象时,便会触发自动装箱操作,创建一个Integer类型的对象,然后赋值给变量iobj。实际上,自动装箱其底层相当于执行了Integer类的valueof()方法。反过来,当把包装类对象iobj赋值给基本类型变量i时,便会触发自动拆箱操作,将iobj中的数据取出,然后赋值给变量i。自动拆箱底层相当于执行了Integer类的intValue()方法。
Integer iobj = 12; 底层实现为:Integer iobj = Integer.valueof(12);
int i = iobj; 底层实现为:int i = iobj.intValue();
for-each遍历也叫做增强for循环,底层依赖迭代器来实现。如下代码所示。
List<String> arr = Arrays.asList("xiao", "zheng", "ge");
// for-each循环遍历等价于下面的迭代器遍历
for (String s : arr) {
System.out.println(s);
}
// 迭代器遍历
Iterator<String> itr = arr.iterator();
while (itr.hasNext()) {
System.out.println(itr.next());
}
内部类也是一种语法糖。当编译成字节码之后,外部类编译为A.class,内部类编译为A$B.class,匿名内部类编译为A$1.class,均为独立的类。
public class A { // A.class
public class B {} //内部类->A$B.class
public void f() {
Thread t1 = new Thread(new Runnable() { //匿名内部类->A$1.class
@Override
public void run() {
System.out.println("I am in anonymous inner class.");
}
});
}
}
二、类加载
在Java应用程序执行的过程中,类的字节码是按需加载到内存中的。当第一次创建某个类的对象,或者调用某个类的方法时,这个类就会被加载到内存中,之后便一直保存在内存中。类加载的过程又可以细分为验证、准备、解析、初始化等几个步骤,并且,类的加载遵从双亲委派规则,不同的类由不同的classLoader加载器来加载。对于类加载的详细介绍,我们留在后面的章节中进行。
我们拿以下代码举例来看下,类的字节码格式。
public class Demo {
private String greeting= "hello";
public String greet(String name) {
return greeting;
}
}
我们将上述Demo类,经过javac编译器编译为Demo.class文件之后,再利用javap工具对Demo.class进行反编译,得到的结果如下所示。

在以上字节码结构中,方法表中存储的是各个函数的字节码,字段表中存储的是类的成员变量信息。这两个部分以及前面的魔数、版本号、访问标志、类、父类、接口信息等都很好理解。唯一比较复杂的就是常量池。常量池中包含的内容非常多,主要分为两类:字面量和符号引用。上述代码中的“hello”便是字符串字面量。而符号引用是编译原理中的概念,包括这个类所涉及到的类、接口、方法、成员变量的名称和描述符。当在执行代码时,虚拟机需要根据符号引用,找到所引用的类、接口、方法等的真实内存存储地址,然后跳转执行。
三、解释执行
对于C/C++这样的编译型语言,代码会事先被编译成机器指令(可执行文件),然后再一股脑儿交给CPU来执行。在执行时,CPU面对是已经编译好的机器指令,直接逐条执行即可。而对于Java语言来说,经过前端编译之后的.class文件,加载到内存之后,仍然为字节码格式,无法被CPU直接执行。JVM虚拟机需要将字节码逐条取出,边解释为机器码,边交由CPU执行。
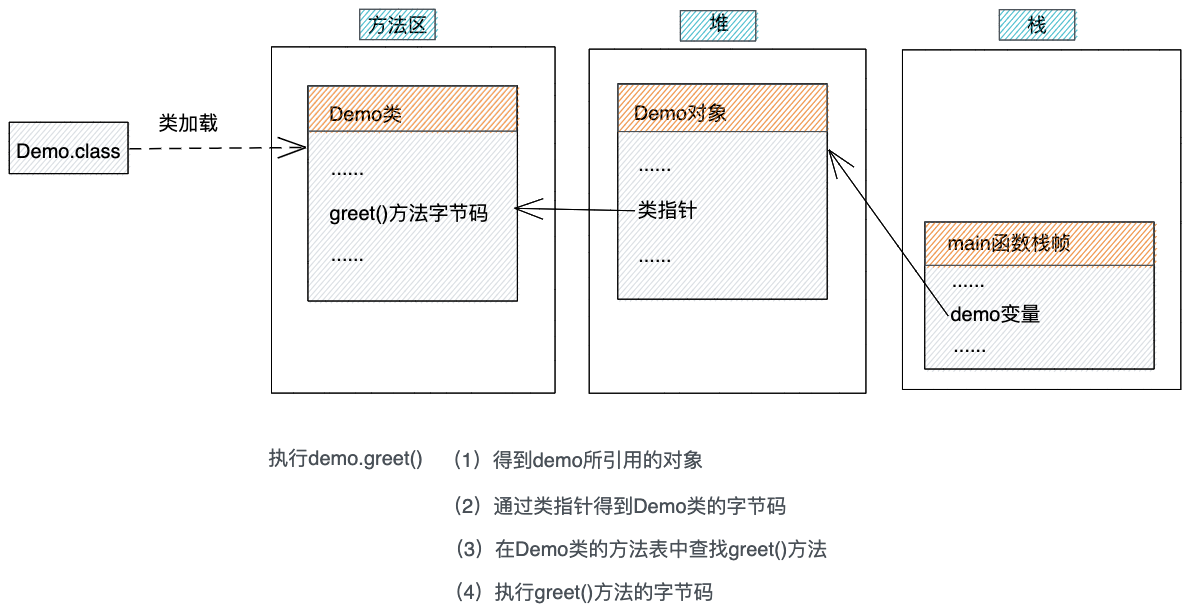
我们举个例子解释一下。如下代码所示。虚拟机从main()函数开始执行,当执行到Demo类对象的创建语句时,虚拟机发现内存中没有Demo类的字节码信息,于是,就通过类加载器在classpath对应的路径下查找Demo.class文件,并将其加载到内存中。之后,虚拟机根据类的字节码在堆中创建demo对象。当虚拟机执行demo.greet(“wangzheng”)方法时,虚拟机根据对象demo中的类指针(请参看第9节对象的内存结构),找到内存中的Demo类,然后在类的方法表中查找greet()函数对应的字节码,最后逐句解释执行。
public class App {
public static void main(String[] args) {
Demo demo = new Demo();
demo.greet("wangzheng");
}
}
上述执行流程,如下图所示。
四、JIT编译
解释执行需要在执行的过程中,将字节码解释为机器码,再行交由CPU执行。边解释边执行,显然会影响到程序的执行效率,这也是在Java语言发明之初,被认为执行效率没有编译型语言(比如C/C++)高的原因。随着Java语言的演进,为了解决解释执行的执行效率低的问题,Java引入了JIT(Just-in-Time)编译(也叫做即时编译或者运行时编译。),效率已经在很多场景下接近C++等编译型语言。
对于一些经常运行的热点代码,比如多次调用的方法或者多次执行的循环,JIT编译器在代码的运行过程中,将其编译为机器代码并存储下来,当下次执行这些热点代码时,虚拟机直接将对应的机器码交由CPU执行即可,不需要边解释边执行,执行效率匹敌编译型语言。
实际上,JIT编译器还可以在运行期收集代码的运行情况,在进行编译时针对性的做优化,生成更加高效的机器码,这种编译优化称为动态编译优化。而C/C++编译型语言的编译优化,只发生在运行前的编译时期,无法利用运行信息做优化,这种编译优化称为静态编译优化。这也是Java语言在性能上有可能超车C/C++编译型语言的地方。
默认情况下,虚拟机运行于混合模式,解释执行和JIT编译执行共存,当然,我们也可以使用-Xint JVM参数强制虚拟机运行于解释模式,仅支持解释执行,也可以使用-Xcomp强制虚拟机运行于编译模式,仅支持JIT编译执行。我们可以使用-version命令查看虚拟机的工作模式。如下所示。

五、AOT编译
实际上,跟JIT编译相对应的编译方法称作AOT编译(Ahead Of Time Compile),也叫做提前编译或者运行前编译。C/C++等编译型语言中的编译便是AOT编译,在运行前将代码编译成机器码。实际上,Java除了支持JIT编译之外,也支持AOT编译,只是相对来说用的不多而已。
不过,Java中的AOT编译跟C/C++等编译型语言中的编译有些许不同。Java AOT编译尽管不支持“一次编译,到处运行”,但仍然支持“一次编写,到处运行”,代码的可移植性完全由AOT编译器来负责。针对不同的操作系统,我们使用不同的AOT编译器,生成不同的机器码,而对于C/C++等编译型语言,代码的可移植性完全由程序员来负责,很难做到“一次编写,到处运行”。
接下来,我们再来思考这样一个问题:既然AOT编译可以在运行前将代码编译成机器码,为什么Java还执着于在运行的过程中执行JIT编译呢?
实际上,编译包含两部分内容,一部分是基本的编译操作,把代码编译成字节码、机器码等,另一部分是编译优化。AOT编译中进行的编译优化为静态编译优化,JIT编译中进行的编译优化为动态编译优化。相比静态编译优化,动态编译优化有很多优势,可以基于运行时的统计信息,进行一些比较激进的优化,比如根据运行时的统计信息,直接移除执行概率比较小的代码分支,如果在实际的运行中,万一需要执行被移除的代码分支,虚拟机会退回到使用原始的中间码来解释执行。只要退回解释执行的概率足够低,这种激进优化就是值得的,带来的性能提升就是非常可观的。而这种激进优化进行的前提是依据运行时的统计信息,因此,静态编译优化是无法进行的。这就是Java执着于JIT编译而非AOT编译的原因。
不过,JIT编译相对于AOT编译有一定的优势,并不代表使用JIT编译的Java语言的性能就比使用AOT编译的C++语言的性能好。毕竟,这种编译优化的优势在实际的应用过程中并不是特别明显。而且,编程语言之间的性能,除了受编译优化的影响之外,还有其他很多影响因素,比如内存布局、内存访问、内存管理等。
六、课后思考题
除了本节讲到的语法糖,你还知道有哪些语法糖?底层都是依赖哪些基本语法实现的?